The PHREG Procedure
- Overview
-
Getting Started

-
SyntaxPROC PHREG StatementASSESS StatementBASELINE StatementBAYES StatementBY StatementCLASS StatementCONTRAST StatementEFFECT StatementESTIMATE StatementFREQ StatementHAZARDRATIO StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementProgramming StatementsRANDOM StatementSTRATA StatementSLICE StatementSTORE StatementTEST StatementWEIGHT Statement
-
DetailsFailure Time DistributionTime and CLASS Variables UsagePartial Likelihood Function for the Cox ModelCounting Process Style of InputLeft-Truncation of Failure TimesThe Multiplicative Hazards ModelProportional Rates/Means Models for Recurrent EventsThe Frailty ModelProportional Subdistribution Hazards Model for Competing-Risks DataHazard RatiosNewton-Raphson MethodFirth’s Modification for Maximum Likelihood EstimationRobust Sandwich Variance EstimateTesting the Global Null HypothesisType 3 Tests and Joint TestsConfidence Limits for a Hazard RatioUsing the TEST Statement to Test Linear HypothesesAnalysis of Multivariate Failure Time DataModel Fit StatisticsSchemper-Henderson Predictive MeasureResidualsDiagnostics Based on Weighted ResidualsInfluence of Observations on Overall Fit of the ModelSurvivor Function EstimatorsCaution about Using Survival Data with Left TruncationEffect Selection MethodsAssessment of the Proportional Hazards ModelThe Penalized Partial Likelihood Approach for Fitting Frailty ModelsSpecifics for Bayesian AnalysisComputational ResourcesInput and Output Data SetsDisplayed OutputODS Table NamesODS Graphics
-
ExamplesStepwise RegressionBest Subset SelectionModeling with Categorical PredictorsFirth’s Correction for Monotone LikelihoodConditional Logistic Regression for m:n MatchingModel Using Time-Dependent Explanatory VariablesTime-Dependent Repeated Measurements of a CovariateSurvival CurvesAnalysis of ResidualsAnalysis of Recurrent Events DataAnalysis of Clustered DataModel Assessment Using Cumulative Sums of Martingale ResidualsBayesian Analysis of the Cox ModelBayesian Analysis of Piecewise Exponential ModelAnalysis of Competing-Risks Data
- References
Firth’s Modification for Maximum Likelihood Estimation
In fitting a Cox model, the phenomenon of monotone likelihood is observed if the likelihood converges to a finite value while at least one parameter diverges (Heinze and Schemper 2001).
Let 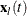 denote the vector explanatory variables for the lth individual at time t. Let
denote the vector explanatory variables for the lth individual at time t. Let 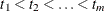 denote the k distinct, ordered event times. Let
denote the k distinct, ordered event times. Let 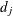 denote the multiplicity of failures at
denote the multiplicity of failures at 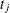 ; that is,
; that is, 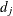 is the size of the set
is the size of the set 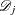 of individuals that fail at . Let
of individuals that fail at . Let 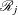 denote the risk set just before . Let
denote the risk set just before . Let 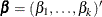 be the vector of regression parameters. The Breslow log partial likelihood is given by
be the vector of regression parameters. The Breslow log partial likelihood is given by
![\[ l(\bbeta ) = \log L(\bbeta ) = \sum _{j=1}^ m \biggl \{ \bbeta ’ \sum _{l\in \mc{D}_ j}\mb{x}_ l(t_ j) - d_ j \log \sum _{h \in \mc{R}j} \mr{e}^{\bbeta '\mb{x}_ h(t_ j)} \biggr \} \]](images/statug_phreg0417.png)
Denote
![\[ \mb{S}_ j^{(a)}(\bbeta ) = \sum _{h \in \mc{R}j} \mr{e}^{\bbeta '\mb{x}_ h(t_ j)} [\mb{x}_ h(t_ j)]^{\otimes a} \hspace{1cm} a=0,1,2 \]](images/statug_phreg0418.png)
Then the score function is given by
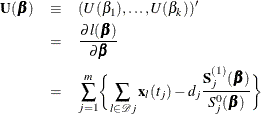
and the Fisher information matrix is given by
![\begin{eqnarray*} \mc{I}(\bbeta ) & =& - \frac{\partial ^2 l(\bbeta )}{\partial \bbeta ^2}\\ & =& \sum _{j=1}^ m d_ j \biggl \{ \frac{\mb{S}_ j^{(2)}(\bbeta )}{S_ j^{(0)}(\bbeta )} - \biggl [ \frac{\bS _ j^{(1)}(\bbeta )}{\mb{S}_ j^{(0)}(\bbeta )} \biggr ] \biggl [ \frac{\mb{S}_ j^{(1)}(\bbeta )}{\mb{S}_ j^{(0)}(\bbeta )} \biggr ]’ \biggr \} \end{eqnarray*}](images/statug_phreg0420.png)
Heinze (1999); Heinze and Schemper (2001) applied the idea of Firth (1993) by maximizing the penalized partial likelihood
![\[ l^*(\bbeta ) = l(\bbeta ) + 0.5 \log (|\mc{I}(\bbeta )|) \]](images/statug_phreg0421.png)
The score function 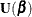 is replaced by the modified score function by
is replaced by the modified score function by 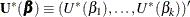 , where
, where
![\[ U^*(\beta _ r) = U(\beta _ r) + 0.5 \mr{tr} \biggl \{ \mc{I}^{-1}(\bbeta ) \frac{\partial \mc{I}(\bbeta )}{\partial \beta _ r} \biggr \} \hspace{1cm} r=1,\ldots ,k \]](images/statug_phreg0424.png)
The Firth estimate is obtained iteratively as
![\[ \bbeta ^{(s+1)} = \bbeta ^{(s)} + \mc{I}^{-1}(\bbeta ^{(s)})\mb{U}^*(\bbeta ^{(s)}) \]](images/statug_phreg0425.png)
The covariance matrix 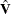 is computed as
is computed as 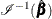 , where
, where 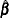 is the maximum penalized partial likelihood estimate.
is the maximum penalized partial likelihood estimate.
Explicit formulae for 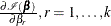
Denote
![\begin{eqnarray*} \mb{x}_ h(t) & =& (x_{h1}(t), \ldots , x_{hk}(t))’ \\ \mb{Q}_{jr}^{(a)}(\bbeta ) & =& \sum _{h \in \mc{R}j} \mr{e}^{\bbeta '\mb{x}_ h(t_ j)} x_{hr}(t_ j) [\mb{x}_ h(t_ j)]^{\otimes a} \hspace{1cm} a=0,1,2; r=1,\ldots ,k \end{eqnarray*}](images/statug_phreg0429.png)
Then
![\begin{eqnarray*} \frac{\partial \mc{I}(\bbeta )}{\partial \beta _ r} & =& \sum _{j=1}^ m d_ j \biggl \{ \biggl [ \frac{\mb{Q}_{jr}^{(2)}(\bbeta )}{S_ j^{(0)}(\bbeta )} - \frac{\mb{Q}_{jr}^{(0)}(\bbeta )}{S_ j^{(0)}(\bbeta )} \frac{\mb{S}_{j}^{(2)}(\bbeta )}{S_ j^{(0)}(\bbeta )} \biggl ] - \\ & & \biggl [ \frac{\mb{Q}_{jr}^{(1)}(\bbeta )}{S_ j^{(0)}(\bbeta )} - \frac{\mb{Q}_{jr}^{(0)}(\bbeta )}{S_ j^{(0)}(\bbeta )} \frac{\mb{S}_{j}^{(1)}(\bbeta )}{S_ j^{(0)}(\bbeta )} \biggl ] \biggl [\frac{\mb{S}_{j}^{(1)}(\bbeta )}{S_ j^{(0)}(\bbeta )} \biggl ]’ -\\ & & \biggl [\frac{\mb{S}_{j}^{(1)}(\bbeta )}{S_ j^{(0)}(\bbeta )} \biggl ] \biggl [ \frac{\mb{Q}_{jr}^{(1)}(\bbeta )}{S_ j^{(0)}(\bbeta )} - \frac{\mb{Q}_{jr}^{(0)}(\bbeta )}{S_ j^{(0)}(\bbeta )} \frac{\mb{S}_{j}^{(1)}(\bbeta )}{S_ j^{(0)}(\bbeta )} \biggl ]’ \biggr \} \hspace{1cm} r=1,\ldots ,k \end{eqnarray*}](images/statug_phreg0430.png)