The PHREG Procedure
- Overview
-
Getting Started

-
SyntaxPROC PHREG StatementASSESS StatementBASELINE StatementBAYES StatementBY StatementCLASS StatementCONTRAST StatementEFFECT StatementESTIMATE StatementFREQ StatementHAZARDRATIO StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementProgramming StatementsRANDOM StatementSTRATA StatementSLICE StatementSTORE StatementTEST StatementWEIGHT Statement
-
DetailsFailure Time DistributionTime and CLASS Variables UsagePartial Likelihood Function for the Cox ModelCounting Process Style of InputLeft-Truncation of Failure TimesThe Multiplicative Hazards ModelProportional Rates/Means Models for Recurrent EventsThe Frailty ModelProportional Subdistribution Hazards Model for Competing-Risks DataHazard RatiosNewton-Raphson MethodFirth’s Modification for Maximum Likelihood EstimationRobust Sandwich Variance EstimateTesting the Global Null HypothesisType 3 Tests and Joint TestsConfidence Limits for a Hazard RatioUsing the TEST Statement to Test Linear HypothesesAnalysis of Multivariate Failure Time DataModel Fit StatisticsSchemper-Henderson Predictive MeasureResidualsDiagnostics Based on Weighted ResidualsInfluence of Observations on Overall Fit of the ModelSurvivor Function EstimatorsCaution about Using Survival Data with Left TruncationEffect Selection MethodsAssessment of the Proportional Hazards ModelThe Penalized Partial Likelihood Approach for Fitting Frailty ModelsSpecifics for Bayesian AnalysisComputational ResourcesInput and Output Data SetsDisplayed OutputODS Table NamesODS Graphics
-
ExamplesStepwise RegressionBest Subset SelectionModeling with Categorical PredictorsFirth’s Correction for Monotone LikelihoodConditional Logistic Regression for m:n MatchingModel Using Time-Dependent Explanatory VariablesTime-Dependent Repeated Measurements of a CovariateSurvival CurvesAnalysis of ResidualsAnalysis of Recurrent Events DataAnalysis of Clustered DataModel Assessment Using Cumulative Sums of Martingale ResidualsBayesian Analysis of the Cox ModelBayesian Analysis of Piecewise Exponential ModelAnalysis of Competing-Risks Data
- References
Counting Process Style of Input
In the counting process formulation, data for each subject are identified by a triple 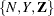 of counting, at-risk, and covariate processes. Here,
of counting, at-risk, and covariate processes. Here, 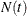 indicates the number of events that the subject experiences over the time interval
indicates the number of events that the subject experiences over the time interval ![$(0,t]$](images/statug_phreg0221.png) ;
; 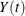 indicates whether the subject is at risk at time t (one if at risk and zero otherwise); and
indicates whether the subject is at risk at time t (one if at risk and zero otherwise); and 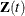 is a vector of explanatory variables for the subject at time t. The sample path of N is a step function with jumps of size +1 at the event times, and
is a vector of explanatory variables for the subject at time t. The sample path of N is a step function with jumps of size +1 at the event times, and 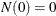 . Unless
. Unless 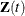 changes continuously with time, the data for each subject can be represented by multiple observations, each identifying a
semiclosed time interval
changes continuously with time, the data for each subject can be represented by multiple observations, each identifying a
semiclosed time interval ![$(t_1, t_2]$](images/statug_phreg0226.png) , the values of the explanatory variables over that interval, and the event status at
, the values of the explanatory variables over that interval, and the event status at 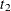 . The subject remains at risk during the interval , and an event might occur at . Values of the explanatory variables for the subject remain unchanged in the interval. This style of data input was originated
by Therneau (1994).
. The subject remains at risk during the interval , and an event might occur at . Values of the explanatory variables for the subject remain unchanged in the interval. This style of data input was originated
by Therneau (1994).
For example, a patient has a tumor recurrence at weeks 3, 10, and 15 and is followed up to week 23. Consider three fixed explanatory
variables Trt (treatment), Number (initial tumor number), and Size (initial tumor size), and one time-dependent covariate Z that represents a hormone level. The value of Z might change during the follow-up period. The data for this patient are represented
by the following four observations:
|
|
|
|
|
|
|
|
|---|---|---|---|---|---|---|
|
0 |
3 |
1 |
1 |
1 |
3 |
12.3 |
|
3 |
10 |
1 |
1 |
1 |
3 |
14.7 |
|
10 |
15 |
1 |
1 |
1 |
3 |
13.8 |
|
15 |
23 |
0 |
1 |
1 |
3 |
15.5 |
Here (T1,T2] contains the at-risk intervals. The variable Status indicates whether a recurrence has occurred at T2; a value of 1 indicates a tumor recurrence, and a value of 0 indicates nonrecurrence. The following statements fit a multiplicative
hazards model with baseline covariates Trt, Number, and Size, and a time-varying covariate Z.
proc phreg; model (T1,T2) * Status(0) = Trt Number Size Z; run;
Another useful application of the counting process formulation is delayed entry of subjects into the risk set. For example,
in studying the mortality of workers exposed to a carcinogen, the survival time is chosen to be the worker’s age at death
by malignant neoplasm. Any worker joining the workplace at a later age than a given event failure time is not included in
the corresponding risk set. The variables of a worker consist of Entry (age at which the worker entered the workplace), Age (age at death or age censored), Status (an indicator of whether the observation time is censored, with the value 0 identifying a censored time), and X1 and X2 (explanatory variables thought to be related to survival). The specification for such an application is as follows:
proc phreg; model (Entry, Age) * Status(0) = X1 X2; run;
Alternatively, you can use a time-dependent variable to control the risk set, as illustrated in the following specification:
proc phreg; model Age * Status(0) = X1 X2; if Age < Entry then X1= .; run;
Here, X1 becomes a time-dependent variable. At a given death time t, the value of X1 is reevaluated for each subject with Age 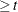 ; subjects with
; subjects with Entry 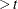 are given a missing value in
are given a missing value in X1 and are subsequently removed from the risk set. Computationally, this approach is not as efficient as the one that uses the
counting process formulation.