The MCMC Procedure
-
Overview

-
Getting Started
-
Syntax
-
Details
How PROC MCMC Works Blocking of Parameters Sampling Methods Tuning the Proposal Distribution Conjugate Sampling Initial Values of the Markov Chains Assignments of Parameters Standard Distributions Usage of Multivariate Distributions Specifying a New Distribution Using Density Functions in the Programming Statements Truncation and Censoring Some Useful SAS Functions Matrix Functions in PROC MCMC Create Design Matrix Modeling Joint Likelihood Regenerating Diagnostics Plots Caterpillar Plot Posterior Predictive Distribution Handling of Missing Data Floating Point Errors and Overflows Handling Error Messages Computational Resources Displayed Output ODS Table Names ODS Graphics
-
Examples
Simulating Samples From a Known Density Box-Cox Transformation Logistic Regression Model with a Diffuse Prior Logistic Regression Model with Jeffreys’ Prior Poisson Regression Nonlinear Poisson Regression Models Logistic Regression Random-Effects Model Nonlinear Poisson Regression Random-Effects Model Multivariate Normal Random-Effects Model Change Point Models Exponential and Weibull Survival Analysis Time Independent Cox Model Time Dependent Cox Model Piecewise Exponential Frailty Model Normal Regression with Interval Censoring Constrained Analysis Implement a New Sampling Algorithm Using a Transformation to Improve Mixing Gelman-Rubin Diagnostics
- References
| Truncation and Censoring |
Truncated Distributions
To specify a truncated distribution, you can use the LOWER= and/or UPPER= options. Almost all of the standard distributions, including the GENERAL and DGENERALfunctions, take these optional truncation arguments. The exceptions are the binary and uniform distributions.
For example, you can specify the following:
prior alpha ~ normal(mean = 0, sd = 1, lower = 3, upper = 45);
or
parms beta; a = 3; b = 7; ll = (a + 1) * log(b / beta); prior beta ~ general(ll, upper = b + 17);
The preceding statements state that if beta is less than b+17, the log of the prior density is ll, as calculated by the equation; otherwise, the log of the prior density is missing—the log of zero.
When the same distribution is applied to multiple parameters in a PRIOR statement, the LOWER= and UPPER= truncations apply to all parameters in that statement. For example, the following statements define a Poisson density for theta and gamma:
parms theta gamma; lambda = 7; l1 = theta * log(lambda) - lgamma(1 + theta); l2 = gamma * log(lambda) - lgamma(1 + gamma); ll = l1 + l2; prior theta gamma ~ dgeneral(ll, lower = 1);
The LOWER=1 condition is applied to both theta and gamma, meaning that for the assignment to ll to be meaningful, both theta and gamma have to be greater than 1. If either of the parameters is less than 1, the log of the joint prior density becomes a missing value.
With the exceptions of the normal distribution and the GENERAL and DGENERAL functions, the LOWER= and UPPER= options cannot be parameters or functions of parameters. The reason is that most of the truncated distributions are not normalized. Unnormalized densities do not lead to wrong MCMC answers as long as the bounds are constants. However if the bounds involve model parameters, then the normalizing constant, which is a function of these parameters, must be taken into account in the posterior. Without specifying the normalizing constant, inferences on these boundary parameters are incorrect.
It is not difficult to construct a truncated distribution with a normalizing constant. Any truncated distribution has the probability distribution:
 |
where 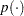 is the density function and
is the density function and 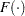 is the cumulative distribution function. In SAS functions, is probability density function and is cumulative distribution function. The following example shows how to construct a truncated gamma prior on theta, with SHAPE = 3, SCALE = 2, LOWER = a, and UPPER = b:
is the cumulative distribution function. In SAS functions, is probability density function and is cumulative distribution function. The following example shows how to construct a truncated gamma prior on theta, with SHAPE = 3, SCALE = 2, LOWER = a, and UPPER = b:
lp = logpdf('gamma', theta, 3, 2)
- log(cdf('gamma', a, 3, 2) - cdf('gamma', b, 3, 2));
prior theta ~ general(lp);
Note the difference from a naive definition of the density, without taking into account of the normalizing constant:
lp = logpdf('gamma', theta, 3, 2);
prior theta ~ general(lp, lower=a, upper=b);
If a or b are parameters, you get very different results from the two formulations.
Censoring
There is no built-in mechanism in PROC MCMC that models censoring automatically. You need to construct the density function (using a combination of the LOGPDF, LOGCDF, and LOGSDF functions and IF-ELSE statements) for the censored data.
Suppose that you partition the data into four categories: uncensored (with observation x), left censored (with observation xl), right censored (with observation xr), and interval censored (with observations xl and xr). The likelihood is the normal with mean mu and standard deviation s. The following statements construct the corresponding log likelihood for the observed data:
if uncensored then
ll = logpdf('normal', x, mu, s);
else if leftcensored then
ll = logcdf('normal', xl, mu, s);
else if rightcensored then
ll = logsdf('normal', xr, mu, s);
else /* this is the case of interval censored. */
ll = log(cdf('normal', xr, mu, s) - cdf('normal', xl, mu, s));
model general(ll);