The MCMC Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsHow PROC MCMC WorksBlocking of ParametersSampling MethodsTuning the Proposal DistributionDirect SamplingConjugate SamplingInitial Values of the Markov ChainsAssignments of ParametersStandard DistributionsUsage of Multivariate DistributionsSpecifying a New DistributionUsing Density Functions in the Programming StatementsTruncation and CensoringSome Useful SAS FunctionsMatrix Functions in PROC MCMCCreate Design MatrixModeling Joint LikelihoodAccess Lag and Lead VariablesCALL ODE and CALL QUAD SubroutinesRegenerating Diagnostics PlotsCaterpillar PlotAutocall Macros for PostprocessingGamma and Inverse-Gamma DistributionsPosterior Predictive DistributionHandling of Missing DataFunctions of Random-Effects ParametersFloating Point Errors and OverflowsHandling Error MessagesComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesSimulating Samples From a Known DensityBox-Cox TransformationLogistic Regression Model with a Diffuse PriorLogistic Regression Model with Jeffreys’ PriorPoisson RegressionNonlinear Poisson Regression ModelsLogistic Regression Random-Effects ModelNonlinear Poisson Regression Multilevel Random-Effects ModelMultivariate Normal Random-Effects ModelMissing at Random AnalysisNonignorably Missing Data (MNAR) AnalysisChange Point ModelsExponential and Weibull Survival AnalysisTime Independent Cox ModelTime Dependent Cox ModelPiecewise Exponential Frailty ModelNormal Regression with Interval CensoringConstrained AnalysisImplement a New Sampling AlgorithmUsing a Transformation to Improve MixingGelman-Rubin DiagnosticsOne-Compartment Model with Pharmacokinetic Data
- References
RANDOM Statement
-
RANDOM random-effect ~distribution SUBJECT=variable <options>;
The RANDOM statement defines a single random effect and its prior distribution or an array of random effects and their prior distribution. The random-effect must be represented by either a symbol or an array. The RANDOM statement must consist of the random-effect, a tilde (~), the distribution for the random effect, and then a SUBJECT= variable.
The random-effects parameters associated with each subject in the same RANDOM statement are assumed to be conditionally independent of each other, given other parameters and data set variables in the model. The other parameters include model parameters (declared in the PARMS statements), random-effects parameters (from other RANDOM statements), and missing data variables.
Table 73.4 shows the distributions that you can specify in the RANDOM statement.
Table 73.4: Valid Distributions in the RANDOM Statement
|
Distribution Name |
Definition |
|---|---|
|
beta
(<a=> |
Beta distribution with shape parameters |
|
binary (<prob|p=> p) |
Binary (Bernoulli) distribution with probability of success p. You can use the alias bern for this distribution. |
|
gamma
(<shape|sp=> a, scale|s= |
Gamma distribution with shape a and scale or inverse-scale |
|
dgeneral (ll) |
General log-prior function that you construct using SAS programming statements for univariate or multivariate discrete random effects. See the section Specifying a New Distribution for more details. |
|
general (ll) |
General log-prior function that you construct using SAS programming statements for univariate or multivariate continuous random effects. See the section Specifying a New Distribution for more details. |
|
igamma
(<shape|sp=> a, scale|s= |
Inverse-gamma distribution with shape a and scale or inverse-scale |
|
laplace
(<location|loc|l=> |
Laplace distribution with location |
|
normal
(<mean|m=> |
Normal (Gaussian) distribution with mean |
|
poisson
(<mean|m=> |
Poisson distribution with mean |
|
table
(<p=> p) |
Table (categorical) distribution with probability vector p. You can also use the alias cat for this distribution |
|
uniform (<left|l=> a, <right|r=> b) |
Uniform distribution with range a and b. You can use the alias unif for this distribution. |
|
MVN
(<mu=> |
Multivariate normal distribution with mean vector |
|
MVNAR
(<mu=> |
Multivariate normal distribution with mean vector |

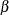
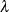
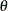
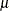
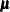
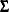
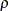
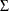
The following RANDOM statement specifies a scale effect, where s2u can be a constant or a model parameter and index is a data set variable that indicates group membership of the random effect u:
random u ~ normal(0,var=s2u) subject=index;
The following statements specify multidimensional effects, where mu and cov can be either parameters in the model or constant arrays:
array w[2]; array mu[2]; array cov[2,2]; random w ~ mvn(mu, cov) subject=index;
You can specify multiple RANDOM statements. Hyperparameters in the prior distribution of a random effect can be other random
effects in the model. For example, the following statements are allowed because the random effect g appears in the distribution for the random effect u:
random g ~ normal(0,var=s2g) subject=month; random u ~ normal(g,var=s2u) subject=day;
These two RANDOM statements specify a nested hierarchical model in which the random-effects g is the hyperparameter of the random-effects u. You can build the hierarchical structure as deep as you want. You can also use multiple RANDOM statements to build non-nested
random-effects models, where the effects could enter the model on different levels but not in the same hierarchy of each other.
The number of random-effects parameters in each RANDOM statement is determined by the number of unique values in the SUBJECT= variable, which can be either unsorted numeric or unsorted character literal. Unlike the model parameters that are explicitly declared in the PARMS statement (with therefore a fixed total number), the number of random-effects parameters in a program depends on the values of the SUBJECT= data set variable. That number can change from one BY group to another.
The order of the RANDOM statements, or their relative placement with respect to other statements in the program (such as the
PRIOR
statement or the MODEL
statement), is not important. The programming order becomes relevant if any hyperparameters are defined variables in the
program. For example, in the following statements, the hyperparameter s is defined as a function of some variable or parameter in the model:
s = sqrt(s2g); random g ~ normal(0,sd=s) subject=month;
That definition of s must appear before the RANDOM statement that requires it. If you switched the order of the statements as follows, PROC MCMC
would not be able to calculate the prior density for some subjects correctly and would produce erroneous results.
random g ~ normal(0,sd=s) subject=month; s = sqrt(s2g);
The names of the random-effects parameters are created internally. See the NAMESUFFIX= option for the naming convention of the random-effects parameters. The random-effects parameters are updated conditionally in the simulation. All posterior draws are saved to the OUTPOST= output data set by default, and you can use the MONITOR= option to monitor any of the parameters. For more information about available sampling algorithms, see the ALGORITHM= option. For more information about how to set a random-effects parameter to a constant (also known as corner-point constraint), see the CONSTRAINT option.
You can specify the following options in the RANDOM statement:
-
ALGORITHM=option
ALG=option -
specifies the algorithm to use to sample the posterior distribution. The following options are available:
When possible, PROC MCMC samples directly from the full conditional distribution. Otherwise, the default sampling algorithm is the RWM.
-
CONSTRAINT(VALUE=value) = FIRST | LAST | NONE | ’formatted-value’
ZERO=FIRST | LAST | NONE | ’formatted-value’ -
sets one of the random-effects parameters to a fixed value. The default is ZERO=NONE, which does not fix any of the parameters to be a constant. This option enables you to eliminate one of the parameters.
For example, this option could be useful if you want to fit a regression model with categorical covariates and, instead of creating a design matrix, you treat the parameters as “random effects” and fit an equivalent random-effects model.
Suppose you have a regression that includes a categorical variable X with J levels. You can construct a full-rank design matrix with J–1 dummy variables (
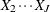 with
with 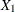 being the base group) and fit a regression such as the following:
being the base group) and fit a regression such as the following:
![\[ \mu _ i = \beta _0 + \beta _2 \cdot X_2 \cdots \beta _ J \cdot X_ J \]](images/statug_mcmc0105.png)
The following statements in a PROC MCMC step fit such a hypothetical regression model:
parms beta0 betax2 ... betaxJ; prior beta: ~ n(0, sd=100); mu = beta0 + betax2 * x2 + ... betaxJ * xJ; ...
Equivalently, you can also treat this model as a random-effects model such as the following, where
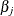 are random effects for each category in X:
are random effects for each category in X:
![\[ \mu _ i = \beta _0 + \beta _ j \mbox{ for } j = 1, \ldots , J \]](images/statug_mcmc0107.png)
However, this random-effects model is over-parameterized. The ZERO= option rids the model with one random-effects parameter of choice and fixes it to be zero. The following example statements fit such a hypothetical random-effects model:
parms beta0; prior beta0 ~ n(0, sd=100); random beta ~ n(0, sd=100) subject=x zero=first; mu = beta0 + beta; ...
The specification ZERO=FIRST sets the first random-effects parameter to 0, implying
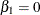 . This random-effects parameter corresponds to the first category in the SUBJECT=
variable. The category is what the first observation of the SUBJECT=
variable takes.
. This random-effects parameter corresponds to the first category in the SUBJECT=
variable. The category is what the first observation of the SUBJECT=
variable takes.
The specification ZERO=LAST sets the last random-effects parameter to be 0, implying
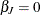 . This random-effects parameter corresponds to the last category in the SUBJECT=
variable. The category is not necessarily the same category that the last observation of the SUBJECT=
variable takes because the SUBJECT=
variable does not need to be sorted.
. This random-effects parameter corresponds to the last category in the SUBJECT=
variable. The category is not necessarily the same category that the last observation of the SUBJECT=
variable takes because the SUBJECT=
variable does not need to be sorted.
The specification ZERO='formatted-value' sets the random-effects parameter for the category (in the SUBJECT= variable) with a formatted value that matches 'formatted-value' to 0. For example, ZERO='3' sets
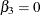 .
.
The CONSTRAINT(VALUE=value) option works similarly to the ZERO= option. You can assign an arbitrary value to any one of the random-effects parameter. For example, the specification CONSTRAINT(VALUE=0)=FIRST is equivalent to ZERO=FIRST.
-
ICOND=variable-list | numeric-list
ISTATES=variable-list | numeric-list -
specifies the initial conditions (or initial states) of the lag or lead variable of the random effect when the subject indices are out of the range of the subjects. (For more information about rules of constructing lag and lead variables in PROC MCMC, see the section Access Lag and Lead Variables.) This works similarly to the ICOND= option in the MODEL statement, except that the index is done according to a subject variable, not observations. The initial conditions can be model parameters, functions of model parameters, or constants. By default, numeric-list is set to 0.
The ICOND= option in a RANDOM statement sets the initial conditions for all lag or lead variables (of the associated random effect) that appear in the program, not just those that appear in the RANDOM statement. Suppose you have a maximum L number of lag variables and a maximum M number of lead variables of the random effect
muin the program, and there are n clusters. The program has the following vector of variables that need to be resolved during simulation: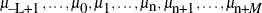
Of these variables, n (
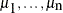 ) are random-effects parameters and the remaining L+M are initial conditions that are specified in the ICOND= option. The variable-list (or the number-list) should be a vector of length L+M, which can be greater than the number of lag/lead random-effect variables that appear in a program. If you provide a partial
list that contains fewer than L+M states, PROC MCMC fills the remaining vector with the value of 0.
) are random-effects parameters and the remaining L+M are initial conditions that are specified in the ICOND= option. The variable-list (or the number-list) should be a vector of length L+M, which can be greater than the number of lag/lead random-effect variables that appear in a program. If you provide a partial
list that contains fewer than L+M states, PROC MCMC fills the remaining vector with the value of 0.
- INITIAL=SAS-data-set | constant | numeric-list
-
specifies the initial values of the random-effects parameters. By default, PROC MCMC uses the same option as specified in the INIT= option to generate initial values for the random-effects parameter: either it uses the mode of the prior density or it randomly draws a sample from that distribution. You can start the Markov chain at different places by providing a SAS-data-set, a constant, or a numeric-list for multivariate random-effects parameters.
If you use a SAS-data-set, the data set must consist of variable names that agree with the random-effects parameters in the model (see the NAMESUFFIX= option for the naming convention of the random-effects parameters). The easiest way to find the names of the internally created parameter names is to run a default analysis with a very small number of simulations and check the variable names in the OUTPOST= data set. You can provide a subset of the initial values in the SAS-data-set and PROC MCMC will use the default mechanism to fill in the rest of the random-effects parameters.
For example, the following statement creates a data set with initial values for the random-effects parameters
u_1,u_2, andu_3:data RandomInit; input u_1 u_2 u_3; datalines; 2.3 3 -3 ;
The following RANDOM statement takes the values in the
RandomInitdata set to be the initial values of the corresponding random-effects parameters in the model:random u ~ normal(0,var=s2u) subject=index init=randominit;
Specifying a constant assigns that constant as the initial value to all random-effects parameters in the statement. For example, the following statement assigns the value 5 to be used as an initial value for all
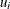 in the model:
in the model:
random u ~ normal(0,var=s2u) subject=index init=5;
If you have multiple effects, you can provide a list of numbers, where the length of the list the same as the dimension of your random-effects array. Each number is then given to all corresponding random-effects parameters in order. For example, the following statement assigns the value 2 to be used as an initial value for all
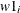 and the value 3 to be used for all
and the value 3 to be used for all 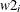 in the model:
in the model:
array w[2] w1 w2; random w ~ mvn(mu, cov) subject=index init=(2 3);
If you use the GENERAL or DGENERAL functions in the RANDOM statement, you must provide initial values for these parameters.
- MONITOR= (symbol-list | number-list | RANDOM(number))
-
outputs analysis for selected random-effects parameters. You can choose to monitor the random-effects parameters by listing the effect names or effect indices, or you can have them randomly selected by PROC MCMC.
To monitor all random-effects parameters, you specify the effect name in the MONITOR= option:
random u ~ normal(0,var=s2u) subject=index monitor=(u);
You have three options for monitoring a subset of the random-effects parameters. You can provide a list of the parameter names, you can provide a number list of the parameter indices, or you can have PROC MCMC randomly choose a subset of parameters for you.
For example, if you want to monitor analysis for parameters
u_1throughu_10,u_23, andu_57, you can provide the names as follows:random u ~ normal(0,var=s2u) subject=index monitor=(u_1-u_10 u_23 u_57);
The naming convention in the symbol-list must agree with the NAMESUFFIX= option, which controls how the parameter names of the random-effect are created. By default, NAMESUFFIX=SUBJECT, and the symbol-list must use suffixes that correspond to the formatted values[31] in the SUBJECT= data set variable. With the NAMESUFFIX=POSITION option, the symbol-list must use suffixes that agree with the input order of the SUBJECT= variable. If the SUBJECT= variable has a character value, you cannot use the hyphen (-) in the symbol-list to indicate a range of variables.
To monitor the same list of random-effects parameters, you can provide their indices:
random u ~ normal(0,var=s2u) subject=index monitor=(1 to 10 by 1 23 57);
PROC MCMC can also randomly choose a subset of the parameters to monitor:
random u ~ normal(0,var=s2u) subject=index monitor=(random(12));
The sequence of the random indices is controlled by the SEED= option in the PROC MCMC statement.
By default, PROC MCMC does not monitor any random-effects parameters. When you specify this option, it takes the specification of the STATISTICS= and PLOTS= options in the PROC MCMC statement. By default, PROC MCMC outputs all the posterior samples of all random-effects parameters to the OUTPOST= output data set. You can use the NOOUTPOST option to suppress the saving of the random-effects parameters.
- NAMESUFFIX=option
-
specifies how the names of the random-effects parameters are internally created from the SUBJECT= variable that is specified in the RANDOM statement. PROC MCMC creates the names by concatenating the random-effect symbol with an underscore and a series of numbers or characters. The following options control the type of methods that are used in such construction:
For example, suppose you have an input data set with four observations and the SUBJECT= variable
zipcodehas four values (with three of them unique): 27513, 01440, 27513, and 15217. The following SAS statement creates three random-effects parameters namedu_27513,u_01440, andu_15217:random u ~ normal(0,var=10) subject=zipcode namesuffix=subject;
On the other hand, using NAMESUFFIX=POSITION creates three parameters named as
u_1,u_2, andu_3:random u ~ normal(0,var=10) subject=zipcode namesuffix=position;
By default, NAMESUFFIX=SUBJECT.
- NOOUTPOST
-
suppresses the output of the posterior samples of random-effects parameters to the OUTPOST= data set. In models with a large number of random-effects parameters (for example, tens of thousands), PROC MCMC can run faster if it does not save the posterior samples of the random-effects parameters.
When you specify both the NOOUTPOST option and the MONITOR= option, PROC MCMC outputs the list of variables that are monitored.
The maximum number of variables that can be saved to an OUTPOST= data set is 32,767. If you run a large-scale random-effects model with the number of parameters exceeding the limit, the NOOUTPOST option is evoked automatically and PROC MCMC does not save the random-effects parameter draws to the posterior output data set. You can use the MONITOR= option to select a subset of the parameters to store in the OUTPOST= data set.