The MCMC Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsHow PROC MCMC WorksBlocking of ParametersSampling MethodsTuning the Proposal DistributionDirect SamplingConjugate SamplingInitial Values of the Markov ChainsAssignments of ParametersStandard DistributionsUsage of Multivariate DistributionsSpecifying a New DistributionUsing Density Functions in the Programming StatementsTruncation and CensoringSome Useful SAS FunctionsMatrix Functions in PROC MCMCCreate Design MatrixModeling Joint LikelihoodAccess Lag and Lead VariablesCALL ODE and CALL QUAD SubroutinesRegenerating Diagnostics PlotsCaterpillar PlotAutocall Macros for PostprocessingGamma and Inverse-Gamma DistributionsPosterior Predictive DistributionHandling of Missing DataFunctions of Random-Effects ParametersFloating Point Errors and OverflowsHandling Error MessagesComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesSimulating Samples From a Known DensityBox-Cox TransformationLogistic Regression Model with a Diffuse PriorLogistic Regression Model with Jeffreys’ PriorPoisson RegressionNonlinear Poisson Regression ModelsLogistic Regression Random-Effects ModelNonlinear Poisson Regression Multilevel Random-Effects ModelMultivariate Normal Random-Effects ModelMissing at Random AnalysisNonignorably Missing Data (MNAR) AnalysisChange Point ModelsExponential and Weibull Survival AnalysisTime Independent Cox ModelTime Dependent Cox ModelPiecewise Exponential Frailty ModelNormal Regression with Interval CensoringConstrained AnalysisImplement a New Sampling AlgorithmUsing a Transformation to Improve MixingGelman-Rubin DiagnosticsOne-Compartment Model with Pharmacokinetic Data
- References
Handling of Missing Data
PROC MCMC automatically augments missing values[35] via the use of the MODEL statement. PROC MCMC treats missing values as unknown parameters, assigns distributions to the variables, and incorporates the sampling of the missing data as part of Markov chain.
(In SAS/STAT 9.3 and earlier releases, by default, PROC MCMC discarded all observations that had missing or partial missing values. PROC MCMC could not model missing values.)
You can use the MISSING= option in the PROC MCMC statement to specify how you want PROC MCMC to handle the missing values. If you specify MISSING=CC (CC stands for complete cases), PROC MCMC discards all observations that have missing or partial missing values before carrying out the simulation. If you specify MISSING=AC (AC stands for all cases), PROC MCMC neither discards any missing values nor augments them.
Generally speaking, there are three types of missing data models, as discussed by Rubin (1976). Also see Little and Rubin (2002) for a comprehensive treatment of missing data analysis. The rest of this section provides an overview of these three types of missing data models and explains how to use PROC MCMC to fit them.
Missing Completely at Random (MCAR)
Data are said to be MCAR if the probability of a missing value (or the failure of observing a value) does not depend on any
other observations in the data set, regardless of whether they are observed or missing. That is, the observed and unobserved
values are independent of each other: if 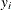 is missing, it is MCAR if the probability of observing is independent of other
is missing, it is MCAR if the probability of observing is independent of other 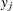 (and other covariates
(and other covariates 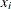 ) in the data set. Under this assumption, both the observed and unobserved data are random samples of all the data; hence,
fitting a model based only on the observed data does not introduce any biases. This type of analysis is called a complete-case
analysis. To carry out a complete-case analysis, you must specify MISSING=CC
in the PROC MCMC statement. (In SAS/STAT 9.3 and earlier, PROC MCMC performed a complete-case analysis when the data contained
missing values.)
) in the data set. Under this assumption, both the observed and unobserved data are random samples of all the data; hence,
fitting a model based only on the observed data does not introduce any biases. This type of analysis is called a complete-case
analysis. To carry out a complete-case analysis, you must specify MISSING=CC
in the PROC MCMC statement. (In SAS/STAT 9.3 and earlier, PROC MCMC performed a complete-case analysis when the data contained
missing values.)
Missing at Random (MAR)
Data are said to be MAR if the probability of a missing value can depend on some observed quantities but does not depend on
any unobserved data. For example, suppose that are completely observed for all observations and some are missing. MAR states that the probability of observing is independent of other missing (values that could have been observed) and that it depends only on (and, potentially, observed ).
The MAR assumption states that the missing are no longer random samples and that they need to be modeled (via the likelihood specification of the missing values). At
the same time, the independence assumption of the missing values on the unobserved quantities states that the missing mechanism
(usually an binary indicator variable such that 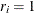 if is missing and
if is missing and 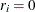 otherwise) can be ignored and does not need to be taken into account. Hence, MAR is sometimes referred to as ignorably missing. It is not the missing values that can be ignored, it is the missing mechanism that can be ignored.
otherwise) can be ignored and does not need to be taken into account. Hence, MAR is sometimes referred to as ignorably missing. It is not the missing values that can be ignored, it is the missing mechanism that can be ignored.
By default, PROC MCMC treats the missing data as MAR (this assumes that you do not input a binary indicator variable  and model it specifically): each missing value becomes an extra parameter and PROC MCMC updates it in every iteration. PROC
MCMC assumes that both the missing values and observed values arise from the same distribution (which is specified in the
MODEL
statement),
and model it specifically): each missing value becomes an extra parameter and PROC MCMC updates it in every iteration. PROC
MCMC assumes that both the missing values and observed values arise from the same distribution (which is specified in the
MODEL
statement),
![\[ \mb{y} = \left\{ \mb{y}_{\mb{obs}}, \mb{y}_{\mb{mis}} \right\} \sim f(\mb{y} | \theta ) \]](images/statug_mcmc0584.png)
where 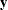 consists of observed (
consists of observed (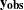 ) and missing (
) and missing (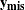 ) values, and
) values, and 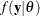 is the likelihood function with parameters
is the likelihood function with parameters 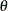 .
.
You can use the MODEL
statement to model missing covariates. Using multiple MODEL
statements enables you to specify, for example, a marginal distribution for missing values in covariate x and a conditional distribution for the response variable y given x as follows:
model x ~ normal(alpha, var=s2_x); model y ~ normal(beta * x, var=s2_y);
In each iteration, PROC MCMC draws samples for every missing value in variable x, then every missing value in variable y, conditional on the drawn values of the x variable.
Missing Not at Random (MNAR)
Data are said to be MNAR if the probability of a missing value depends on unobserved data (or data that could have been observed):
the probability that is missing depends on the missing values of other . This is a very general scenario that assumes that the missing mechanism is no longer ignorable (it is sometimes referred
to as nonignorably missing) and that a model for the missing mechanism is required in order to make correct inferences about the model parameters.
Let 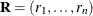 be the missing value indicator for
be the missing value indicator for 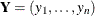 , where if is missing and otherwise. This
, where if is missing and otherwise. This 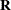 is usually part of an input data set where you preprocess the response variable and create this missing value indicator variable.
Modeling MNAR data implies that you must specify a joint likelihood function over
is usually part of an input data set where you preprocess the response variable and create this missing value indicator variable.
Modeling MNAR data implies that you must specify a joint likelihood function over 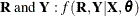 , where
, where 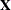 represents the covariates and
represents the covariates and 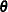 represents the model parameters. This joint distribution can be factored in two ways: a pattern-mixture model and a selection
model.
represents the model parameters. This joint distribution can be factored in two ways: a pattern-mixture model and a selection
model.
The selection model factors the joint distribution and 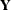 into a marginal distribution for and a conditional distribution for ,
into a marginal distribution for and a conditional distribution for ,
![\[ f(\mb{R}, \mb{Y} | \mb{X}, \bm {\theta }) \propto f(\mb{Y} | \mb{X}, \bm {\alpha }) \cdot f(\mb{R} | \mb{Y}, \mb{X}, \bm {\beta }) \]](images/statug_mcmc0591.png)
where 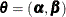 ,
, 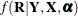 is usually a binary model with a logit or probit link that involves regression parameters
is usually a binary model with a logit or probit link that involves regression parameters  , and
, and 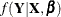 is the sampling distribution that generates with model parameters
is the sampling distribution that generates with model parameters 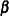 .
.
The pattern-mixture model factors the opposite way, a marginal distribution for and a conditional distribution for ,
![\[ f(\mb{R}, \mb{Y} | \mb{X}, \bm {\theta }) \propto f(\mb{R} | \mb{X}, \bm {\gamma }) \cdot f(\mb{Y} | \mb{R}, \mb{X}, \bm {\delta }) \]](images/statug_mcmc0596.png)
where 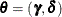 .
.
You can use PROC MCMC to fit either model by specifying multiple MODEL
statements: one for the marginal distribution and one for the conditional distribution. Suppose that the variable r is the missing data indicator, which is modeled using a logit model, and that the response variable y is a Poisson regression that includes the missing variable indicator as one of its covariates. The following statements are
a PROC MCMC program that fits a pattern-mixture model:
pi = logistic(alpha * x1); model r ~ binary(pi); mu = beta0 + beta1 * x2 + beta3 * r; model y ~ poisson(exp(mu));
The first MODEL
statement uses a binary model with logit link to model the missing mechanism, and the second MODEL
statement models the response variable with a Poisson regression that includes the missing value indicator as one of its
covariates. Each of the two sets of regression has its covariates and regression coefficients. If this hypothetical data set
contained missing values in covariates x1 and x2, you could add two more MODEL
statements to handle each variable as follows:
model x1 ~ normal(mu1, var=s2_x1); pi = logistic(alpha * x1); model r ~ binary(pi); model x2 ~ normal(mu2, var=s2_x2); mu = beta0 + beta1 * x2 + beta3 * r; model y ~ poisson(exp(mu));
[35] A missing value is usually, although not necessarily, represented by a single period (.) in the input data set.