The GLIMMIX Procedure
-
Overview

-
Getting Started
-
SyntaxPROC GLIMMIX StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementCOVTEST StatementEFFECT StatementESTIMATE StatementFREQ StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementOUTPUT StatementPARMS StatementRANDOM StatementSLICE StatementSTORE StatementWEIGHT StatementProgramming StatementsUser-Defined Link or Variance Function
-
DetailsGeneralized Linear Models TheoryGeneralized Linear Mixed Models TheoryGLM Mode or GLMM ModeStatistical Inference for Covariance ParametersDegrees of Freedom MethodsEmpirical Covariance ("Sandwich") EstimatorsExploring and Comparing Covariance MatricesProcessing by SubjectsRadial Smoothing Based on Mixed ModelsOdds and Odds Ratio EstimationParameterization of Generalized Linear Mixed ModelsResponse-Level Ordering and ReferencingComparing the GLIMMIX and MIXED ProceduresSingly or Doubly Iterative FittingDefault Estimation TechniquesDefault OutputNotes on Output StatisticsODS Table NamesODS Graphics
-
ExamplesBinomial Counts in Randomized BlocksMating Experiment with Crossed Random EffectsSmoothing Disease Rates; Standardized Mortality RatiosQuasi-likelihood Estimation for Proportions with Unknown DistributionJoint Modeling of Binary and Count DataRadial Smoothing of Repeated Measures DataIsotonic Contrasts for Ordered AlternativesAdjusted Covariance Matrices of Fixed EffectsTesting Equality of Covariance and Correlation MatricesMultiple Trends Correspond to Multiple Extrema in Profile LikelihoodsMaximum Likelihood in Proportional Odds Model with Random EffectsFitting a Marginal (GEE-Type) ModelResponse Surface Comparisons with Multiplicity AdjustmentsGeneralized Poisson Mixed Model for Overdispersed Count DataComparing Multiple B-SplinesDiallel Experiment with Multimember Random EffectsLinear Inference Based on Summary DataWeighted Multilevel Model for Survey DataQuadrature Method for Multilevel Model
- References
Maximum Likelihood Estimation Based on Adaptive Quadrature
Quadrature methods, like the Laplace approximation, approximate integrals. If you choose METHOD=
QUAD
for a generalized linear mixed model, the GLIMMIX procedure approximates the marginal log likelihood with an adaptive Gauss-Hermite
quadrature rule. Gaussian quadrature is particularly well suited to numerically evaluate integrals against probability measures
(Lange 1999, Ch. 16). And Gauss-Hermite quadrature is appropriate when the density has kernel 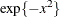 and integration extends over the real line, as is the case for the normal distribution. Suppose that
and integration extends over the real line, as is the case for the normal distribution. Suppose that 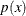 is a probability density function and the function
is a probability density function and the function 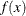 is to be integrated against it. Then the quadrature rule is
is to be integrated against it. Then the quadrature rule is
![\[ \int _{-\infty }^{\infty } f(x)p(x)\, dx \approx \sum _{i=1}^{N} w_ i f(x_ i) \]](images/statug_glimmix0652.png)
where N denotes the number of quadrature points, the 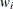 are the quadrature weights, and the
are the quadrature weights, and the 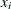 are the abscissas. The Gaussian quadrature chooses abscissas in areas of high density, and if is continuous, the quadrature rule is exact if is a polynomial of up to degree 2N – 1. In the generalized linear mixed model the roles of and are played by the conditional distribution of the data given the random effects, and the random-effects distribution, respectively.
Quadrature abscissas and weights are those of the standard Gauss-Hermite quadrature (Golub and Welsch 1969; see also Table 25.10 of Abramowitz and Stegun 1972; Evans 1993).
are the abscissas. The Gaussian quadrature chooses abscissas in areas of high density, and if is continuous, the quadrature rule is exact if is a polynomial of up to degree 2N – 1. In the generalized linear mixed model the roles of and are played by the conditional distribution of the data given the random effects, and the random-effects distribution, respectively.
Quadrature abscissas and weights are those of the standard Gauss-Hermite quadrature (Golub and Welsch 1969; see also Table 25.10 of Abramowitz and Stegun 1972; Evans 1993).
A numerical integration rule is called adaptive when it uses a variable step size to control the error of the approximation. For example, an adaptive trapezoidal rule uses serial splitting of intervals at midpoints until a desired tolerance is achieved. The quadrature rule in the GLIMMIX procedure is adaptive in the following sense: if you do not specify the number of quadrature points (nodes) with the QPOINTS= suboption of the METHOD= QUAD option, then the number of quadrature points is determined by evaluating the log likelihood at the starting values at a successively larger number of nodes until a tolerance is met (for more details see the text under the heading "Starting Values" in the next section). Furthermore, the GLIMMIX procedure centers and scales the quadrature points by using the empirical Bayes estimates (EBEs) of the random effects and the Hessian (second derivative) matrix from the EBE suboptimization. This centering and scaling improves the likelihood approximation by placing the abscissas according to the density function of the random effects. It is not, however, adaptiveness in the previously stated sense.
Objective Function
Let 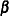 denote the vector of fixed-effects parameters and
denote the vector of fixed-effects parameters and 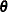 the vector of covariance parameters. For quadrature estimation in the GLIMMIX procedure, includes the G-side parameters and a possible
scale parameter
the vector of covariance parameters. For quadrature estimation in the GLIMMIX procedure, includes the G-side parameters and a possible
scale parameter  , provided that the conditional distribution of the data contains such a scale parameter.
, provided that the conditional distribution of the data contains such a scale parameter. 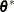 is the vector of the G-side parameters. The marginal distribution of the data for subject i in a mixed model can be expressed as
is the vector of the G-side parameters. The marginal distribution of the data for subject i in a mixed model can be expressed as
![\[ p(\mb{y}_ i) = \int \, \cdots \, \int p(\mb{y}_ i | \bgamma _ i,\bbeta ,\phi ) \, p(\bgamma _ i|\btheta ^*) \, \, d\bgamma _ i \]](images/statug_glimmix0654.png)
Suppose 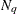 denotes the number of quadrature points in each dimension (for each random effect) and r denotes the number of random effects. For each subject, obtain the empirical Bayes estimates of
denotes the number of quadrature points in each dimension (for each random effect) and r denotes the number of random effects. For each subject, obtain the empirical Bayes estimates of 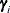 as the vector
as the vector 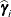 that minimizes
that minimizes
![\[ -\log \left\{ p(\mb{y}_ i | \bgamma _ i,\bbeta ,\phi ) p(\bgamma _ i|\btheta ^*) \right\} = f(\mb{y}_ i,\bbeta ,\btheta ;\bgamma _ i) \]](images/statug_glimmix0656.png)
If ![$\mb{z} = [z_1,\ldots ,z_{N_ q}]$](images/statug_glimmix0657.png) are the standard abscissas for Gauss-Hermite quadrature, and
are the standard abscissas for Gauss-Hermite quadrature, and ![$\mb{z}_ j^* = [z_{j_1},\ldots ,z_{j_ r}]$](images/statug_glimmix0658.png) is a point on the r-dimensional quadrature grid, then the centered and scaled abscissas are
is a point on the r-dimensional quadrature grid, then the centered and scaled abscissas are
![\[ \mb{a}_ j^* = \widehat{\bgamma }_ i + 2^{1/2} f”(\mb{y}_ i,\bbeta ,\btheta ;\widehat{\bgamma }_ i)^{-1/2} \mb{z}_ j^* \]](images/statug_glimmix0659.png)
As for the Laplace approximation, 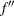 is the second derivative matrix with respect to the random effects,
is the second derivative matrix with respect to the random effects,
![\[ f”(\mb{y}_ i,\bbeta ,\btheta ;\widehat{\bgamma }_ i) = \frac{\partial ^2 f(\mb{y}_ i,\bbeta ,\btheta ;\bgamma _ i)}{\partial \bgamma _ i \partial \bgamma _ i'} |_{\widehat{\bgamma }_ i} \]](images/statug_glimmix0660.png)
These centered and scaled abscissas, along with the Gauss-Hermite quadrature weights ![$\mb{w} = [w_1,\ldots ,w_{N_ q}]$](images/statug_glimmix0661.png) , are used to construct the r-dimensional integral by a sequence of one-dimensional rules
, are used to construct the r-dimensional integral by a sequence of one-dimensional rules
![\begin{align*} p(\mb{y}_ i) & = \int \, \cdots \, \int p(\mb{y}_ i | \bgamma _ i,\bbeta ,\phi ) \, p(\bgamma _ i|\btheta ^*) \, \, d\bgamma _ i \\ & \approx 2^{r/2} | f”(\mb{y}_ i,\bbeta ,\btheta ;\widehat{\bgamma }_ i)|^{-1/2} \\ & \mbox{ } \sum _{j_1=1}^{N_ q} \, \cdots \, \sum _{j_ r=1}^{N_ q} \left[ p(\mb{y}_ i|\mb{a}_ j^*,\bbeta ,\phi ) p(\mb{a}_ j^*|\btheta ^*) \prod _{k=1}^ r w_{j_ k}\exp {z^2_{j_ k}} \right] \end{align*}](images/statug_glimmix0662.png)
The right-hand side of this expression, properly accumulated across subjects, is the objective function for adaptive quadrature estimation in the GLIMMIX procedure. The preceding expression constitutes a one-level adaptive Gaussian quadrature approximation.
As the number of random effects grows, the dimension of the integral increases accordingly. This increase can happen especially
when you have nested random effects. In this case, the one-level quadrature approximation described earlier quickly becomes
computationally infeasible. The following scenarios illustrate the relationship among the computational effort, the dimension
of the random effects, and the number of quadrature nodes. Suppose that the A effect has four levels, and consider the following statements:
proc glimmix method=quad(qpoints=5); class A id; model y = / dist=negbin; random A / subject=id; run;
For each subject, computing the marginal log likelihood requires the numerical evaluation of a four-dimensional integral.
With the number of quadrature points set to five by the QPOINTS=5 option, this means that each marginal log-likelihood evaluation
requires 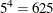 conditional log likelihoods to be computed for each observation on each pass through the data. As the number of quadrature
points or the number of random effects increases, this constitutes a sizable computational effort. Suppose, for example, that
just one additional random effect,
conditional log likelihoods to be computed for each observation on each pass through the data. As the number of quadrature
points or the number of random effects increases, this constitutes a sizable computational effort. Suppose, for example, that
just one additional random effect, B, with two levels is added as an interaction, as in the following statements:
proc glimmix method=quad(qpoints=5); class A B id; model y = / dist=negbin; random A A*B / subject=id; run;
Now a single marginal likelihood calculation requires 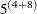 = 244,140,625 conditional log likelihoods for each observation on each pass through the data.
= 244,140,625 conditional log likelihoods for each observation on each pass through the data.
You can reduce the dimension of the random effects in the preceding PROC GLIMMIX code by factoring A out of the two random effects in the RANDOM statement, as shown in the following statements:
proc glimmix method=quad(qpoints=5); class A B id; model y = / dist=negbin; random int B / subject=id*A; run;
With the random effects int and B, the preceding PROC GLIMMIX code requires the evaluation of 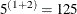 conditional log likelihoods for each observation on each pass through the data.
conditional log likelihoods for each observation on each pass through the data.
This idea of reducing the dimension of random effects is the key to the multilevel adaptive Gaussian quadrature algorithm described in Pinheiro and Chao (2006). By exploiting the sparseness in the random-effects design matrix , the multilevel quadrature algorithm reduces the dimension of the random effects to the sum of the dimensions of random effects from each level. You can use the FASTQUAD suboption in the METHOD= QUAD option to prompt PROC GLIMMIX to compute this multilevel quadrature approximation.
To see the effect of the FASTQUAD option, consider the following model for the preceding example:
proc glimmix method=quad(qpoints=5); class A B id; model y = / dist=negbin; random A A*B B/ subject=id; run;
In this case, it is not possible to factor a single SUBJECT= variable out of all the random effects. Formulated in this one-level
way, a single evaluation of the marginal likelihood requires the computing of 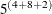 = 488,281,250 conditional log likelihoods for each observation on each pass through the data.
= 488,281,250 conditional log likelihoods for each observation on each pass through the data.
Alternatively, to take advantage of the multilevel quadrature approximation, you need to use the FASTQUAD option and explicitly specify the two-level structure by including one RANDOM statement for each level:
proc glimmix method=quad(qpoints=5 fastquad); class A B id; model y = / dist=negbin; random B / subject=id; random int B / subject=id*A; run;
The first RANDOM statement specifies the random effect B for the level that corresponds to id; the second RANDOM statement specifies the random effects int and B for the level that corresponds to id*A. With this specification, the multilevel quadrature approximation computes only 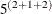 = 3,125 conditional log likelihoods for each observation on each pass through the data, where the exponent
= 3,125 conditional log likelihoods for each observation on each pass through the data, where the exponent 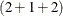 is the sum of the number of random effects in the two RANDOM statements.
is the sum of the number of random effects in the two RANDOM statements.
In general, consider a two-level model in which m level-2 units are nested within each level-1 unit. In this case, the one-level point adaptive quadrature approximation to a marginal likelihood that is an integral over 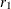 level-1 random effects and
level-1 random effects and 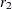 level-2 random effects requires
level-2 random effects requires 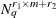 evaluations of the conditional log likelihoods for each observation. However, the two-level adaptive quadrature approximation
requires only
evaluations of the conditional log likelihoods for each observation. However, the two-level adaptive quadrature approximation
requires only 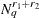 evaluations of the conditional log likelihoods. By increasing exponentially with instead of with
evaluations of the conditional log likelihoods. By increasing exponentially with instead of with 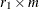 , the multilevel quadrature algorithm significantly reduces the computational and memory requirements.
, the multilevel quadrature algorithm significantly reduces the computational and memory requirements.
Quadrature or Laplace Approximation
If you select the quadrature rule with a single quadrature point, namely
proc glimmix method=quad(qpoints=1);
the results will be identical to METHOD=
LAPLACE
. Computationally, the two methods are not identical, however. METHOD=
LAPLACE
can be applied to a considerably larger class of models. For example, crossed random effects, models without subjects, or
models with non-nested subjects can be handled with the Laplace approximation but not with quadrature. Furthermore, METHOD=
LAPLACE
draws on a number of computational simplifications that can increase its efficiency compared to a quadrature algorithm with
a single node. For example, the Laplace approximation is possible with unbounded covariance parameter estimates (NOBOUND
option in the PROC GLIMMIX
statement) and can permit certain types of negative definite or indefinite 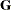 matrices. The adaptive quadrature approximation with scaled abscissas typically breaks down when is not at least positive semidefinite.
matrices. The adaptive quadrature approximation with scaled abscissas typically breaks down when is not at least positive semidefinite.
In the multilevel quadrature algorithm, the total number of random effects is the sum of the number of random effects at each level. Still, as the number of random effects grows at any of the levels, quadrature approximation becomes computationally infeasible. Laplace approximation presents a computationally more expedient alternative.
If you wonder whether METHOD= LAPLACE would present a viable alternative to a model that you can fit with METHOD= QUAD , the "Optimization Information" table can provide some insights. The table contains as its last entry the number of quadrature points determined by PROC GLIMMIX to yield a sufficiently accurate approximation of the log likelihood (at the starting values). In many cases, a single quadrature node is sufficient, in which case the estimates are identical to those of METHOD= LAPLACE .