The GLIMMIX Procedure
-
Overview

-
Getting Started
-
SyntaxPROC GLIMMIX StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementCOVTEST StatementEFFECT StatementESTIMATE StatementFREQ StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementOUTPUT StatementPARMS StatementRANDOM StatementSLICE StatementSTORE StatementWEIGHT StatementProgramming StatementsUser-Defined Link or Variance Function
-
DetailsGeneralized Linear Models TheoryGeneralized Linear Mixed Models TheoryGLM Mode or GLMM ModeStatistical Inference for Covariance ParametersDegrees of Freedom MethodsEmpirical Covariance ("Sandwich") EstimatorsExploring and Comparing Covariance MatricesProcessing by SubjectsRadial Smoothing Based on Mixed ModelsOdds and Odds Ratio EstimationParameterization of Generalized Linear Mixed ModelsResponse-Level Ordering and ReferencingComparing the GLIMMIX and MIXED ProceduresSingly or Doubly Iterative FittingDefault Estimation TechniquesDefault OutputNotes on Output StatisticsODS Table NamesODS Graphics
-
ExamplesBinomial Counts in Randomized BlocksMating Experiment with Crossed Random EffectsSmoothing Disease Rates; Standardized Mortality RatiosQuasi-likelihood Estimation for Proportions with Unknown DistributionJoint Modeling of Binary and Count DataRadial Smoothing of Repeated Measures DataIsotonic Contrasts for Ordered AlternativesAdjusted Covariance Matrices of Fixed EffectsTesting Equality of Covariance and Correlation MatricesMultiple Trends Correspond to Multiple Extrema in Profile LikelihoodsMaximum Likelihood in Proportional Odds Model with Random EffectsFitting a Marginal (GEE-Type) ModelResponse Surface Comparisons with Multiplicity AdjustmentsGeneralized Poisson Mixed Model for Overdispersed Count DataComparing Multiple B-SplinesDiallel Experiment with Multimember Random EffectsLinear Inference Based on Summary DataWeighted Multilevel Model for Survey DataQuadrature Method for Multilevel Model
- References
Example 45.18 Weighted Multilevel Model for Survey Data
Multilevel models are a useful tool for analyzing survey data from multistage sampling designs. In multistage designs, the first-stage clusters (primary sampling units) are selected by using a probability sample from a list of first-stage units. In the second stage, second-stage clusters are selected by using a probability sample from a list of second-stage clusters for every first-stage cluster in the sample. The third and subsequent stages of clusters are selected similarly. You can use multilevel models to analyze data from multistage designs in which each stage of sampling corresponds to one level of random effects in the model. The characteristics of the units at each stage become the explanatory variables at that level. If units are drawn with unequal selection probabilities at each stage, then the unweighted estimators from standard multilevel models can be biased. Pfeffermann et al. (1998) and Rabe-Hesketh and Skrondal (2006) discuss using sampling weights to reduce this bias.
To learn how to fit a two-level model, consider a two-stage design simulation that is similar to the simulation discussed in Rabe-Hesketh and Skrondal (2006).
First, you generate a finite population of 500 level-2 units and 50 level-1 units from a two-level random intercept probit model with dichotomous responses and linear predictor,
![\[ \eta _{ij}=\beta _0 + \beta _1 x_{1i} + \beta _2 x_{2ij} + \gamma _ i \]](images/statug_glimmix1114.png)
where 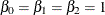 ,
, 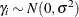 , and
, and 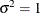 . The between-cluster covariate
. The between-cluster covariate x_1i and within-cluster covariate x_2ij are generated from a Bernoulli distribution with probability 0.5.
Then, you sample subsets of level-2 units and level-1 units from a two-stage sampling design similar to the one discussed in Rabe-Hesketh and Skrondal (2006). The generated sample contains a total of 7,530 observations. The inverse selection probabilities are used as weights. To reduce the bias in the variance parameter estimator, you scale the level-1 weights by using what Pfeffermann et al. (1998) and Rabe-Hesketh and Skrondal (2006) refer to as "Method 2."
The first 30 observations of the data set are shown in Output 45.18.1. In this data set, y is the dichotomous response variable, and x1 and x2 are the between-cluster and within-cluster covariates, respectively. The variables id and w2 identify the first-stage clusters (level-2 units) and their weights, respectively. The observation units are the second-stage
clusters (level-1 units), and their weights are scaled using "Method 2" in Pfeffermann et al. (1998) and Rabe-Hesketh and Skrondal (2006) and stored in sw1. The first-stage sampling weights, w2, range from 1.3359 to 4.0513, with an average of 1.6965. The second-stage sampling weights, w1, range from 1.8571 to 2.000, with an average of 1.9588. The scaled weights, sw1, range from 0.9657 to 1.0126, with an average of 1.000.
Output 45.18.1: Simulated Two-Stage Sampling Survey Data (First 30 Observations)
| Obs | x1 | x2 | y | w2 | id | sw1 |
|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 1.33594 | 1 | 1.00286 |
| 2 | 1 | 0 | 1 | 1.33594 | 1 | 1.00286 |
| 3 | 1 | 1 | 1 | 1.33594 | 1 | 1.00286 |
| 4 | 1 | 1 | 1 | 1.33594 | 1 | 1.00286 |
| 5 | 1 | 0 | 1 | 1.33594 | 1 | 1.00286 |
| 6 | 1 | 1 | 1 | 1.33594 | 1 | 1.00286 |
| 7 | 1 | 1 | 1 | 1.33594 | 1 | 1.00286 |
| 8 | 1 | 1 | 1 | 1.33594 | 1 | 1.00286 |
| 9 | 1 | 0 | 1 | 1.33594 | 1 | 1.00286 |
| 10 | 1 | 0 | 1 | 1.33594 | 1 | 1.00286 |
| 11 | 1 | 1 | 1 | 1.33594 | 1 | 1.00286 |
| 12 | 1 | 0 | 1 | 1.33594 | 1 | 1.00286 |
| 13 | 1 | 1 | 1 | 1.33594 | 1 | 1.00286 |
| 14 | 1 | 0 | 1 | 1.33594 | 1 | 1.00286 |
| 15 | 1 | 0 | 1 | 1.33594 | 1 | 0.99667 |
| 16 | 1 | 1 | 1 | 1.33594 | 1 | 0.99667 |
| 17 | 1 | 0 | 1 | 1.33594 | 1 | 0.99667 |
| 18 | 1 | 0 | 1 | 1.33594 | 1 | 0.99667 |
| 19 | 1 | 0 | 1 | 1.33594 | 1 | 0.99667 |
| 20 | 1 | 1 | 1 | 1.33594 | 1 | 0.99667 |
| 21 | 1 | 0 | 1 | 1.33594 | 1 | 0.99667 |
| 22 | 1 | 0 | 1 | 1.33594 | 1 | 0.99667 |
| 23 | 1 | 0 | 1 | 1.33594 | 1 | 0.99667 |
| 24 | 1 | 0 | 1 | 1.33594 | 1 | 0.99667 |
| 25 | 1 | 1 | 1 | 1.33594 | 1 | 0.99667 |
| 26 | 1 | 1 | 1 | 1.33594 | 1 | 0.99667 |
| 27 | 1 | 0 | 1 | 1.33594 | 2 | 0.99667 |
| 28 | 1 | 0 | 1 | 1.33594 | 2 | 0.99667 |
| 29 | 1 | 1 | 1 | 1.33594 | 2 | 0.99667 |
| 30 | 1 | 1 | 1 | 1.33594 | 2 | 0.99667 |
The following statements fit a two-level model without using weights at any level:
proc glimmix data=dws method=quadrature; class id; model y = x1 x2 / dist=binomial link=probit solution; random int / subject=id; run;
The parameter estimates are shown in Output 45.18.2. The estimated fixed-effects parameters are all close to their corresponding true values, but the estimated covariance parameter is almost half of its true value.
Output 45.18.2: Analysis of Two-Stage Sampling Survey Data
You can incorporate the unequal weights at both levels into the model by using the OBSWEIGHT= and WEIGHT= options as follows:
proc glimmix data=dws method=quadrature empirical=classical; class id; model y = x1 x2 / dist=binomial link=probit obsweight=sw1 solution; random int / subject=id weight=w2; run;
To fit a weighted multilevel model, you should use METHOD= QUAD . The EMPIRICAL =CLASSICAL option in the PROC GLIMMIX statement instructs PROC GLIMMIX to compute the empirical (sandwich) variance estimators for the fixed effect and the variance. The empirical variance estimators are recommended for the inference about fixed effects and variance estimated by pseudo-likelihood.
The OBSWEIGHT = option in the MODEL statement specifies the weight variable for the observation level. The WEIGHT = option in the RANDOM statement specifies the weight variable for the level that is specified by the SUBJECT = option.
The parameter estimates are shown in Output 45.18.3.
Output 45.18.3: Analysis of Two-Stage Sampling Survey Data Using Weights
Note that the estimated variance component for the random id effect is much closer to the true value of 1 in the weighted analysis. When you use the raw level-2 weights and the scaled
level-1 weights, the multilevel model reduces the bias in the variance parameter estimate. However, the standard errors for
the weighted analysis are larger than those for the unweighted analysis.