The SSM Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsState Space Model and NotationTypes of Sequence DataOverview of Model Specification SyntaxFiltering, Smoothing, Likelihood, and Structural Break DetectionEstimation of User-Specified Linear Combination of State ElementsContrasting PROC SSM with Other SAS Procedures Predefined Trend ModelsPredefined Structural ModelsCovariance ParameterizationMissing ValuesComputational IssuesDisplayed OutputODS Table NamesODS Graph NamesOUT= Data Set
-
ExamplesBivariate Basic Structural Model Panel Data: Random-Effects and Autoregressive ModelsBackcasting, Forecasting, and InterpolationLongitudinal Data: Smoothing of Repeated MeasuresA User-Defined Trend ModelModel with Multiple ARIMA ComponentsDynamic Factor ModelingDiagnostic Plots and Structural Break AnalysisLongitudinal Data: Variable Bandwidth SmoothingA Transfer Function Model for the Gas Furnace DataPanel Data: Dynamic Panel Model for the Cigar DataMultivariate Modeling: Long-Term Temperature TrendsBivariate Model: Sales of Mink and Muskrat FursFactor Model: Now-Casting the US EconomyLongitudinal Data: Lung Function Analysis
- References
This example considers a bivariate time series of logarithms of the annual sales of mink and muskrat furs by the Hudson’s Bay Company for the years 1850–1911. These data have been analyzed previously by many authors, including Chan and Wallis (1978); Harvey (1989); Reinsel (1997). There is known to be a predator-prey relationship between the mink and muskrat species: minks are principal predators of muskrats. The previous analyses for these data generally conclude the following:
-
An increase in the muskrat population is followed by an increase in the mink population a year later, and an increase in the mink population is followed by a decrease in the muskrat population a year later.
-
Because muskrats are not the only item in the mink diet, and both mink and muskrat populations are affected by many other factors, the model must include additional terms to explain the year-to-year variation.
The analysis in this example, which loosely follows the discussion in Harvey (1989, chap. 8, sec. 8), also leads to similar conclusions. It begins by taking Harvey’s model 8.8.8 (a and b), with autoregressive
order one, as the starting model—that is, assume that the bivariate (mink, muskrat) process ![]() satisfies the following relation:
satisfies the following relation:
This model postulates that ![]() can be expressed as a sum of three terms:
can be expressed as a sum of three terms: ![]() , a bivariate trend that is modeled as a random walk with drift
, a bivariate trend that is modeled as a random walk with drift ![]() ;
; ![]() , an AR(1) correction; and
, an AR(1) correction; and ![]() , a bivariate Gaussian white noise disturbance. It is assumed that the AR coefficient matrix
, a bivariate Gaussian white noise disturbance. It is assumed that the AR coefficient matrix ![]() is stable (that is, its eigenvalues are less than 1 in magnitude) and the bivariate disturbances
is stable (that is, its eigenvalues are less than 1 in magnitude) and the bivariate disturbances ![]() (white noise associated with
(white noise associated with ![]() ) and
) and ![]() are mutually independent. By noting that
are mutually independent. By noting that ![]() , you can formulate this model as a state space model (SSM) as follows:
, you can formulate this model as a state space model (SSM) as follows:
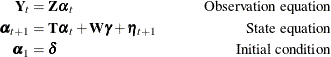
The different parts of the SSM are as follows: the 4-dimensional state vector ![]() , the
, the ![]() –dimensional matrix in the observation equation
–dimensional matrix in the observation equation ![]() , the
, the ![]() –dimensional transition matrix
–dimensional transition matrix ![]() , the 4-dimensional state disturbance vector
, the 4-dimensional state disturbance vector ![]() , the
, the ![]() -dimensional matrix
-dimensional matrix ![]() , and the state regression vector
, and the state regression vector ![]() (the drift term in the equation of
(the drift term in the equation of ![]() ). Here the matrices are specified in blocked form, with the rows separated by semicolons, and
). Here the matrices are specified in blocked form, with the rows separated by semicolons, and ![]() and
and ![]() denote the 2-dimensional identity and zero matrix, respectively. If
denote the 2-dimensional identity and zero matrix, respectively. If ![]() and
and ![]() , the covariance of the state disturbance
, the covariance of the state disturbance ![]() is given by
is given by ![]() , because
, because ![]() , and
, and ![]() and
and ![]() are mutually independent. A few points to note about this SSM formulation:
are mutually independent. A few points to note about this SSM formulation:
-
The system matrices (
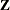 ,
, 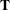 ,
, 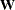 , and
, and 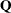 ) are time-invariant; the initial condition is totally diffuse (formed by the 6-dimensional vector
) are time-invariant; the initial condition is totally diffuse (formed by the 6-dimensional vector 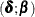 ); and the elements of
); and the elements of 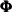 ,
, 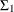 , and
, and 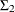 constitute the parameters of the model.
constitute the parameters of the model.
-
The observation equation does not contain any noise or regression terms, which is typical of SSMs in which the response variables are part of the state vector:
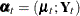 .
.
The following statements show how you can specify this model in the SSM procedure:
proc ssm data=furs plots=residual;
/* Specify the ID variable */
id year interval=year;
/* Define parameters */
parms phi11 phi12 phi21 phi22;
parms rho1 rho2/ lower=-0.9999 upper=0.9999;
parms msd1 msd2 esd1 esd2 / lower=1.e-8;
/* Define variables used to form T, W, and Q */
array tmat{4,4};
tmat[1,1] = 1; tmat[2,2] = 1;
tmat[3,1] = 1; tmat[3,3] = phi11; tmat[3,4] = phi12;
tmat[4,2] = 1; tmat[4,3] = phi21; tmat[4,4] = phi22;
array qmat{4,4};
qmat[1,1]=msd1*msd1; qmat[1,2]=msd1*msd2*rho1;
qmat[1,3]=qmat[1,1]; qmat[1,4]=qmat[1,2];
qmat[2,1]=qmat[1,2]; qmat[2,2]=msd2*msd2;
qmat[2,3]=qmat[1,2]; qmat[2,4]=qmat[2,2];
qmat[3,1]=qmat[1,3]; qmat[3,2]=qmat[2,3];
qmat[3,3]=qmat[1,1]+esd1*esd1;
qmat[3,4]=qmat[1,2]+esd1*esd2*rho2;
qmat[4,1]=qmat[1,4]; qmat[4,2]=qmat[2,4];
qmat[4,3]=qmat[3,4]; qmat[4,4]=qmat[2,2]+esd2*esd2;
array wmat{4,2};
wmat[1,1] = 1; wmat[1,2] = 0; wmat[2,1] = 0; wmat[2,2] = 1;
wmat[3,1] = 1; wmat[3,2] = 0; wmat[4,1] = 0; wmat[4,2] = 1;
/* Specify the state equation */
state alpha(4) t(g)=(tmat) w(g)=(wmat) cov(g)=(qmat) a1(4) print=(T cov);
/* Specify the components used in the observation equation */
comp minkVal = alpha[3];
comp muskVal = alpha[4];
/* Specify the observation equation */
model LogMink = minkVal;
model LogMusk = muskVal;
/* Specify components for output purposes: elements of trend mu */
comp minkLevel = alpha[1];
comp muskLevel = alpha[2];
/* Specify an output data set to store component estimates */
output out=salesFor press;
run;
The different parts of the program are explained as follows:
-
The first PARMS statement defines
phi11, phi12, phi21,andphi22as model parameters. They represent the elements of. Similarly, subsequent PARMS statements define additional parameters, which are used to form the elements of and . is parameterized as (msd1*msd1 msd1*msd2*rho1; msd1*msd2*rho1 msd2*msd2). is similarly parameterized by using esd1, esd2, andrho2. This parameterization ensures that and are positive semidefinite. The model assumes that is stable. The parameterization that this program uses does not impose this restriction.
-
The next several statements, such as the ARRAY statement, define lists of variables that are subsequently used in the specification of
, , and .
-
The STATE statement defines a 4-dimensional state subsection (in fact, the entire state vector in the case of this example), named
alpha.
The table in Output 27.13.1 shows the estimate of the drift vector ![]() in the equation of
in the equation of ![]() (
(![]() ).
).
Clearly, both elements of ![]() are statistically insignificant, and the
are statistically insignificant, and the ![]() equation can be simplified as
equation can be simplified as ![]() . Next, the table in Output 27.13.2 shows the estimates of the elements of
. Next, the table in Output 27.13.2 shows the estimates of the elements of ![]() ,
, ![]() , and
, and ![]() .
.
This table shows the following:
-
phi11, the first element of, which relates the current value of LogMinkwith its lagged value, is statistically insignificant. That is,phi11could be restricted to 0. -
rho2, the correlation coefficient between the elements of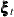 —the bivariate noise vector in the equation
—the bivariate noise vector in the equation 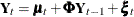 —is very near its lower boundary of –1 (in such cases the standard error of the parameter estimate is not reliable). This
implies that the two elements of are perfectly negatively correlated.
—is very near its lower boundary of –1 (in such cases the standard error of the parameter estimate is not reliable). This
implies that the two elements of are perfectly negatively correlated.
Taken together, these observations suggest the reduced model
where ![]() and
and ![]() is parameterized as (
is parameterized as (esd1*esd1 -esd1*esd2; -esd1*esd2 esd2*esd2). The program that produces the reduced model is a simple modification of the preceding program and is not shown.
The table in Output 27.13.3 shows the new parameter estimates. By examining the parameter estimates, you can easily see that this model supports the
general conclusions mentioned at the start of this example. In particular, note the following:
-
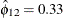 implies that this year’s mink abundance is positively correlated with last year’s muskrat abundance.
implies that this year’s mink abundance is positively correlated with last year’s muskrat abundance.
-
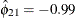 and
and 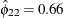 imply that this year’s muskrat abundance is negatively correlated with last year’s mink abundance and positively correlated
with last year’s muskrat abundance.
imply that this year’s muskrat abundance is negatively correlated with last year’s mink abundance and positively correlated
with last year’s muskrat abundance.
-
Even though the parameters were not restricted to ensure stability, the estimated
turns out to be stable with a pair of complex eigenvalues, 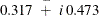 , and a modulus of 0.570 (these calculations are done separately by using the IML procedure).
, and a modulus of 0.570 (these calculations are done separately by using the IML procedure).
-
The fact that elements of
are perfectly negatively correlated further supports the predator-prey relationship.
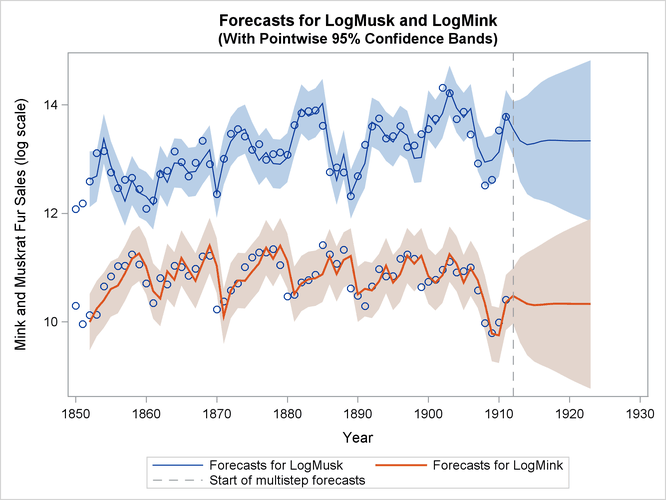
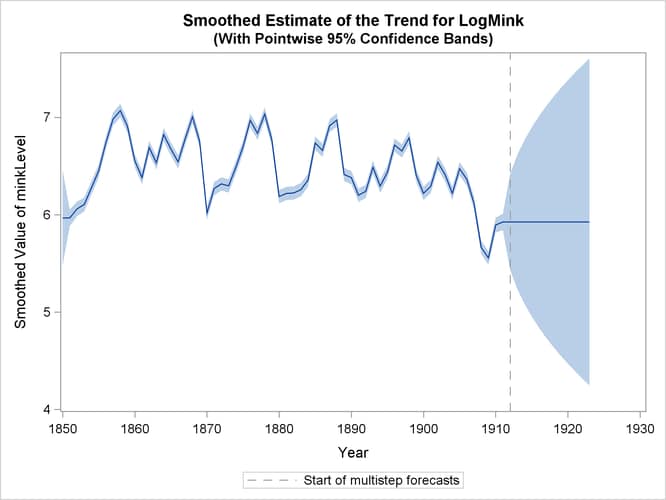
Finally, Output 27.13.4 shows the plots of one-step-ahead and post-sample forecasts for LogMink and LogMusk, and Output 27.13.5 shows the plot of the smoothed (full-sample) estimate of the first element of ![]() : LogMink Trend.
: LogMink Trend.