The MI Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsDescriptive StatisticsEM Algorithm for Data with Missing ValuesStatistical Assumptions for Multiple ImputationMissing Data PatternsImputation MethodsMonotone Methods for Data Sets with Monotone Missing PatternsMonotone and FCS Regression MethodsMonotone and FCS Predictive Mean Matching MethodsMonotone and FCS Discriminant Function MethodsMonotone and FCS Logistic Regression MethodsMonotone Propensity Score MethodFCS Methods for Data Sets with Arbitrary Missing PatternsChecking Convergence in FCS MethodsMCMC Method for Arbitrary Missing Multivariate Normal DataProducing Monotone Missingness with the MCMC MethodMCMC Method SpecificationsChecking Convergence in MCMCInput Data SetsOutput Data SetsCombining Inferences from Multiply Imputed Data SetsMultiple Imputation EfficiencyNumber of ImputationsImputer’s Model Versus Analyst’s ModelParameter Simulation versus Multiple ImputationSensitivity Analysis for the MAR AssumptionMultiple Imputation with Pattern-Mixture ModelsSpecifying Sets of Observations for Imputation in Pattern-Mixture ModelsAdjusting Imputed Values in Pattern-Mixture ModelsSummary of Issues in Multiple ImputationPlot Options Superseded by ODS GraphicsODS Table NamesODS Graphics
-
ExamplesEM Algorithm for MLEMonotone Propensity Score MethodMonotone Regression MethodMonotone Logistic Regression Method for CLASS VariablesMonotone Discriminant Function Method for CLASS VariablesFCS Methods for Continuous VariablesFCS Method for CLASS VariablesFCS Method with Trace PlotMCMC MethodProducing Monotone Missingness with MCMCChecking Convergence in MCMCSaving and Using Parameters for MCMCTransforming to NormalityMultistage ImputationCreating Control-Based Pattern Imputation in Sensitivity AnalysisAdjusting Imputed Continuous Values in Sensitivity AnalysisAdjusting Imputed Classification Levels in Sensitivity AnalysisAdjusting Imputed Values with Parameters in a Data Set
- References
MONOTONE Statement
-
MONOTONE <method <(<imputed <= effects>> </ options>)>><…method <(<imputed <= effects>> </ options>)>>;
The MONOTONE statement specifies imputation methods for data sets with monotone missingness. You must also specify a VAR statement, and the data set must have a monotone missing pattern with variables ordered in the VAR list.
Table 75.4 summarizes the options available for the MONOTONE statement.
Table 75.4: Summary of Imputation Methods in MONOTONE Statement
|
Option |
Description |
|---|---|
|
Specifies the discriminant function method |
|
|
Specifies the logistic regression method |
|
|
Specifies the propensity scores method |
|
|
Specifies the regression method |
|
|
Specifies the predictive mean matching method |
For each method, you can specify the imputed variables and, optionally, a set of the effects to impute these variables. Each effect is a variable or a combination of variables preceding the imputed variable in the VAR statement. The syntax for specification of effects is the same as for the GLM procedure. See Chapter 46: The GLM Procedure, for more information.
One general form of an effect involving several variables is
X1 * X2 * A * B * C ( D E )
where A, B, C, D, and E are classification variables and X1 and X2 are continuous variables.
When a MONOTONE statement is used without specifying any methods, the regression method is used for all imputed continuous variables and the discriminant function method is used for all imputed classification variables. In this case, for each imputed continuous variable, all preceding variables in the VAR statement are used as the covariates, and for each imputed classification variable, all preceding continuous variables in the VAR statement are used as the covariates.
When a method for continuous variables is specified without imputed variables, the method is used for all continuous variables in the VAR statement that are not specified in other methods. Similarly, when a method for classification variables is specified without imputed variables, the method is used for all classification variables in the VAR statement that are not specified in other methods.
For each imputed variable that does not use the discriminant function method, if no covariates are specified, then all preceding variables in the VAR statement are used as the covariates. That is, each preceding continuous variable is used as a regressor effect, and each preceding classification variable is used as a main effect. For an imputed variable that uses the discriminant function method, if no covariates are specified, then all preceding variables in the VAR statement are used as the covariates with the CLASSEFFECTS=INCLUDE option, and all preceding continuous variables in the VAR statement are used as the covariates with the CLASSEFFECTS=EXCLUDE option (which is the default).
With a MONOTONE statement, the variables are imputed sequentially in the order given by the VAR statement. For a continuous variable, you can use a regression method, a regression predicted mean matching method, or a propensity score method to impute missing values. For a nominal classification variable, you can use either a discriminant function method or a logistic regression method (generalized logit model) to impute missing values without using the ordering of the class levels. For an ordinal classification variable, you can use a logistic regression method (cumulative logit model) to impute missing values by using the ordering of the class levels. For a binary classification variable, either a discriminant function method or a logistic regression method can be used.
Note that except for the regression method, all other methods impute values from the observed observation values. You can specify the following methods in a MONOTONE statement.
- DISCRIM <( imputed < = effects> </ options> ) >
-
specifies the discriminant function method of classification variables. The available options are as follows:
See the section Monotone and FCS Discriminant Function Methods for a detailed description of the method.
- LOGISTIC <( imputed < = effects> </ options> ) >
-
specifies the logistic regression method for classification variables. The available options are as follows:
- DESCENDING
-
reverses the sort order for the levels of the response variables.
- DETAILS
-
displays the regression coefficients in the logistic regression model used in each imputation.
-
LIKELIHOOD=NOAUGMENT
LIKELIHOOD=AUGMENT <( WEIGHT=w | NPARM <(MULT=m)> )> -
specifies whether to add new observations to the likelihood function in the computation of maximum likelihood estimates. The LIKELIHOOD=AUGMENT option adds observations in each response group to the likelihood function, and the LIKELIHOOD=NOAUGMENT option makes no adjustment to the likelihood function. By default, LIKELIHOOD=NOAUGMENT.
The LIKELIHOOD=AUGMENT option is useful when the maximum likelihood parameter estimates do not exist. When LIKELIHOOD=AUGMENT, each added observation contributes the same weight, and the WEIGHT= option specifies the total added weight:
- WEIGHT=w
-
explicitly specifies the total added weight w.
- WEIGHT=NPARM <(MULT=m)>
-
uses the number of parameters in the logistic regression model as the total added weight. For example, for a simple binary logistic regression model that consists only of p continuous effects, the added weight is p+1. The MULT=m option specifies the multiplier for the total added weight, 0 <m
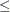 1, and the resulting total added weight is m times the number of parameters in the model. By default, MULT=1.
1, and the resulting total added weight is m times the number of parameters in the model. By default, MULT=1.
By default, WEIGHT=NPARM. You can specify either the MULT=m suboption in WEIGHT=NPARM or the WEIGHT=w option to use a different total added weight in the computation of maximum likelihood estimates. For example, if the ratio between the number of parameters and the number of available observations (before augmentation) is large, you can use either MULT=m or WEIGHT=w to reduce the weight for the added observations (that is, reduce the effect from the added observations in the computation of maximum likelihood estimates). For more information about the augmented data approach, see the section Logistic Regression with Augmented Data.
- LINK=GLOGIT | LOGIT
-
specifies the link function linking the response probabilities to the linear predictors. The default is LINK=LOGIT. The LINK=LOGIT option uses the log odds function to fit the binary logit model when there are two response categories and to fit the cumulative logit model when there are more than two response categories; and the LINK=GLOGIT option uses the generalized logit function to fit the generalized logit model where each nonreference category is contrasted with the last category.
- ORDER=DATA | FORMATTED | FREQ | INTERNAL
-
specifies the sort order for the levels of the response variable. The ORDER=DATA sorts by the order of appearance in the input data set; the ORDER=FORMATTED sorts by their external formatted values; the ORDER=FREQ sorts by the descending frequency counts; and the ORDER=INTERNAL sorts by the unformatted values. The default is ORDER=FORMATTED.
See the section Monotone and FCS Logistic Regression Methods for a detailed description of the method.
- PROPENSITY <( imputed < = effects> </ options> ) >
-
specifies the propensity scores method of variables. Each variable is either a classification variable or a continuous variable. The available options are DETAILS and NGROUPS=. The DETAILS option displays the regression coefficients in the logistic regression model for propensity scores. The NGROUPS= option specifies the number of groups created based on propensity scores. The default is NGROUPS=5.
See the section Monotone Propensity Score Method for a detailed description of the method.
- REG | REGRESSION <( imputed < = effects> </ DETAILS> ) >
-
specifies the regression method of continuous variables. The DETAILS option displays the regression coefficients in the regression model used in each imputation.
With a regression method, the MAXIMUM=, MINIMUM=, and ROUND= options can be used to make the imputed values more consistent with the observed variable values.
See the section Monotone and FCS Regression Methods for a detailed description of the method.
-
REGPMM < ( imputed < = effects> < / options> ) >
REGPREDMEANMATCH < ( imputed < = effects > < / options > ) > -
specifies the predictive mean matching method for continuous variables. This method is similar to the regression method except that it imputes a value randomly from a set of observed values whose predicted values are closest to the predicted value for the missing value from the simulated regression model (Heitjan and Little 1991; Schenker and Taylor 1996).
The available options are DETAILS and K=. The DETAILS option displays the regression coefficients in the regression model used in each imputation. The K= option specifies the number of closest observations to be used in the selection. The default is K=5.
See the section Monotone and FCS Predictive Mean Matching Methods for a detailed description of the method.
With a MONOTONE statement, the variables with missing values are imputed sequentially in the order specified in the VAR statement.
For example, the following MI procedure statements use the default regression method for continuous variables to impute variable
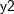 from the effect
from the effect 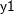 , the logistic regression method to impute variable
, the logistic regression method to impute variable 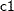 from effects , , and
from effects , , and 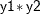 , and the regression method to impute variable
, and the regression method to impute variable 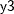 from effects , , and :
from effects , , and :
proc mi; class c1; var y1 y2 c1 y3; monotone logistic(c1= y1 y2 y1*y2); monotone reg(y3= y1 y2 c1); run;
The variable is not imputed since it is the leading variable in the VAR statement.