The MI Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsDescriptive StatisticsEM Algorithm for Data with Missing ValuesStatistical Assumptions for Multiple ImputationMissing Data PatternsImputation MethodsMonotone Methods for Data Sets with Monotone Missing PatternsMonotone and FCS Regression MethodsMonotone and FCS Predictive Mean Matching MethodsMonotone and FCS Discriminant Function MethodsMonotone and FCS Logistic Regression MethodsMonotone Propensity Score MethodFCS Methods for Data Sets with Arbitrary Missing PatternsChecking Convergence in FCS MethodsMCMC Method for Arbitrary Missing Multivariate Normal DataProducing Monotone Missingness with the MCMC MethodMCMC Method SpecificationsChecking Convergence in MCMCInput Data SetsOutput Data SetsCombining Inferences from Multiply Imputed Data SetsMultiple Imputation EfficiencyNumber of ImputationsImputer’s Model Versus Analyst’s ModelParameter Simulation versus Multiple ImputationSensitivity Analysis for the MAR AssumptionMultiple Imputation with Pattern-Mixture ModelsSpecifying Sets of Observations for Imputation in Pattern-Mixture ModelsAdjusting Imputed Values in Pattern-Mixture ModelsSummary of Issues in Multiple ImputationPlot Options Superseded by ODS GraphicsODS Table NamesODS Graphics
-
ExamplesEM Algorithm for MLEMonotone Propensity Score MethodMonotone Regression MethodMonotone Logistic Regression Method for CLASS VariablesMonotone Discriminant Function Method for CLASS VariablesFCS Methods for Continuous VariablesFCS Method for CLASS VariablesFCS Method with Trace PlotMCMC MethodProducing Monotone Missingness with MCMCChecking Convergence in MCMCSaving and Using Parameters for MCMCTransforming to NormalityMultistage ImputationCreating Control-Based Pattern Imputation in Sensitivity AnalysisAdjusting Imputed Continuous Values in Sensitivity AnalysisAdjusting Imputed Classification Levels in Sensitivity AnalysisAdjusting Imputed Values with Parameters in a Data Set
- References
Multiple Imputation with Pattern-Mixture Models
For 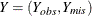 , the joint distribution of
, the joint distribution of Y and 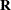 can be expressed as
can be expressed as
![\[ \mr{pr}(\, Y_{\mathit{obs}}, Y_{\mathit{mis}}, \mb{R} \, ) = \mr{pr}(\, Y_{\mathit{mis}} ~ |~ Y_{\mathit{obs}}, \mb{R} \, ) \; \mr{pr}(\, Y_{\mathit{obs}}, \mb{R} \, ) \]](images/statug_mi0330.png)
Under the MAR assumption,
![\[ \mr{pr}(\, \mb{R} ~ |~ Y_{\mathit{obs}}, Y_{\mathit{mis}} ) = \mr{pr}(\, \mb{R} ~ |~ Y_{\mathit{obs}} ) \]](images/statug_mi0331.png)
and it can be shown that
![\[ \mr{pr}(\, Y_{\mathit{mis}} ~ |~ Y_{\mathit{obs}}, \mb{R} \, ) = \mr{pr}(\, Y_{\mathit{mis}} ~ |~ Y_{\mathit{obs}} \, ) \]](images/statug_mi0332.png)
That is,
![\[ \mr{pr}(\, Y_{\mathit{mis}} ~ |~ Y_{\mathit{obs}}, \mb{R}=0 \, ) = \mr{pr}(\, Y_{\mathit{mis}} ~ |~ Y_{\mathit{obs}}, \mb{R}=1 \, ) \]](images/statug_mi0333.png)
Thus the posterior distribution 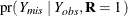 can be used to create imputations for missing data.
can be used to create imputations for missing data.
Under the MNAR assumption, each pattern that has missing 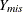 values might have a different distribution than the corresponding pattern that has observed values. For example, in a clinical trial, suppose the data set contains an indicator variable
values might have a different distribution than the corresponding pattern that has observed values. For example, in a clinical trial, suppose the data set contains an indicator variable Trt, with a value of 1 for patients in the treatment group and a value of 0 for patients in the placebo control group, a variable
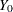 for the baseline efficacy score, and a variable
for the baseline efficacy score, and a variable Y for the efficacy score at a follow-up visit. Assume that Trt and are fully observed and Y is not fully observed. The indicator variable is 0 or 1, depending on whether Y is missing or observed.
Then, under the MAR assumption,
![\[ \mr{pr}(\, Y ~ |~ \Variable{Trt}=0, Y_0, \mb{R}=0 \, ) = \mr{pr}(\, Y ~ |~ \Variable{Trt}=0, Y_0, \mb{R}=1 \, ) \]](images/statug_mi0336.png)
and
![\[ \mr{pr}(\, Y ~ |~ \Variable{Trt}=1, Y_0, \mb{R}=0 \, ) = \mr{pr}(\, Y ~ |~ \Variable{Trt}=1, Y_0, \mb{R}=1 \, ) \]](images/statug_mi0337.png)
Under the MNAR assumption,
![\[ \mr{pr}(\, Y ~ |~ \Variable{Trt}=0, Y_0, \mb{R}=0 \, ) \neq \mr{pr}(\, Y ~ |~ \Variable{Trt}=0, Y_0, \mb{R}=1 \, ) \]](images/statug_mi0338.png)
or
![\[ \mr{pr}(\, Y ~ |~ \Variable{Trt}=1, Y_0, \mb{R}=0 \, ) \neq \mr{pr}(\, Y ~ |~ \Variable{Trt}=1, Y_0, \mb{R}=1 \, ) \]](images/statug_mi0339.png)
Thus, under MNAR, missing Y values in the treatment group can be imputed from a posterior distribution generated from observations in the control group,
and the imputed values can be adjusted to reflect the systematic difference between the distributions for missing and observed
Y values.
Multiple imputation inference, under either the MAR or MNAR assumption, involves three distinct phases:
-
The missing data are filled in m times to generate m complete data sets.
-
The m complete data sets are analyzed by using other SAS procedures.
-
The results from the m complete data sets are combined for the inference.
For sensitivity analysis, you must specify the MNAR statement together with a MONOTONE statement or an FCS statement. When you specify a MONOTONE statement, the variables that have missing values are imputed sequentially in each imputation. When you specify an FCS statement, each imputation is carried out in two phases: the preliminary filled-in phase, followed by the imputation phase. The variables that have missing values are imputed sequentially for a number of burn-in iterations before the imputation.
Under the MNAR assumption, the following steps are used to impute missing values for each imputed variable in each imputation (when you specify a MONOTONE statement) or in each iteration (when you specify an FCS statement):
-
For each imputed variable, a conditional model, such as a regression model for continuous variables, is fitted using either all applicable observations or a specified subset of observations.
-
A new model is simulated from the posterior predictive distribution of the fitted model.
-
Missing values of the variable are imputed based on the new model, and the imputed values for a specified subset of observations can be adjusted using specified shift and scale parameters.
The next two sections provide details for specifying subsets of observations for imputation models and for adjusting imputed values.