The MI Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsDescriptive StatisticsEM Algorithm for Data with Missing ValuesStatistical Assumptions for Multiple ImputationMissing Data PatternsImputation MethodsMonotone Methods for Data Sets with Monotone Missing PatternsMonotone and FCS Regression MethodsMonotone and FCS Predictive Mean Matching MethodsMonotone and FCS Discriminant Function MethodsMonotone and FCS Logistic Regression MethodsMonotone Propensity Score MethodFCS Methods for Data Sets with Arbitrary Missing PatternsChecking Convergence in FCS MethodsMCMC Method for Arbitrary Missing Multivariate Normal DataProducing Monotone Missingness with the MCMC MethodMCMC Method SpecificationsChecking Convergence in MCMCInput Data SetsOutput Data SetsCombining Inferences from Multiply Imputed Data SetsMultiple Imputation EfficiencyNumber of ImputationsImputer’s Model Versus Analyst’s ModelParameter Simulation versus Multiple ImputationSensitivity Analysis for the MAR AssumptionMultiple Imputation with Pattern-Mixture ModelsSpecifying Sets of Observations for Imputation in Pattern-Mixture ModelsAdjusting Imputed Values in Pattern-Mixture ModelsSummary of Issues in Multiple ImputationPlot Options Superseded by ODS GraphicsODS Table NamesODS Graphics
-
ExamplesEM Algorithm for MLEMonotone Propensity Score MethodMonotone Regression MethodMonotone Logistic Regression Method for CLASS VariablesMonotone Discriminant Function Method for CLASS VariablesFCS Methods for Continuous VariablesFCS Method for CLASS VariablesFCS Method with Trace PlotMCMC MethodProducing Monotone Missingness with MCMCChecking Convergence in MCMCSaving and Using Parameters for MCMCTransforming to NormalityMultistage ImputationCreating Control-Based Pattern Imputation in Sensitivity AnalysisAdjusting Imputed Continuous Values in Sensitivity AnalysisAdjusting Imputed Classification Levels in Sensitivity AnalysisAdjusting Imputed Values with Parameters in a Data Set
- References
MCMC Statement
-
MCMC <options>;
The MCMC statement specifies the details of the MCMC method for imputation.
Table 75.3 summarizes the options available for the MCMC statement.
Table 75.3: Summary of Options in MCMC
|
Option |
Description |
|---|---|
|
Data Sets |
|
|
Inputs parameter estimates for imputations |
|
|
Outputs parameter estimates used in imputations |
|
|
Outputs parameter estimates used in iterations |
|
|
Imputation Details |
|
|
Specifies monotone or full imputation |
|
|
Specifies single or multiple chain |
|
|
Specifies the number of burn-in iterations for each chain |
|
|
Specifies the number of iterations between imputations in a chain |
|
|
Specifies initial parameter estimates for MCMC |
|
|
Specifies the prior parameter information |
|
|
Specifies starting parameters |
|
|
ODS Graphics Output |
|
|
Displays trace plots |
|
|
Displays autocorrelation plots |
|
|
Printed Output |
|
|
Displays the worst linear function |
|
|
Displays initial parameter values for MCMC |
|
The following options are available for the MCMC statement (in alphabetical order).
- CHAIN=SINGLE | MULTIPLE
-
specifies whether a single chain is used for all imputations or a separate chain is used for each imputation. The default is CHAIN=SINGLE.
- DISPLAYINIT
-
displays initial parameter values in the MCMC method for each imputation.
- IMPUTE=FULL | MONOTONE
-
specifies whether a full-data imputation is used for all missing values or a monotone-data imputation is used for a subset of missing values to make the imputed data sets have a monotone missing pattern. The default is IMPUTE=FULL. When IMPUTE=MONOTONE is specified, the order in the VAR statement is used to complete the monotone pattern.
- INEST=SAS-data-set
-
names a SAS data set of TYPE=EST that contains parameter estimates for imputations. These estimates are used to impute values for observations in the DATA= data set. A detailed description of the data set is provided in the section Input Data Sets.
-
INITIAL=EM <(options)>
INITIAL=INPUT=SAS-data-set -
specifies the initial mean and covariance estimates for the MCMC method. The default is INITIAL=EM.
You can specify INITIAL=INPUT=SAS-data-set to read the initial estimates of the mean and covariance matrix for each imputation from a SAS data set. See the section Input Data Sets for a description of this data set.
With INITIAL=EM, PROC MI derives parameter estimates for a posterior mode, the highest observed-data posterior density, from the EM algorithm. The MLE from the EM algorithm is used to start the EM algorithm for the posterior mode, and the resulting EM estimates are used to begin the MCMC method. The prior information specified in the PRIOR= option is also used in the process to compute the posterior mode.
The following four options are available with INITIAL=EM:
- BOOTSTRAP < =number >
-
requests bootstrap resampling, which uses a simple random sample with replacement from the input data set for the initial estimate. You can explicitly specify the number of observations in the random sample. Alternatively, you can implicitly specify the number of observations in the random sample by specifying the proportion
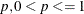 , to request [np] observations in the random sample, where n is the number of observations in the data set and [np] is the integer part of np. This produces an overdispersed initial estimate that provides different starting values for the MCMC method. If you specify
the BOOTSTRAP option without the number, p = 0.75 is used by default.
, to request [np] observations in the random sample, where n is the number of observations in the data set and [np] is the integer part of np. This produces an overdispersed initial estimate that provides different starting values for the MCMC method. If you specify
the BOOTSTRAP option without the number, p = 0.75 is used by default.
-
CONVERGE=p
XCONV=p -
sets the convergence criterion. The value must be between 0 and 1. The iterations are considered to have converged when the change in the parameter estimates between iteration steps is less than p for each parameter—that is, for each of the means and covariances. For each parameter, the change is a relative change if the parameter is greater than 0.01 in absolute value; otherwise, it is an absolute change. By default, CONVERGE=1E–4.
- ITPRINT
-
prints the iteration history in the EM algorithm for the posterior mode.
- MAXITER=number
-
specifies the maximum number of iterations used in the EM algorithm. The default is MAXITER=200.
- NBITER=number
-
specifies the number of burn-in iterations before the first imputation in each chain. The default is NBITER=200.
- NITER=number
-
specifies the number of iterations between imputations in a single chain. The default is NITER=100.
- OUTEST=SAS-data-set
-
creates an output SAS data set of TYPE=EST. The data set contains parameter estimates used in each imputation. The data set also includes a variable named
_Imputation_to identify the imputation number. See the section Output Data Sets for a description of this data set. - OUTITER <( options )> =SAS-data-set
-
creates an output SAS data set of TYPE=COV that contains parameters used in the imputation step for each iteration. The data set includes variables named
_Imputation_and_Iteration_to identify the imputation number and iteration number.The parameters in the output data set depend on the options specified. You can specify the options MEAN, STD, COV, LR, LR_POST, and WLF to output parameters of means, standard deviations, covariances, –2 log LR statistic, –2 log LR statistic of the posterior mode, and the worst linear function, respectively. When no options are specified, the output data set contains the mean parameters used in the imputation step for each iteration. See the section Output Data Sets for a description of this data set.
-
PLOTS <( LOG )> <= plot-request>
PLOTS <( LOG )> <= ( plot-request <…plot-request> )> -
requests statistical graphics via the Output Delivery System (ODS). To request these graphs, ODS Graphics must be enabled and you must specify options in the MCMC statement. For more information about ODS Graphics, see Chapter 21: Statistical Graphics Using ODS.
The global plot option LOG requests that the logarithmic transformations of parameters be used. The plot request options include the following:
The available acf-options are as follows:
The available trace-options are as follows:
-
PRIOR=name
PRIOR=JEFFREYS | RIDGE=number | INPUT=SAS-data-set -
specifies the prior information for the means and covariances. The PRIOR=JEFFREYS option specifies a noninformative prior, the RIDGE=number option specifies a ridge prior, and the INPUT=SAS-data-set option specifies a data set that contains prior information.
For a detailed description of the prior information, see the section Bayesian Estimation of the Mean Vector and Covariance Matrix and the section Posterior Step. If you do not specify the PRIOR= option, the default is PRIOR=JEFFREYS.
The PRIOR=INPUT= option specifies a TYPE=COV data set from which the prior information of the mean vector and the covariance matrix is read. See the section Input Data Sets for a description of this data set.
- START=VALUE | DIST
-
specifies that the initial parameter estimates are used either as the starting value (START=VALUE) or as the starting distribution (START=DIST) in the first imputation step of each chain. If the IMPUTE=MONOTONE option is specified, then START=VALUE is used in the procedure. The default is START=VALUE.
- WLF
-
displays the worst linear function of parameters. This scalar function of parameters
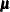 and
and 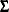 is "worst" in the sense that its values from iterations converge most slowly among parameters. For a detailed description
of this statistic, see the section Worst Linear Function of Parameters.
is "worst" in the sense that its values from iterations converge most slowly among parameters. For a detailed description
of this statistic, see the section Worst Linear Function of Parameters.