The MI Procedure
- Overview
- Getting Started
-
Syntax

-
DetailsDescriptive StatisticsEM Algorithm for Data with Missing ValuesStatistical Assumptions for Multiple ImputationMissing Data PatternsImputation MethodsMonotone Methods for Data Sets with Monotone Missing PatternsMonotone and FCS Regression MethodsMonotone and FCS Predictive Mean Matching MethodsMonotone and FCS Discriminant Function MethodsMonotone and FCS Logistic Regression MethodsMonotone Propensity Score MethodFCS Methods for Data Sets with Arbitrary Missing PatternsChecking Convergence in FCS MethodsMCMC Method for Arbitrary Missing Multivariate Normal DataProducing Monotone Missingness with the MCMC MethodMCMC Method SpecificationsChecking Convergence in MCMCInput Data SetsOutput Data SetsCombining Inferences from Multiply Imputed Data SetsMultiple Imputation EfficiencyNumber of ImputationsImputer’s Model Versus Analyst’s ModelParameter Simulation versus Multiple ImputationSensitivity Analysis for the MAR AssumptionMultiple Imputation with Pattern-Mixture ModelsSpecifying Sets of Observations for Imputation in Pattern-Mixture ModelsAdjusting Imputed Values in Pattern-Mixture ModelsSummary of Issues in Multiple ImputationPlot Options Superseded by ODS GraphicsODS Table NamesODS Graphics
-
ExamplesEM Algorithm for MLEMonotone Propensity Score MethodMonotone Regression MethodMonotone Logistic Regression Method for CLASS VariablesMonotone Discriminant Function Method for CLASS VariablesFCS Methods for Continuous VariablesFCS Method for CLASS VariablesFCS Method with Trace PlotMCMC MethodProducing Monotone Missingness with MCMCChecking Convergence in MCMCSaving and Using Parameters for MCMCTransforming to NormalityMultistage ImputationCreating Control-Based Pattern Imputation in Sensitivity AnalysisAdjusting Imputed Continuous Values in Sensitivity AnalysisAdjusting Imputed Classification Levels in Sensitivity AnalysisAdjusting Imputed Values with Parameters in a Data Set
- References
Adjusting Imputed Values in Pattern-Mixture Models
It is straightforward to specify pattern-mixture models under the MNAR assumption. When you impute continuous variables by using the regression and predictive mean matching methods, you can adjust the imputed values directly (Carpenter and Kenward 2013, pp. 237–239; Van Buuren 2012, pp. 88–89). When you impute classification variables by using the logistic regression method, you can adjust the imputed classification levels by modifying the log odds ratios for the classification levels (Carpenter and Kenward 2013, pp. 240–241; Van Buuren 2012, pp. 88–89). By modifying the log odds ratios, you modify the predicted probabilities for the classification levels.
For each imputed variable, you can use the ADJUST option to do the following:
-
specify a subset of observations for which imputed values are adjusted. Otherwise, all imputed values are adjusted.
-
adjust imputed continuous variable values by using the SHIFT=, SCALE=, and SIGMA= options. These options add a constant, multiply by a constant factor, and add a simulated value to the imputed values, respectively.
-
adjust imputed classification variable levels by adjusting predicted probabilities for the classification levels by using the SHIFT= and SIGMA= options. These options add a constant and add a simulated constant value, respectively, to the log odds ratios for the classification levels.
In addition, you can provide the shift and scale parameters for each imputation by using a PARMS= data set.
When you use the MNAR statement together with a MONOTONE statement, the variables are imputed sequentially. For each imputed variable, the values can be adjusted using the ADJUST option, and these adjusted values are used to impute values for subsequent variables.
When you use the MNAR statement together with an FCS statement, there are two phases in each imputation: the preliminary filled-in phase, followed by the imputation phase. For each imputed variable, the values can be adjusted using the ADJUST option in the imputation phase in each of the imputations. These adjusted values are used to impute values for other variables in the imputation phase.
For illustrations of adjusting imputed continuous values, adjusting log odds ratio for imputed classification levels, and adjusting imputed continuous values by using parameters that are stored in an input data set, see Example 75.16, Example 75.17, and Example 75.18, respectively.
Specifying the Imputed Values to Be Adjusted
By default, all available imputed values are adjusted. You can specify a subset of imputed values to be adjusted by using the ADJUSTOBS= suboption in the ADJUST option.
You can specify a classification variable to identify the subset of imputed values to be adjusted by using the ADJUSTOBS= (obs-variable= ’level1’ <’level2’ …>) option. This subset consists of the imputed values in the set of observations for which obs-variable equals one of the specified levels.
Adjusting Imputed Continuous Variables
For an imputed continuous variable, the SCALE=c option specifies the scale parameter, c > 0, for imputed values; the SHIFT=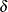 option specifies the shift parameter, , for imputed values; and the SIGMA=
option specifies the shift parameter, , for imputed values; and the SIGMA= option specifies the sigma parameter, > 0, for imputed values.
option specifies the sigma parameter, > 0, for imputed values.
When the sigma parameter is not specified, the adjusted value for each imputed value y is given by
![\[ y^{*} = c \, y + \delta \]](images/statug_mi0345.png)
where c is the scale parameter and is the shift parameter.
When you specify a sigma parameter , a simulated shift parameter is generated from the normal distribution that has mean and standard deviation in each imputation
![\[ \delta ^{*} \sim N \left( \, \delta , \; \sigma ^{2} \, \right) \]](images/statug_mi0346.png)
The adjusted value is then given by
![\[ y^{*} = c \, y + \delta ^{*} \]](images/statug_mi0347.png)
Adjusting Imputed Classification Variables
For an imputed classification variable, you can specify adjustment parameters for the response level. The SHIFT= option specifies the shift parameter , the SIGMA= option specifies the sigma parameter > 0, and the EVENT=’level’ option identifies the response level.
When the sigma parameter is not specified, the shift parameter is used in all imputations. When you specify a sigma parameter , a simulated shift parameter is generated from the normal distribution that has mean and standard deviation for each imputation
The next three sections provide details for adjusting imputed binary, ordinal, and nominal response variables.
Adjusting Imputed Binary Response Variables
For an imputed binary classification variable Y, the shift parameter is applied to the logit function values for the corresponding response level.
For instance, if Y has binary responses 1 and 2, a simulated logit model
![\[ \mbox{logit}(\, \mr{pr}( Y=1 ~ |~ \mb{x} ) \, ) = \alpha + \mb{x} ’ \bbeta \]](images/statug_mi0348.png)
is used to impute the missing response values. For a detailed description of this simulated logit model, see the section Binary Response Logistic Regression.
For an observation that has missing Y and covariates 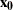 , the predicted probabilities that
, the predicted probabilities that Y=1 and Y=2 are then given by
![\[ \mr{pr}(Y=1) = \frac{ e^{ \alpha + \mb{x_0} ' \bbeta } }{ e^{ \alpha + \mb{x_0} ' \bbeta } + 1 } = \frac{ e^{ d_1 } }{ e^{ d_1 } + e^{ d_2 } } \]](images/statug_mi0350.png)
![\[ \mr{pr}(Y=2) = \frac{ 1 }{ e^{ \alpha + \mb{x_0} ' \bbeta } + 1 } = \frac{ e^{ d_2 } }{ e^{ d_1 } + e^{ d_2 } } \]](images/statug_mi0351.png)
where  and
and  .
.
When you provide the shift parameters  for the response
for the response Y=1 and  for the response
for the response Y=2, the predicted probabilities are
![\[ \mr{pr}(Y=1) = \frac{ e^{ d^{*}_1 } }{ e^{ d^{*}_1 } + e^{ d^{*}_2 } } \]](images/statug_mi0356.png)
![\[ \mr{pr}(Y=2) = \frac{ e^{ d^{*}_2 } }{ e^{ d^{*}_1 } + e^{ d^{*}_2 } } \]](images/statug_mi0357.png)
where  and
and  .
.
For example, the following statement specifies the shift parameters  and
and  :
:
mnar adjust( y(event='1') / shift=0.8)
adjust( y(event='2') / shift=1.6);
The statement
mnar adjust( y(event='1') / shift=0.8 sigma=0.2);
simulates a shift parameter from
![\[ \delta \sim N \left( \, 0.8, \; 0.2^{2} \, \right) \]](images/statug_mi0362.png)
in each imputation. Because an adjustment is not specified for Y=2, the corresponding shift parameter is  .
.
Adjusting Imputed Ordinal Response Variables
For an imputed ordinal classification variable Y, the shift parameter is applied to the cumulative logit function values for the corresponding response level.
For instance, if Y has ordinal responses 1, 2, …, K, a simulated cumulative logit model that has covariates  ,
,
![\[ \mbox{logit}(\, \mr{pr}( Y \leq k ~ |~ \mb{x} ) \, ) = \alpha _ k + \mb{x} ’ \bbeta \]](images/statug_mi0364.png)
is used to impute the missing response values, where k = 1, 2, …, K–1. For a detailed description of this model, see the section Ordinal Response Logistic Regression.
For an observation that has missing Y and covariates , the predicted cumulative probability for  , j = 1, 2, …, K–1, is then given by
, j = 1, 2, …, K–1, is then given by
![\[ \mr{pr}(Y \leq j) = \frac{ e^{\alpha _ j + \mb{x_0} ' \bbeta } }{ e^{\alpha _ j + \mb{x_0} ' \bbeta } + 1} = \frac{ e^{ d_ j } }{ e^{ d_ j } + e^{ d_ K } } \]](images/statug_mi0366.png)
where  and
and  .
.
The predicted probabilities for  are
are
![\[ \mr{pr}(Y = k) = \left\{ \begin{array}{ll} \frac{ e^{ d_1 } }{ e^{ d_1 } + e^{ d_ K } } & \mr{if} \; k=1 \\ \frac{ e^{ d_ k } }{ e^{ d_ k } + e^{ d_ K } } - \frac{ e^{ d_{(k-1)} } }{ e^{ d_{(k-1)} } + e^{ d_ K } } & \mr{if} \; 1<k<K \\ \frac{ e^{ d_ K } }{ e^{ d_{(K-1)} } + e^{ d_ K } } & \mr{if} \; k=K \end{array} \right. \]](images/statug_mi0370.png)
For an ordinal logistic regression method that has two response levels, the section Adjusting Imputed Binary Response Variables explains how the predicted probabilities are adjusted using shift parameters.
For an ordinal logistic regression method that has more than two response levels, only one classification level can be adjusted.
When you provide the shift parameter for the response level  , the predicted probability for is then given by
, the predicted probability for is then given by
![\[ \mr{pr}( Y = k) = \left\{ \begin{array}{ll} \frac{ e^{ d^{*}_1 } }{ e^{ d^{*}_1 } + e^{ d_ K } } & \mr{if} \; k=1 \\ \frac{ e^{ d^{*}_ k } }{ e^{ d^{*}_ k } + e^{ d_ K } } - \frac{ e^{ d_{(k-1)} } }{ e^{ d_{(k-1)} } + e^{ d_ K } } & \mr{if} \; 1<k<K \\ \frac{ e^{ d^{*}_ K } }{ e^{ d_{(K-1)} } + e^{ d^{*}_ K } } & \mr{if} \; k=K \end{array} \right. \]](images/statug_mi0372.png)
where  .
.
The predicted probabilities for the remaining  are then adjusted proportionally. When the shift parameter is less than 0, the value
are then adjusted proportionally. When the shift parameter is less than 0, the value  can be less than
can be less than  for
for  . In this case,
. In this case,  is set to 0.
is set to 0.
Adjusting Imputed Nominal Response Variables
For an imputed nominal classification variable Y, the shift parameter is applied to the generalized logit model function values for the corresponding response level.
For instance, if VariableY has nominal responses 1, 2, …, K, a simulated generalized logit model
![\[ \mbox{log} \left( \, \frac{\mr{pr}(\, Y = k ~ |~ \mb{x})}{\mr{pr}(\, Y = K ~ |~ \mb{x})} \right) = \alpha _ k + \mb{x} ’ \bbeta _ k \]](images/statug_mi0379.png)
is used to impute the missing response values, where k=1, 2, …, K–1. For a detailed description of this model, see the section Nominal Response Logistic Regression.
For an observation with missing Y and covariates , the predicted probability for Y = j, j < K, is then given by
![\[ \mr{pr}(Y=j) = \frac{ e^{ \alpha _ j + \mb{x_0} ' \bbeta _ j } }{ \sum _{k=1}^{K-1} {e^{ \alpha _ k + \mb{x_0} ' \bbeta _ k }} + 1 } = \frac{ e^{ d_ j } }{ \sum _{k=1}^{K} e^{ d_ k } } \]](images/statug_mi0380.png)
and
![\[ \mr{pr}(Y=K) = \frac{ 1 }{ \sum _{k=1}^{K-1} {e^{ \alpha _ k + \mb{x_0} ' \bbeta _ k }} + 1 } = \frac{ e^{ d_ K } }{ \sum _{k=1}^{K} e^{ d_ k } } \]](images/statug_mi0381.png)
where  for
for  and .
and .
When you use the shift parameters  for
for  , the predicted probabilities are
, the predicted probabilities are
![\[ \mr{pr}(Y=j) = \frac{ e^{ d^{*}_ j } }{ \sum _{k=1}^{K} e^{ d^{*}_ k } } \]](images/statug_mi0386.png)
where  .
.