The SEQDESIGN Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsFixed-Sample Clinical TrialsOne-Sided Fixed-Sample Tests in Clinical TrialsTwo-Sided Fixed-Sample Tests in Clinical TrialsGroup Sequential MethodsStatistical Assumptions for Group Sequential DesignsBoundary ScalesBoundary VariablesType I and Type II ErrorsUnified Family MethodsHaybittle-Peto MethodWhitehead MethodsError Spending MethodsAcceptance (beta) BoundaryBoundary Adjustments for Overlapping Lower and Upper beta BoundariesSpecified and Derived ParametersApplicable Boundary KeysSample Size ComputationApplicable One-Sample Tests and Sample Size ComputationApplicable Two-Sample Tests and Sample Size ComputationApplicable Regression Parameter Tests and Sample Size ComputationAspects of Group Sequential DesignsSummary of Methods in Group Sequential DesignsTable OutputODS Table NamesGraphics OutputODS Graphics
-
ExamplesCreating Fixed-Sample DesignsCreating a One-Sided O’Brien-Fleming DesignCreating Two-Sided Pocock and O’Brien-Fleming DesignsGenerating Graphics Display for Sequential DesignsCreating Designs Using Haybittle-Peto MethodsCreating Designs with Various Stopping CriteriaCreating Whitehead’s Triangular DesignsCreating a One-Sided Error Spending DesignCreating Designs with Various Number of StagesCreating Two-Sided Error Spending Designs with and without Overlapping Lower and Upper beta BoundariesCreating a Two-Sided Asymmetric Error Spending Design with Early Stopping to Reject H0Creating a Two-Sided Asymmetric Error Spending Design with Early Stopping to Reject or Accept H0Creating a Design with a Nonbinding Beta BoundaryComputing Sample Size for Survival Data That Have Uniform AccrualComputing Sample Size for Survival Data with Truncated Exponential Accrual
- References
Sample Size Computation
The SEQDESIGN procedure assumes that the data are from a multivariate normal distribution and the sequence of the standardized
test statistics 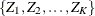 has the following canonical joint distribution:
has the following canonical joint distribution:
-
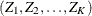 is multivariate normal
is multivariate normal
-
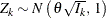
-
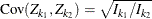 ,
, 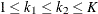
where K is the total number of stages and 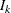 is the information available at stage k.
is the information available at stage k.
If the test statistic is computed from the data that are not from a normal distribution, such as a binomial distribution, then it is assumed that the test statistic is computed from a large sample such that the statistic has an approximately normal distribution.
In a typical clinical trial, the sample size required depends on the Type I error probability level  , alternative reference
, alternative reference 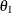 , power
, power 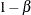 , and variance of the response variable. Given a one-sided null hypothesis
, and variance of the response variable. Given a one-sided null hypothesis 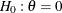 with an upper alternative hypothesis
with an upper alternative hypothesis 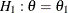 , the information required for a fixed-sample test is given by
, the information required for a fixed-sample test is given by
![\[ I_{0} = \frac{ ( \Phi ^{-1}(1-\alpha ) + \Phi ^{-1}(1-\beta ) )^{2} }{ {\theta }^{2}_{1} } \]](images/statug_seqdesign0593.png)
The parameter 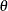 and the subsequent alternative reference depend on the test specified in the clinical trial. For example, suppose you are comparing two binomial populations
and the subsequent alternative reference depend on the test specified in the clinical trial. For example, suppose you are comparing two binomial populations 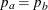 ; then
; then 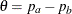 is the difference between two proportions if the proportion difference statistic is used, and
is the difference between two proportions if the proportion difference statistic is used, and 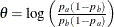 , the log odds ratio for the two proportions if the log odds ratio statistic is used.
, the log odds ratio for the two proportions if the log odds ratio statistic is used.
If the maximum likelihood estimate 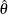 from the likelihood function can be derived, then the asymptotic variance for is
from the likelihood function can be derived, then the asymptotic variance for is 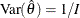 , where I is Fisher information for . The resulting statistic corresponds to the MLE statistic scale as specified in the BOUNDARYSCALE=MLE option in the PROC SEQDESIGN statement,
, where I is Fisher information for . The resulting statistic corresponds to the MLE statistic scale as specified in the BOUNDARYSCALE=MLE option in the PROC SEQDESIGN statement, 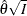 corresponds to the standardized Z scale (BOUNDARYSCALE=STDZ), and
corresponds to the standardized Z scale (BOUNDARYSCALE=STDZ), and 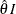 corresponds to the score statistic scale (BOUNDARYSCALE=SCORE).
corresponds to the score statistic scale (BOUNDARYSCALE=SCORE).
Alternatively, if the score statistic S is derived in a statistical procedure, it can be used as the test statistic and its asymptotic variance is given by Fisher
information, I. In this case, 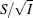 corresponds to the standardized Z scale and
corresponds to the standardized Z scale and 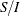 corresponds to the MLE statistic scale.
corresponds to the MLE statistic scale.
For a group sequential trial, the maximum information 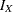 is derived in the SEQDESIGN procedure with the specified ,
is derived in the SEQDESIGN procedure with the specified , 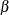 , and . With the maximum information
, and . With the maximum information
![\[ I_{X} = \frac{1}{\mr{Var}( \hat{\theta })} \]](images/statug_seqdesign0599.png)
the sample size required for a specified test statistic in the trial can be evaluated or estimated from the known or estimated variance of the response variable. Note that different designs might produce different maximum information levels for the same hypothesis, and this in turn might require a different number of observations for the trial.
If each observation in the data set provides one unit of information in a hypothesis testing, such as a one-sample test for the mean, the required sample size for the sequential design can be derived from the maximum information. However, for a survival analysis, an individual in the survival time data might provide only partial information because of censoring. In this case, the required number of events can be derived from the maximum information. With addition accrual information, the sample size can also be computed.
The SEQDESIGN procedure provides sample size computation for some one-sample and two-sample tests in the SAMPLESIZE statement. It also provides sample size computation for tests of a parameter in regression models such as normal regression, logistic regression, and proportional hazards regression. In addition, the procedure can also compute the required sample size or number of events from the corresponding number in the fixed-sample design.
Table 101.11 lists the options available in the SAMPLESIZE statement.
Table 101.11: SAMPLESIZE Statement Options
|
Option |
Description |
|---|---|
|
Fixed-Sample Models |
|
|
INPUTNOBS |
Specifies sample size for fixed-sample design |
|
INPUTNEVENTS |
Specifies number of events for fixed-sample design |
|
One-Sample Models |
|
|
ONESAMPLEMEAN |
Specifies one-sample Z test for mean |
|
ONESAMPLEFREQ |
Specifies one-sample test for binomial proportion |
|
Two-Sample Models |
|
|
TWOSAMPLEMEAN |
Specifies two-sample Z test for mean difference |
|
TWOSAMPLEFREQ |
Specifies two-sample test for binomial proportions |
|
TWOSAMPLESURVIVAL |
Specifies log-rank test for two survival distributions |
|
Regression Models |
|
|
REG |
Specifies test for a regression parameter |
|
LOGISTIC |
Specifies test for a logistic regression parameter |
|
PHREG |
Specifies test for a proportional hazards regression parameter |
The MODEL=INPUTNOBS and MODEL=INPUTNEVENTS options are described next, and the remaining options are described in the next three sections.
Input Sample Size for Fixed-Sample Design
The MODEL=INPUTNOBS option derives the sample size required for a group sequential trial from the sample size 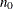 for the corresponding fixed-sample design. With the N= option specifying the sample size for a fixed-sample design, the sample size required for a group sequential trial is then computed as
for the corresponding fixed-sample design. With the N= option specifying the sample size for a fixed-sample design, the sample size required for a group sequential trial is then computed as
![\[ N_{X} = \frac{I_{X}}{I_{0}} \, \, n_{0} \]](images/statug_seqdesign0601.png)
where is the maximum information for the group sequential design and 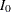 is the information for the corresponding fixed-sample design. The information ratio between and is derived in the SEQDESIGN procedure.
is the information for the corresponding fixed-sample design. The information ratio between and is derived in the SEQDESIGN procedure.
The SAMPLE=ONE option specifies a one-sample test, and the SAMPLE=TWO option specifies a two-sample test. For a two-sample test, the WEIGHT= option specifies the sample size allocation weights for the two groups.
Input Number of Events for Fixed-Sample Design
The MODEL=INPUTNEVENTS option derives the number of events required for a group sequential trial from the number of events
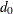 for the corresponding fixed-sample design. With the D= option specifies the number of events for a fixed-sample survival analysis, the number of events required for a group sequential trial is then computed as
for the corresponding fixed-sample design. With the D= option specifies the number of events for a fixed-sample survival analysis, the number of events required for a group sequential trial is then computed as
![\[ d_{X} = \frac{I_{X}}{I_{0}} \, \, d_{0} \]](images/statug_seqdesign0603.png)
where is the maximum information for the group sequential design and is the information for the corresponding fixed-sample design. The information ratio between and is derived in the SEQDESIGN procedure.
The SAMPLE=ONE option specifies a one-sample test, and the SAMPLE=TWO option specifies a two-sample test. For a two-sample test, the WEIGHT= option specifies the sample size allocation weights for the two groups.
The ACCRUAL= option specifies the method for individual accrual. The ACCRUAL=UNIFORM option (which is the default) specifies
that the individual accrual is uniform in the accrual time 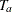 with a constant accrual rate
with a constant accrual rate 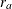 , and the ACCRUAL=EXP(PARM=
, and the ACCRUAL=EXP(PARM=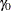 ) option specifies that the individual accrual is truncated exponential with a scaled power parameter , where
) option specifies that the individual accrual is truncated exponential with a scaled power parameter , where 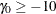 and
and 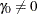 . With a scaled parameter , the power parameter for the truncated exponential with the accrual time is given by
. With a scaled parameter , the power parameter for the truncated exponential with the accrual time is given by 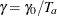 .
.
The LOSS= option specifies the individual loss to follow up in the sample size computation. The LOSS=NONE option (which is
the default) specifies no loss to follow up, and the EXP(POWER= ) option specifies exponential loss function with a power parameter .
) option specifies exponential loss function with a power parameter .
With the computed number of events 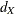 for a group sequential survival design, the required total sample size and sample size at each stage can be derived from
specifications of hazard rates, accrual information, and losses to follow-up information. For each study group, the hazard
rate h is constant (which corresponds to an exponential survival distribution) in the sample size computation.
for a group sequential survival design, the required total sample size and sample size at each stage can be derived from
specifications of hazard rates, accrual information, and losses to follow-up information. For each study group, the hazard
rate h is constant (which corresponds to an exponential survival distribution) in the sample size computation.
The next four subsections describe required sample sizes for uniform accrual (with and without losses to follow up) and for truncated exponential accrual (with and without losses to follow up).
Uniform Accrual without Losses to Follow Up
For a study group with a constant hazard rate h, if the individual accrual is uniform in the accrual time with a constant accrual rate , Kim and Tsiatis (1990, pp. 83–84) show that the expected number of events by time t is given by
![\[ D_{h}(t) = \left\{ \begin{array}{cl} r_{a} \left( t - \frac{1 - e^{-ht}}{h} \right) & \mbox{if} \, \, t \leq T_{a} \\ r_{a} \left( T_{a} - \frac{e^{-ht}}{h} (e^{h T_{a}} -1) \right) & \mbox{if} \, \, t > T_{a} \end{array} \right. \]](images/statug_seqdesign0605.png)
For a one-sample design (such as a proportional hazards regression), the expected number of events by time t is 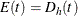 , where h is the hazard rate for the group. For a two-sample design (such as a log-rank test for two survival distributions), the expected
number of events by time t is
, where h is the hazard rate for the group. For a two-sample design (such as a log-rank test for two survival distributions), the expected
number of events by time t is
![\[ E(t) = \frac{R}{R+1} D_{h_{a}}(t) + \frac{1}{R+1} D_{h_{b}}(t) \]](images/statug_seqdesign0607.png)
where 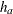 and
and 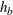 are hazard rates in groups
are hazard rates in groups A and B, respectively, and R is the ratio of the sample size allocation weights 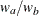 .
.
If the accrual rate is specified with one of the three time parameters—the accrual time, follow-up time, and total study time—then PROC SEQDESIGN
derives the other two time parameters by solving the equation for the expected number of events. Similarly, if the accrual
rate is not specified but two of the three time parameters are specified, then PROC SEQDESIGN derives the accrual rate.
If the accrual rate is specified without the accrual time , follow-up time 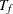 , and total study time
, and total study time 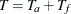 , the minimum and maximum accrual times can be computed from the following equation, as described in Kim and Tsiatis (1990, p. 85):
, the minimum and maximum accrual times can be computed from the following equation, as described in Kim and Tsiatis (1990, p. 85):
![\[ \frac{d_{X}}{r_ a} \leq T_ a \leq E^{-1}(d_ X) \]](images/statug_seqdesign0609.png)
With the accrual rate and the accrual time , the total sample size is
![\[ N_{X} = r_ a \; T_ a \]](images/statug_seqdesign0610.png)
At each stage k, the number of events is given by
![\[ d_ k = \frac{I_ k}{I_ X} \, \, d_ X \]](images/statug_seqdesign0611.png)
The corresponding time 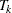 can be derived from the equation for the expected number of events,
can be derived from the equation for the expected number of events, 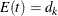 , and the resulting sample size is computed as
, and the resulting sample size is computed as
![\[ N_ k= \left\{ \begin{array}{cl} r_{a} \; T_ k & \mbox{if} \, \, T_ k \leq T_ a \\ r_{a} \; T_ a & \mbox{if} \, \, T_ k > T_ a \end{array} \right. \]](images/statug_seqdesign0614.png)
Uniform Accrual with Losses to Follow Up
With the LOSS=EXP(HAZARD=) option, the individual loss to follow up has an exponential loss distribution function
![\[ H(t)= 1 - e^{-\tau t} \]](images/statug_seqdesign0615.png)
where 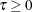 is the loss hazard rate. The loss hazard rate can also be specified implicitly with the MEDTIME=
is the loss hazard rate. The loss hazard rate can also be specified implicitly with the MEDTIME=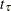 suboption through the median loss time .
suboption through the median loss time .
For a study group with a constant hazard rate h, if the individual accrual is uniform in the accrual time with a constant accrual rate and the individual loss to follow up has an exponential loss distribution function 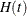 , Lachin and Foulkes (1986, p. 511) derive the expected number of events by time t (where
, Lachin and Foulkes (1986, p. 511) derive the expected number of events by time t (where 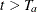 ) as
) as
![\[ D_{h}(t, T_ a) = r_{a} \, T_{a} \; \frac{h}{h+\tau } \left( 1 - \frac{1}{(h+\tau ) T_ a} e^{-(h+\tau ) t} (e^{h+\tau ) T_{a}} -1) \right) \]](images/statug_seqdesign0619.png)
For 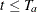 , the SEQDESIGN procedure estimates the expected number of events by time t as
, the SEQDESIGN procedure estimates the expected number of events by time t as
![\[ D_{h}(t, T_ a) = r_{a} \, t \; \frac{h}{h+\tau } \left( 1 - \frac{1}{(h+\tau ) \, t} (1 - e^{-(h+\tau ) t}) \right) \]](images/statug_seqdesign0621.png)
For a one-sample design (such as a proportional hazards regression), the expected number of events by time t is 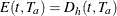 , where h is the hazard rate for the group. For a two-sample design (such as a log-rank test for two survival distributions), the expected
number of events by time t is
, where h is the hazard rate for the group. For a two-sample design (such as a log-rank test for two survival distributions), the expected
number of events by time t is
![\[ E(t, T_ a) = \frac{R}{R+1} D_{h_ a}(t, T_ a) + \frac{1}{R+1} D_{h_ b}(t, T_ a) \]](images/statug_seqdesign0623.png)
where and are hazard rates in groups A and B, respectively, and R is the ratio of the sample size allocation weights 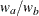 .
.
If the accrual rate 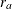 is specified with one of the three time parameters—the accrual time, follow-up time, and total study time—then PROC SEQDESIGN
derives the other two time parameters by solving the equation for the expected number of events. Similarly, if the accrual
rate is not specified, but two of the three time parameters are specified, then PROC SEQDESIGN derives the accrual rate.
is specified with one of the three time parameters—the accrual time, follow-up time, and total study time—then PROC SEQDESIGN
derives the other two time parameters by solving the equation for the expected number of events. Similarly, if the accrual
rate is not specified, but two of the three time parameters are specified, then PROC SEQDESIGN derives the accrual rate.
If the accrual rate is specified without the accrual time , follow-up time , and total study time , the SEQDESIGN procedure computes the minimum accrual time by solving the equation
![\[ E(\infty , T_ a) = d_ X \]](images/statug_seqdesign0626.png)
A closed-form solution is then given by
![\[ \frac{d_{X}}{r_{a}} \; \left( \frac{R}{R+1} \; \frac{h_ a}{h_ a+\tau } \, + \, \frac{1}{R+1} \; \frac{h_ b}{h_ b+\tau } \right)^{-1} \]](images/statug_seqdesign0627.png)
Similarly, the SEQDESIGN procedure derives the maximum accrual time by solving the equation
![\[ E(T_ a, T_ a) = d_ X \]](images/statug_seqdesign0628.png)
The maximum accrual time is then obtained by an iterative process.
With the accrual rate and the accrual time 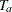 , the total sample size is
, the total sample size is
![\[ N_{X} = r_{a} \; T_{a} \]](images/statug_seqdesign0630.png)
At each stage k, the number of events is given by
![\[ d_{k} = \frac{I_{k}}{I_{X}} \, \, d_{X} \]](images/statug_seqdesign0631.png)
The corresponding time can be derived from the equation for the expected number of events, 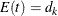 , and the resulting sample size is computed as
, and the resulting sample size is computed as
![\[ N_ k= \left\{ \begin{array}{cl} r_{a} \; T_ k & \mbox{if} \, \, T_ k \leq T_{a} \\ r_{a} \; T_ a & \mbox{if} \, \, T_ k > T_{a} \end{array} \right. \]](images/statug_seqdesign0633.png)
Truncated Exponential Accrual without Losses to Follow Up
For a study group with a constant hazard rate h, if the individual accrual is truncated exponential with parameter 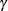 over the accrual period from 0 to with distribution
over the accrual period from 0 to with distribution
![\[ F(t)= \frac{1 - e^{-\gamma t}}{1 - e^{-\gamma T_ a}} \; \; \; \; \mbox{for} \, \, 0 \leq t \leq T_{a} \]](images/statug_seqdesign0634.png)
Lachin and Foulkes (1986, p. 510) derive the expected number of events by time t (where ) as
![\[ D_{h}(t, N) = N \left( 1 + \frac{\gamma }{h-\gamma } \; \, \frac{e^{-ht} - e^{-h (t-T_ a)} e^{-\gamma T_ a}}{1 - e^{-\gamma T_ a}} \right) \]](images/statug_seqdesign0635.png)
where N is the total sample size.
For , the SEQDESIGN procedure estimates the expected number of events by time t as
![\[ D_{h}(t, N) = N \, F(t) \left( 1 + \frac{\gamma }{h-\gamma } \; \frac{e^{-h t} - e^{-\gamma t}}{1 - e^{-\gamma t}} \right) \]](images/statug_seqdesign0636.png)
For the truncated exponential accrual function with a parameter over the accrual period from 0 to , you specify the scaled parameter 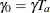 in the ACCRUAL=EXP(PARM=) option, where and .
in the ACCRUAL=EXP(PARM=) option, where and .
For a one-sample design (such as a proportional hazards regression), the expected number of events by time t is 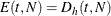 , where h is the hazard rate for the group. For a two-sample design (such as a log-rank test for two survival distributions), the expected
number of events by time t is
, where h is the hazard rate for the group. For a two-sample design (such as a log-rank test for two survival distributions), the expected
number of events by time t is
![\[ E(t, N) = \frac{R}{R+1} D_{h_{a}}(t, N) + \frac{1}{R+1} D_{h_{b}}(t, N) \]](images/statug_seqdesign0639.png)
where 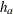 and
and 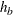 are hazard rates in groups
are hazard rates in groups A and B, respectively, and R is the ratio of the sample size allocation weights .
If the total sample size N is specified, then at least one of the three time parameters—the accrual time, follow-up time, and total study time—must be specified, and then PROC SEQDESIGN derives the other two time parameters by solving the equation for the expected number of events. Similarly, if the total sample size N is not specified, then at least two of the three time parameters must be specified, and PROC SEQDESIGN derives the sample size.
If the accrual sample size N is not specified, the SEQDESIGN procedure computes the minimum accrual sample size by solving the equation
![\[ E(\infty , N) = d_ X \]](images/statug_seqdesign0641.png)
That is, 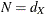 .
.
Similarly, if the total sample size N is not specified but the accrual time is specified, the SEQDESIGN procedure derives the maximum accrual sample size N by solving the equation
![\[ E(T_ a, N) = d_ X \]](images/statug_seqdesign0643.png)
At each stage k, the number of events is given by
The corresponding time can be derived from the equation for the expected number of events, , and the resulting sample size is computed as
![\[ N_ k= \left\{ \begin{array}{cl} N \; F(T_ k) & \mbox{if} \, \, T_ k \leq T_{a} \\ N & \mbox{if} \, \, T_ k > T_{a} \end{array} \right. \]](images/statug_seqdesign0644.png)
Truncated Exponential Accrual with Losses to Follow Up
With the LOSS=EXP(HAZARD=) option, the individual loss to follow up has an exponential loss distribution function
where is the loss hazard rate. The loss hazard rate can also be specified implicitly with the MEDTIME= suboption through the median loss time .
For a study group with a constant hazard rate h, if the individual accrual is truncated exponential with parameter over the accrual period from 0 to with distribution
and the individual loss to follow up has an exponential loss distribution function , Lachin and Foulkes (1986, p. 513) derive the expected number of events by time t (where ) as
![\[ D_{h}(t, N) = N \, \frac{h}{h+\tau } \, \left( 1 + \frac{\gamma }{h+\tau -\gamma } \; \, \frac{e^{-(h+\tau ) t} - e^{-(h+\tau )(t-T_ a)} e^{-\gamma T_ a}}{1 - e^{-\gamma T_ a}} \right) \]](images/statug_seqdesign0645.png)
For , the SEQDESIGN procedure estimates the expected number of events by time t as
![\[ D_{h}(t, N) = N \, F(t) \, \frac{h}{h+\tau } \, \left( 1 + \frac{\gamma }{h+\tau -\gamma } \; \, \frac{e^{-(h+\tau ) t} - e^{-\gamma t}}{1 - e^{-\gamma t}} \right) \]](images/statug_seqdesign0646.png)
For the truncated exponential accrual function with a parameter over the accrual period from 0 to , you specify the scaled parameter in the ACCRUAL=EXP(PARM=) option, where and .
For a one-sample design (such as a proportional hazards regression), the expected number of events by time t is , where h is the hazard rate for the group. For a two-sample design (such as a log-rank test for two survival distributions), the expected
number of events by time t is
where and are hazard rates in groups A and B, respectively, and R is the ratio of the sample size allocation weights .
If the total sample size N is specified, then at least one of the three time parameters—the accrual time, follow-up time, and total study time—must be specified, and then PROC SEQDESIGN derives the other two time parameters by solving the equation for the expected number of events. Similarly, if the total sample size N is not specified, then at least two of the three time parameters must be specified, and PROC SEQDESIGN derives the sample size.
If the accrual sample size is not specified, the SEQDESIGN procedure computes the minimum sample size N by solving the equation
A closed-form solution is then given by
![\[ d_ X \; \left( \frac{R}{R+1} \; \frac{h_ a}{h_ a+\tau } \, + \, \frac{1}{R+1} \; \frac{h_ b}{h_ b+\tau } \right)^{-1} \]](images/statug_seqdesign0647.png)
Similarly, if the accrual sample size N is not specified but the accrual time is specified, the SEQDESIGN procedure derives the maximum accrual sample size N by solving the equation
At each stage k, the number of events is given by
The corresponding time can be derived from the equation for the expected number of events, , and the resulting sample size is computed as
The following three sections describe examples of test statistics with their resulting information levels, which can then be used to derive the required sample size. The maximum likelihood estimators are used for all tests except to compare two survival distributions with a log-rank test, where a score statistic is used.