The SEQDESIGN Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsFixed-Sample Clinical TrialsOne-Sided Fixed-Sample Tests in Clinical TrialsTwo-Sided Fixed-Sample Tests in Clinical TrialsGroup Sequential MethodsStatistical Assumptions for Group Sequential DesignsBoundary ScalesBoundary VariablesType I and Type II ErrorsUnified Family MethodsHaybittle-Peto MethodWhitehead MethodsError Spending MethodsAcceptance (beta) BoundaryBoundary Adjustments for Overlapping Lower and Upper beta BoundariesSpecified and Derived ParametersApplicable Boundary KeysSample Size ComputationApplicable One-Sample Tests and Sample Size ComputationApplicable Two-Sample Tests and Sample Size ComputationApplicable Regression Parameter Tests and Sample Size ComputationAspects of Group Sequential DesignsSummary of Methods in Group Sequential DesignsTable OutputODS Table NamesGraphics OutputODS Graphics
-
ExamplesCreating Fixed-Sample DesignsCreating a One-Sided O’Brien-Fleming DesignCreating Two-Sided Pocock and O’Brien-Fleming DesignsGenerating Graphics Display for Sequential DesignsCreating Designs Using Haybittle-Peto MethodsCreating Designs with Various Stopping CriteriaCreating Whitehead’s Triangular DesignsCreating a One-Sided Error Spending DesignCreating Designs with Various Number of StagesCreating Two-Sided Error Spending Designs with and without Overlapping Lower and Upper beta BoundariesCreating a Two-Sided Asymmetric Error Spending Design with Early Stopping to Reject H0Creating a Two-Sided Asymmetric Error Spending Design with Early Stopping to Reject or Accept H0Creating a Design with a Nonbinding Beta BoundaryComputing Sample Size for Survival Data That Have Uniform AccrualComputing Sample Size for Survival Data with Truncated Exponential Accrual
- References
Error Spending Methods
For each sequential design, the  and
and 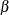 errors spent at each stage can be computed from the boundary values. For example, for a K-stage design with an upper alternative hypothesis
errors spent at each stage can be computed from the boundary values. For example, for a K-stage design with an upper alternative hypothesis 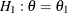 and early stopping to reject the null hypothesis
and early stopping to reject the null hypothesis 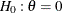 , the boundary values in a standardized Z scale are the upper critical values
, the boundary values in a standardized Z scale are the upper critical values 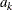 ,
, 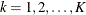 . At each interim stage, the null hypothesis
. At each interim stage, the null hypothesis 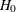 is rejected if the observed standardized Z statistic
is rejected if the observed standardized Z statistic 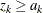 . Otherwise, the process continues to the next stage. At the final stage, the hypothesis is rejected if
. Otherwise, the process continues to the next stage. At the final stage, the hypothesis is rejected if 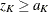 . Otherwise, the null hypothesis is accepted.
. Otherwise, the null hypothesis is accepted.
The boundary values are derived such that the overall Type I error probability
![\[ \alpha = \sum _{k=1}^{K} {\alpha _{k}} \]](images/statug_seqdesign0393.png)
where 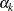 is the spending at stage k. That is, at stage 1,
is the spending at stage k. That is, at stage 1,
![\[ {\alpha _{1}} = P_{\theta = 0} \, ( \, z_{1} \geq a_{1} \, ) \]](images/statug_seqdesign0557.png)
At a subsequent stage k,
![\[ {\alpha _{k}} = P_{\theta = 0} \, ( \, z_{j} < a_{j}, j=1, 2, \ldots , k-1, \, \, z_{k} \geq a_{k} \, ) \]](images/statug_seqdesign0558.png)
Since each design can be uniquely identified by the and errors spent at each stage, a design can then be derived by specifying the and errors to be used at each stage. The error spending method (Lan and DeMets 1983)
distributes the error to be used at each stage and then derives the boundary values. Numerous forms of the error spending
function are available. Kim and DeMets (1987) examine the functions 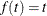 ,
, 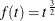 , and
, and 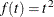 , where t is the information fraction. Jennison and Turnbull (2000, p. 148) generalize these functions to the power functions
, where t is the information fraction. Jennison and Turnbull (2000, p. 148) generalize these functions to the power functions 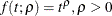 .
.
The ERRFUNCPOC option uses the cumulative error spending function (Lan and DeMets 1983)
![\[ E( t) = \left\{ \begin{array}{ll} 1 & \mr{if} \, \, t \geq 1 \\ \mr{log}( \, 1+(e-1)t) & \mr{if} \, \, 0 < t < 1 \\ 0 & \mr{otherwise} \end{array} \right. \]](images/statug_seqdesign0563.png)
With a specified error of or , the cumulative error spending at stage k is 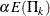 or
or 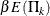 , where
, where 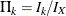 is the information fraction at stage k. The method produces boundaries similar to those produced with Pocock’s method.
is the information fraction at stage k. The method produces boundaries similar to those produced with Pocock’s method.
The ERRFUNCOBF option uses the cumulative error spending function (Lan and DeMets 1983)
![\[ E( t; a) = \left\{ \begin{array}{ll} 1 & \mr{if} \, \, t \geq 1 \\ \frac{1}{a} \, 2 \, ( 1 - \Phi ( \frac{z_{(1-a/2)}}{\sqrt {t}})) & \mr{if} \, \, 0 < t < 1 \\ 0 & \mr{otherwise} \end{array} \right. \]](images/statug_seqdesign0567.png)
where a is either for the spending function or for the spending function. That is, with a specified error of or , the cumulative error spending at stage k is 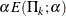 or
or 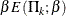 . The method produces boundaries similar to those produced with the O’Brien-Fleming method.
. The method produces boundaries similar to those produced with the O’Brien-Fleming method.
The ERRFUNCGAMMA option uses the gamma cumulative error spending function (Hwang, Shih, and DeCani 1990)
![\[ E( t; \gamma ) = \left\{ \begin{array}{ll} 1 & \mr{if} \, \, t \geq 1 \\ \frac{1 - e^{-\gamma t}}{1 - e^{-\gamma }} & \mr{if} \, \, 0 < t < 1 , \gamma \neq 0\\ {t} & \mr{if} \, \, 0 < t < 1 , \gamma = 0 \\ 0 & \mr{otherwise} \end{array} \right. \]](images/statug_seqdesign0570.png)
where 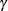 is the parameter specified in the GAMMA= option. That is, with a specified error of or , the cumulative error spending at stage k is
is the parameter specified in the GAMMA= option. That is, with a specified error of or , the cumulative error spending at stage k is 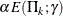 or
or 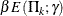 .
.
The ERRFUNCPOW option uses the cumulative error spending function (Jennison and Turnbull 2000, p. 148)
![\[ E( t; \rho ) = \left\{ \begin{array}{ll} 1 & \mr{if} \, \, t \geq 1 \\ {t}^{\rho } & \mr{if} \, \, 0 < t < 1 \\ 0 & \mr{otherwise} \end{array} \right. \]](images/statug_seqdesign0573.png)
where 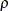 is the power parameter specified in the RHO= option. That is, with a specified error of or , the cumulative error spending at stage k is
is the power parameter specified in the RHO= option. That is, with a specified error of or , the cumulative error spending at stage k is 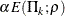 or
or 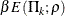 .
.
Error spending methods derive boundary values at each stage sequentially and require much more computation than other types
of methods for group sequential trials with a large number of stages, especially for a two-sided asymmetric design with early
stopping to accept 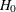 , or to reject or accept .
, or to reject or accept .
Note that for a two-sided design with the STOP=BOTH or STOP=ACCEPT option, at each interim stage, the SEQDESIGN procedure
first produces the lower and upper boundary values based on the one-sided spending. If the lower boundary value is greater than or equal to its corresponding upper boundary value, there is no early stopping to accept the null hypothesis at this stage, and the corresponding spending is distributed proportionally to the remaining stages.
For the error spending functions not available in the SEQDESIGN procedure, you can first compute the corresponding error spending at each stage explicitly, then use the SEQDESIGN procedure with the ERRSPEND= option to specify these errors directly.
For example, if the information levels are equally spaced in a five-stage design, the option ERRFUNCPOW (RHO=2) produces relative
cumulative errors of 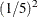 ,
, 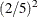 ,
, 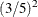 ,
, 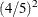 , and 1. This is equivalent to using the option ERRSPEND (1 4 9 16 25).
, and 1. This is equivalent to using the option ERRSPEND (1 4 9 16 25).
A one-sided error spending design is illustrated in Example 101.8 and a two-sided asymmetric error spending design is illustrated in Example 101.11.