The SEQDESIGN Procedure
-
Overview

- Getting Started
-
Syntax
-
Details
Fixed-Sample Clinical Trials One-Sided Fixed-Sample Tests in Clinical Trials Two-Sided Fixed-Sample Tests in Clinical Trials Group Sequential Methods Statistical Assumptions for Group Sequential Designs Boundary Scales Boundary Variables Type I and Type II Errors Unified Family Methods Haybittle-Peto Method Whitehead Methods Error Spending Methods Acceptance (beta) Boundary Boundary Adjustments for Overlapping Lower and Upper beta Boundaries Specified and Derived Parameters Applicable Boundary Keys Sample Size Computation Applicable One-Sample Tests and Sample Size Computation Applicable Two-Sample Tests and Sample Size Computation Applicable Regression Parameter Tests and Sample Size Computation Aspects of Group Sequential Designs Summary of Methods in Group Sequential Designs Table Output ODS Table Names Graphics Output ODS Graphics Acknowledgments
-
Examples
Creating Fixed-Sample Designs Creating a One-Sided O’Brien-Fleming Design Creating Two-Sided Pocock and O’Brien-Fleming Designs Generating Graphics Display for Sequential Designs Creating Designs Using Haybittle-Peto Methods Creating Designs with Various Stopping Criteria Creating Whitehead’s Triangular Designs Creating a One-Sided Error Spending Design Creating Designs with Various Number of Stages Creating Two-Sided Error Spending Designs with and without Overlapping Lower and Upper beta Boundaries Creating a Two-Sided Asymmetric Error Spending Design with Early Stopping to Reject H0 Creating a Two-Sided Asymmetric Error Spending Design with Early Stopping to Reject or Accept H0
- References
| Fixed-Sample Clinical Trials |
A clinical trial is a research study in consenting human beings to answer specific health questions. One type of trial is a treatment trial, which tests the effectiveness of an experimental treatment. An example is a planned experiment designed to assess the efficacy of a treatment in humans by comparing the outcomes in a group of patients who receive the test treatment with the outcomes in a comparable group of patients who receive a placebo control treatment, where patients in both groups are enrolled, treated, and followed over the same time period.
A clinical trial is conducted according to a plan called a protocol. The protocol provides detailed description of the study. For a fixed-sample trial, the study protocol contains detailed information such as the null hypothesis, the one-sided or two-sided test, and the Type I and II error probability levels. It also includes the test statistic and its associated critical values in the hypothesis testing.
Generally, the efficacy of a new treatment is demonstrated by testing a hypothesis 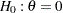 in a clinical trial, where
in a clinical trial, where 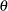 is the parameter of interest. For example, to test whether a population mean
is the parameter of interest. For example, to test whether a population mean 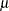 is greater than a specified value
is greater than a specified value 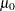 ,
, 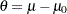 can be used with an alternative
can be used with an alternative 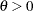 .
.
A one-sided test is a test of the hypothesis with either an upper (greater) or a lower (lesser) alternative, and a two-sided test is a test of the hypothesis with a two-sided alternative. The drug industry often prefers to use a one-sided test to demonstrate clinical superiority based on the argument that a study should not be run if the test drug would be worse (Chow, Shao, and Wang 2003, p. 28). But in practice, two-sided tests are commonly performed in drug development (Senn 1997, p. 161). For a fixed Type I error probability  , the sample sizes required by one-sided and two-sided tests are different. Refer to Senn (1997, pp. 161–167) for a detailed description of issues involving one-sided and two-sided tests.
, the sample sizes required by one-sided and two-sided tests are different. Refer to Senn (1997, pp. 161–167) for a detailed description of issues involving one-sided and two-sided tests.
For independent and identically distributed observations 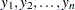 of a random variable, the likelihood function for is
of a random variable, the likelihood function for is
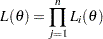 |
where is the population parameter and 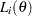 is the probability or probability density of
is the probability or probability density of 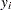 . Using the likelihood function, two statistics can be derived that are useful for inference: the maximum likelihood estimator and the score statistic.
. Using the likelihood function, two statistics can be derived that are useful for inference: the maximum likelihood estimator and the score statistic.
Maximum Likelihood Estimator
The maximum likelihood estimate (MLE) of is the value 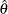 that maximizes the likelihood function for . Under mild regularity conditions, is an asymptotically unbiased estimate of with variance
that maximizes the likelihood function for . Under mild regularity conditions, is an asymptotically unbiased estimate of with variance 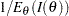 , where
, where 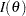 is the Fisher information
is the Fisher information
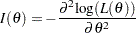 |
and 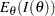 is the expected Fisher information (Diggle et al. 2002, p. 340)
is the expected Fisher information (Diggle et al. 2002, p. 340)
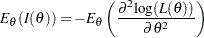 |
The score function for is defined as
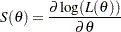 |
and usually, the MLE can be derived by solving the likelihood equation 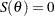 . Asymptotically, the MLE is normally distributed (Lindgren 1976, p. 272):
. Asymptotically, the MLE is normally distributed (Lindgren 1976, p. 272):
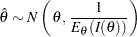 |
If the Fisher information does not depend on , then is known. Otherwise, either the expected information evaluated at the MLE 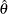 (
(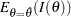 ) or the observed information
) or the observed information 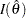 can be used for the Fisher information (Cox and Hinkley 1974, p. 302; Efron and Hinkley 1978, p. 458), where the observed Fisher information
can be used for the Fisher information (Cox and Hinkley 1974, p. 302; Efron and Hinkley 1978, p. 458), where the observed Fisher information
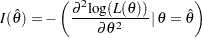 |
If the Fisher information does depend on , the observed Fisher information is recommended for the variance of the maximum likelihood estimator (Efron and Hinkley 1978, p. 457).
Thus, asymptotically, for large  ,
,
 |
where 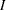 is the information, either the expected Fisher information
is the information, either the expected Fisher information 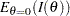 or the observed Fisher information
or the observed Fisher information 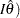 .
.
So to test versus 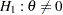 , you can use the standardized
, you can use the standardized 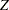 test statistic
test statistic
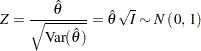 |
and the two-sided 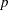 -value is given by
-value is given by
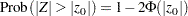 |
where 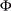 is the cumulative standard normal distribution function and
is the cumulative standard normal distribution function and 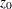 is the observed statistic.
is the observed statistic.
If the BOUNDARYSCALE=SCORE is specified in the SEQDESIGN procedure, the boundary values for the test statistic are displayed in the score statistic scale. With the standardized statistic, the score statistic 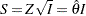 and
and
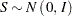 |
Score Statistic
The score statistic is based on the score function for ,
|
Under the null hypothesis , the score statistic 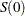 is the first derivative of the log likelihood evaluated at the null reference
is the first derivative of the log likelihood evaluated at the null reference 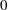 :
:
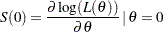 |
Under regularity conditions, is asymptotically normally distributed with mean zero and variance , the expected Fisher information evaluated at the null hypothesis 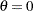 (Kalbfleisch and Prentice 1980, p. 45), where is the Fisher information
(Kalbfleisch and Prentice 1980, p. 45), where is the Fisher information
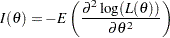 |
That is, for large ,
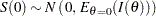 |
Asymptotically, the variance of the score statistic , , can also be replaced by the expected Fisher information evaluated at the MLE 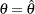 (), the observed Fisher information evaluated at the null hypothesis (
(), the observed Fisher information evaluated at the null hypothesis (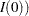 , or the observed Fisher information evaluated at the MLE (
, or the observed Fisher information evaluated at the MLE (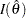 ) (Kalbfleisch and Prentice 1980, p. 46), where
) (Kalbfleisch and Prentice 1980, p. 46), where
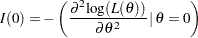 |
|
Thus, asymptotically, for large ,
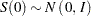 |
where is the information, either an expected Fisher information ( or ) or a observed Fisher information (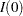 or ).
or ).
So to test versus , you can use the standardized test statistic
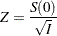 |
If the BOUNDARYSCALE=MLE is specified in the SEQDESIGN procedure, the boundary values for the test statistic are displayed in the MLE scale. With the standardized statistic, the MLE statistic 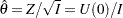 and
and
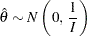 |
One-Sample Test for Mean
The following one-sample test for mean is used to demonstrate fixed-sample clinical trials in the section One-Sided Fixed-Sample Tests in Clinical Trials and the section Two-Sided Fixed-Sample Tests in Clinical Trials.
Suppose 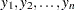 are observations of a response variable Y from a normal distribution
are observations of a response variable Y from a normal distribution
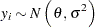 |
where is the unknown mean and 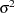 is the known variance.
is the known variance.
Then the log likelihood function for is
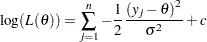 |
where  is a constant. The first derivative is
is a constant. The first derivative is
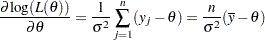 |
where 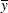 is the sample mean.
is the sample mean.
Setting the first derivative to zero, the MLE of is 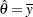 , the sample mean. The variance for can be derived from the Fisher information
, the sample mean. The variance for can be derived from the Fisher information
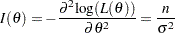 |
Since the Fisher information 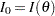 does not depend on in this case,
does not depend on in this case, 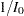 is used as the variance for . Thus the sample mean has a normal distribution with mean and variance
is used as the variance for . Thus the sample mean has a normal distribution with mean and variance 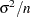 :
:
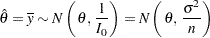 |
Under the null hypothesis , the score statistic
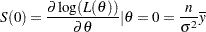 |
has a mean zero and variance
|
With the MLE , the corresponding standardized statistic is computed as 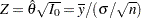 , which has a normal distribution with variance
, which has a normal distribution with variance  :
:
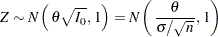 |
Also, the corresponding score statistic is computed as 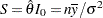 and
and
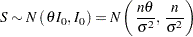 |
which is identical to computed under the null hypothesis .
Note that if the variable Y does not have a normal distribution, then it is assumed that the sample size is large such that the sample mean has an approximately normal distribution.