The GENMOD Procedure
-
Overview

-
Getting Started
-
SyntaxPROC GENMOD StatementASSESS StatementBAYES StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementDEVIANCE StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementFWDLINK StatementINVLINK StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementProgramming StatementsREPEATED StatementSLICE StatementSTORE StatementSTRATA StatementVARIANCE StatementWEIGHT StatementZEROMODEL Statement
-
DetailsGeneralized Linear Models TheorySpecification of EffectsParameterization Used in PROC GENMODType 1 AnalysisType 3 AnalysisConfidence Intervals for ParametersF StatisticsLagrange Multiplier StatisticsPredicted Values of the MeanResidualsMultinomial ModelsZero-Inflated ModelsTweedie Distribution For Generalized Linear ModelsGeneralized Estimating EquationsAssessment of Models Based on Aggregates of ResidualsCase Deletion Diagnostic StatisticsBayesian AnalysisExact Logistic and Exact Poisson RegressionResponse Level OrderingMissing ValuesDisplayed Output for Classical AnalysisDisplayed Output for Bayesian AnalysisDisplayed Output for Exact AnalysisODS Table NamesODS Graphics
-
ExamplesLogistic RegressionNormal Regression, Log Link Gamma Distribution Applied to Life DataOrdinal Model for Multinomial DataGEE for Binary Data with Logit Link FunctionLog Odds Ratios and the ALR AlgorithmLog-Linear Model for Count DataModel Assessment of Multiple Regression Using Aggregates of ResidualsAssessment of a Marginal Model for Dependent DataBayesian Analysis of a Poisson Regression ModelExact Poisson RegressionTweedie Regression
- References
Parameterization Used in PROC GENMOD
Design Matrix
The linear predictor part of a generalized linear model is
![\[ \bm {\eta } = \mb{X} \bbeta \]](images/statug_genmod0259.png)
where 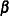 is an unknown parameter vector and
is an unknown parameter vector and 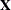 is a known design matrix.
By default, all models automatically contain an intercept term; that is, the first column of contains all 1s. Additional columns of are generated for classification variables, regression variables, and any interaction terms included in the model. It is
important to understand the ordering of classification variable parameters when you use the ESTIMATE or CONTRAST statement.
The ordering of these parameters is displayed in the "CLASS Level Information"
table and in tables displaying the parameter estimates of the fitted model.
is a known design matrix.
By default, all models automatically contain an intercept term; that is, the first column of contains all 1s. Additional columns of are generated for classification variables, regression variables, and any interaction terms included in the model. It is
important to understand the ordering of classification variable parameters when you use the ESTIMATE or CONTRAST statement.
The ordering of these parameters is displayed in the "CLASS Level Information"
table and in tables displaying the parameter estimates of the fitted model.
When you specify an overparameterized model with the PARAM=
GLM option in the CLASS statement, some columns of can be linearly dependent on other columns. For example, when you specify a model consisting of an intercept term and a classification
variable, the column corresponding to any one of the levels of the classification variable is linearly dependent on the other
columns of . The columns of 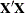 are checked in the order in which the model is specified for dependence on preceding columns. If a dependency is found, the
parameter corresponding to the dependent column is set to 0 along with its standard error to indicate that it is not estimated.
The order in which the levels of a classification variable are checked for dependencies can be set by the ORDER=
option in the PROC GENMOD statement or by the ORDER=
option in the CLASS statement. For full-rank parameterizations, the columns of the matrix are designed to be linearly independent.
are checked in the order in which the model is specified for dependence on preceding columns. If a dependency is found, the
parameter corresponding to the dependent column is set to 0 along with its standard error to indicate that it is not estimated.
The order in which the levels of a classification variable are checked for dependencies can be set by the ORDER=
option in the PROC GENMOD statement or by the ORDER=
option in the CLASS statement. For full-rank parameterizations, the columns of the matrix are designed to be linearly independent.
You can exclude the intercept term from the model by specifying the NOINT option in the MODEL statement.
Missing Level Combinations
All levels of interaction terms involving classification variables might not be represented in the data. In that case, PROC GENMOD does not include parameters in the model for the missing levels.