The LOGISTIC Procedure
- Overview
- Getting Started
-
Syntax
 PROC LOGISTIC StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementEFFECT StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementODDSRATIO StatementOUTPUT StatementROC StatementROCCONTRAST StatementSCORE StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement
PROC LOGISTIC StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementEFFECT StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementODDSRATIO StatementOUTPUT StatementROC StatementROCCONTRAST StatementSCORE StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement -
DetailsMissing ValuesResponse Level OrderingLink Functions and the Corresponding DistributionsDetermining Observations for Likelihood ContributionsIterative Algorithms for Model FittingConvergence CriteriaExistence of Maximum Likelihood EstimatesEffect-Selection MethodsModel Fitting InformationGeneralized Coefficient of DeterminationScore Statistics and TestsConfidence Intervals for ParametersOdds Ratio EstimationRank Correlation of Observed Responses and Predicted ProbabilitiesLinear Predictor, Predicted Probability, and Confidence LimitsClassification TableOverdispersionThe Hosmer-Lemeshow Goodness-of-Fit TestReceiver Operating Characteristic CurvesTesting Linear Hypotheses about the Regression CoefficientsJoint Tests and Type 3 TestsRegression DiagnosticsScoring Data SetsConditional Logistic RegressionExact Conditional Logistic RegressionInput and Output Data SetsComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesStepwise Logistic Regression and Predicted ValuesLogistic Modeling with Categorical PredictorsOrdinal Logistic RegressionNominal Response Data: Generalized Logits ModelStratified SamplingLogistic Regression DiagnosticsROC Curve, Customized Odds Ratios, Goodness-of-Fit Statistics, R-Square, and Confidence LimitsComparing Receiver Operating Characteristic CurvesGoodness-of-Fit Tests and SubpopulationsOverdispersionConditional Logistic Regression for Matched Pairs DataExact Conditional Logistic RegressionFirth’s Penalized Likelihood Compared with Other ApproachesComplementary Log-Log Model for Infection RatesComplementary Log-Log Model for Interval-Censored Survival TimesScoring Data SetsUsing the LSMEANS StatementPartial Proportional Odds Model
- References
Overview: LOGISTIC Procedure
Binary responses (for example, success and failure), ordinal responses (for example, normal, mild, and severe), and nominal responses (for example, major TV networks viewed at a certain hour) arise in many fields of study. Logistic regression analysis is often used to investigate the relationship between these discrete responses and a set of explanatory variables. Texts that discuss logistic regression include Agresti (2013); Allison (2012); Collett (2003); Cox and Snell (1989); Hosmer and Lemeshow (2013); Stokes, Davis, and Koch (2012).
For binary response models, the response, Y, of an individual or an experimental unit can take on one of two possible values, denoted for convenience by 1 and 2 (for
example, Y = 1 if a disease is present, otherwise Y = 2). Suppose  is a vector of explanatory variables and
is a vector of explanatory variables and 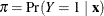 is the response probability to be modeled. The linear logistic model has the form
is the response probability to be modeled. The linear logistic model has the form
![\[ \mbox{logit} (\pi ) \equiv \log \left(\frac{\pi }{1-\pi }\right)= \alpha + \bbeta ’\mb{x} \]](images/statug_logistic0003.png)
where  is the intercept parameter and
is the intercept parameter and 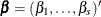 is the vector of s slope parameters. Notice that the LOGISTIC procedure, by default, models the probability of the lower response levels.
is the vector of s slope parameters. Notice that the LOGISTIC procedure, by default, models the probability of the lower response levels.
The logistic model shares a common feature with a more general class of linear models: a function 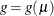 of the mean of the response variable is assumed to be linearly related to the explanatory variables. Because the mean
of the mean of the response variable is assumed to be linearly related to the explanatory variables. Because the mean 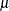 implicitly depends on the stochastic behavior of the response, and the explanatory variables are assumed to be fixed, the
function g provides the link between the random (stochastic) component and the systematic (deterministic) component of the response
variable Y. For this reason, Nelder and Wedderburn (1972) refer to
implicitly depends on the stochastic behavior of the response, and the explanatory variables are assumed to be fixed, the
function g provides the link between the random (stochastic) component and the systematic (deterministic) component of the response
variable Y. For this reason, Nelder and Wedderburn (1972) refer to 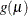 as a link function. One advantage of the logit
function over other link functions is that differences on the logistic scale are interpretable regardless of whether the data
are sampled prospectively or retrospectively (McCullagh and Nelder 1989, Chapter 4). Other link functions that are widely used in practice are the probit function and the complementary log-log
function. The LOGISTIC procedure enables you to choose one of these link functions, resulting in fitting a broader class of
binary response models of the form
as a link function. One advantage of the logit
function over other link functions is that differences on the logistic scale are interpretable regardless of whether the data
are sampled prospectively or retrospectively (McCullagh and Nelder 1989, Chapter 4). Other link functions that are widely used in practice are the probit function and the complementary log-log
function. The LOGISTIC procedure enables you to choose one of these link functions, resulting in fitting a broader class of
binary response models of the form
![\[ g(\pi )=\alpha + \bbeta ’ \mb{x} \]](images/statug_logistic0009.png)
For ordinal response models, the response, Y, of an individual or an experimental unit might be restricted to one of a (usually small) number of ordered values, denoted
for convenience by 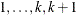 . For example, the severity of coronary disease can be classified into three response categories as 1 = no disease, 2 = angina
pectoris, and 3 = myocardial infarction. The LOGISTIC procedure fits a common slopes cumulative model, which is a parallel
lines regression model based on the cumulative probabilities of the response categories rather than on their individual probabilities.
The cumulative model defines k response functions of the form
. For example, the severity of coronary disease can be classified into three response categories as 1 = no disease, 2 = angina
pectoris, and 3 = myocardial infarction. The LOGISTIC procedure fits a common slopes cumulative model, which is a parallel
lines regression model based on the cumulative probabilities of the response categories rather than on their individual probabilities.
The cumulative model defines k response functions of the form
![\[ g(\Pr ({Y} \le i~ |~ \mb{x}))= \alpha _{i} + \bbeta ’ \mb{x} , \quad i=1,\ldots ,k \]](images/statug_logistic0011.png)
where 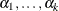 are k intercept parameters and
are k intercept parameters and 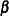 is a common vector of slope parameters. You can specify cumulative logit, cumulative probit, and cumulative complementary
log-log links. These models have been considered by many researchers. Aitchison and Silvey (1957) and Ashford (1959) employ a probit scale and provide a maximum likelihood analysis; Walker and Duncan (1967) and Cox and Snell (1989) discuss the use of the log odds scale. For the log odds scale, the cumulative logit model is often referred to as the proportional odds model.
is a common vector of slope parameters. You can specify cumulative logit, cumulative probit, and cumulative complementary
log-log links. These models have been considered by many researchers. Aitchison and Silvey (1957) and Ashford (1959) employ a probit scale and provide a maximum likelihood analysis; Walker and Duncan (1967) and Cox and Snell (1989) discuss the use of the log odds scale. For the log odds scale, the cumulative logit model is often referred to as the proportional odds model.
Besides the three preceding cumulative response models, the LOGISTIC procedure provides a fourth ordinal response model, the common slopes adjacent-category logit model. This model uses the adjacent-category logit link function, which is based on the individual probabilities of the response categories and has the form
![\[ \log \left(\frac{\Pr ({Y} = i~ |~ \mb{x})}{\Pr ({Y} = i+1~ |~ \mb{x})}\right)= \alpha _{i} + \bbeta ’ \mb{x} , \quad i=1,\ldots ,k \]](images/statug_logistic0014.png)
You can use this model when you want to interpret results in terms of the individual response categories instead of cumulative categories.
For nominal response logistic models, where the 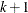 possible responses have no natural ordering, the logit model can be extended to a multinomial model known as a generalized or baseline-category logit model, which has the form
possible responses have no natural ordering, the logit model can be extended to a multinomial model known as a generalized or baseline-category logit model, which has the form
![\[ \log \left(\frac{\Pr ({Y} = i~ |~ \mb{x})}{\Pr ({Y} = k+1~ |~ \mb{x})}\right)= \alpha _{i} + \bbeta _{i} ’ \mb{x} , \quad i=1,\ldots ,k \]](images/statug_logistic0016.png)
where the are k intercept parameters and the  are k vectors of slope parameters. These models are a special case of the discrete choice or conditional logit models introduced by McFadden (1974).
are k vectors of slope parameters. These models are a special case of the discrete choice or conditional logit models introduced by McFadden (1974).
The LOGISTIC procedure enables you to relax the parallel lines assumption in ordinal response models, and apply the parallel lines assumption to nominal response models, by specifying parallel line, constrained, and unconstrained parameters as in Peterson and Harrell (1990) and Agresti (2010). The linear predictors for these models have the form
![\[ \alpha _{i} + \bbeta _1 ’ \mb{x}_1 + \bbeta _{2i} ’ \mb{x}_2 + (\bGamma _{i} \bbeta _3) ’ \mb{x}_3 , \quad i=1,\ldots ,k \]](images/statug_logistic0018.png)
where the 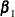 are the parallel line (equal slope) parameters, the
are the parallel line (equal slope) parameters, the  are k vectors of unequal slope (unconstrained) parameters, and the
are k vectors of unequal slope (unconstrained) parameters, and the 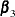 are the constrained slope parameters whose constraints are provided by the diagonal
are the constrained slope parameters whose constraints are provided by the diagonal 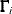 matrix. To fit these models, you specify the EQUALSLOPES
and UNEQUALSLOPES
options in the MODEL statement. Models that have cumulative logits and both equal and unequal slopes parameters are called
partial proportional odds models, and models that have only unequal slope parameters are called general models.
matrix. To fit these models, you specify the EQUALSLOPES
and UNEQUALSLOPES
options in the MODEL statement. Models that have cumulative logits and both equal and unequal slopes parameters are called
partial proportional odds models, and models that have only unequal slope parameters are called general models.
The LOGISTIC procedure fits linear logistic regression models for discrete response data by the method of maximum likelihood. It can also perform conditional logistic regression for binary response data and exact logistic regression for binary and nominal response data. The maximum likelihood estimation is carried out with either the Fisher scoring algorithm or the Newton-Raphson algorithm, and you can perform the bias-reducing penalized likelihood optimization as discussed by Firth (1993) and Heinze and Schemper (2002). You can specify starting values for the parameter estimates.
Any term specified in the model is referred to as an effect. The LOGISTIC procedure enables you to specify categorical variables (also known as classification or CLASS variables) and continuous variables as explanatory effects. You can also specify more complex model terms such as interactions and nested terms in the same way as in the GLM procedure. You can create complex constructed effects with the EFFECT statement. An effect in the model that is not an interaction or a nested term or a constructed effect is referred to as a main effect.
The LOGISTIC procedure allows either a full-rank parameterization or a less-than-full-rank parameterization of the CLASS variables. The full-rank parameterization offers eight coding methods: effect, reference, ordinal, polynomial, and orthogonalizations of these. The effect coding is the same method that is used by default in the CATMOD procedure. The less-than-full-rank parameterization, often called dummy coding, is the same coding as that used by default in the GENMOD, GLIMMIX, GLM, HPGENSELECT, and HPLOGISTIC procedures.
The LOGISTIC procedure provides four effect selection methods: forward selection, backward elimination, stepwise selection, and best subset selection. The best subset selection is based on the likelihood score statistic. This method identifies a specified number of best models containing one, two, three effects, and so on, up to a single model containing effects for all the explanatory variables.
The LOGISTIC procedure has some additional options to control how to move effects in and out of a model with the forward selection, backward elimination, or stepwise selection model-building strategies. When there are no interaction terms, a main effect can enter or leave a model in a single step based on the p-value of the score or Wald statistic. When there are interaction terms, the selection process also depends on whether you want to preserve model hierarchy. These additional options enable you to specify whether model hierarchy is to be preserved, how model hierarchy is applied, and whether a single effect or multiple effects can be moved in a single step.
Odds ratio estimates are displayed along with parameter estimates. You can also specify the change in the continuous explanatory main effects for which odds ratio estimates are desired. Confidence intervals for the regression parameters and odds ratios can be computed based either on the profile-likelihood function or on the asymptotic normality of the parameter estimators. You can also produce odds ratios for effects that are involved in interactions or nestings, and for any type of parameterization of the CLASS variables.
Various methods to correct for overdispersion are provided, including Williams’ method for grouped binary response data. The adequacy of the fitted model can be evaluated by various goodness-of-fit tests, including the Hosmer-Lemeshow test for binary response data.
Like many procedures in SAS/STAT software that enable the specification of CLASS variables, the LOGISTIC procedure provides a CONTRAST statement for specifying customized hypothesis tests concerning the model parameters. The CONTRAST statement also provides estimation of individual rows of contrasts, which is particularly useful for obtaining odds ratio estimates for various levels of the CLASS variables. The LOGISTIC procedure also provides testing capability through the ESTIMATE and TEST statements. Analyses of LS-means are enabled with the LSMEANS , LSMESTIMATE , and SLICE statements.
You can perform a conditional logistic regression on binary response data by specifying the STRATA statement. This enables you to perform matched-set and case-control analyses. The number of events and nonevents can vary across the strata. Many of the features available with the unconditional analysis are also available with a conditional analysis.
The LOGISTIC procedure enables you to perform exact logistic regression, also known as exact conditional logistic regression, by specifying one or more EXACT statements. You can test individual parameters or conduct a joint test for several parameters. The procedure computes two exact tests: the exact conditional score test and the exact conditional probability test. You can request exact estimation of specific parameters and corresponding odds ratios where appropriate. Point estimates, standard errors, and confidence intervals are provided. You can perform stratified exact logistic regression by specifying the STRATA statement.
Further features of the LOGISTIC procedure enable you to do the following:
-
control the ordering of the response categories
-
compute a generalized R-square measure for the fitted model
-
reclassify binary response observations according to their predicted response probabilities
-
test linear hypotheses about the regression parameters
-
create a data set for producing a receiver operating characteristic (ROC) curve for each fitted model
-
specify contrasts to compare several receiver operating characteristic curves
-
create a data set containing the estimated response probabilities, residuals, and influence diagnostics
-
score a data set by using a previously fitted model
-
store the model for input to the PLM procedure
The LOGISTIC procedure uses ODS Graphics to create graphs as part of its output. For general information about ODS Graphics, see Chapter 21: Statistical Graphics Using ODS. For more information about the plots implemented in PROC LOGISTIC, see the section ODS Graphics.
The remaining sections of this chapter describe how to use PROC LOGISTIC and discuss the underlying statistical methodology. The section Getting Started: LOGISTIC Procedure introduces PROC LOGISTIC with an example for binary response data. The section Syntax: LOGISTIC Procedure describes the syntax of the procedure. The section Details: LOGISTIC Procedure summarizes the statistical technique employed by PROC LOGISTIC. The section Examples: LOGISTIC Procedure illustrates the use of the LOGISTIC procedure.
For more examples and discussion on the use of PROC LOGISTIC, see Stokes, Davis, and Koch (2012); Allison (1999); SAS Institute Inc. (1995).