The LOGISTIC Procedure
- Overview
- Getting Started
-
Syntax
 PROC LOGISTIC StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementEFFECT StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementODDSRATIO StatementOUTPUT StatementROC StatementROCCONTRAST StatementSCORE StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement
PROC LOGISTIC StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementEFFECT StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementODDSRATIO StatementOUTPUT StatementROC StatementROCCONTRAST StatementSCORE StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement -
DetailsMissing ValuesResponse Level OrderingLink Functions and the Corresponding DistributionsDetermining Observations for Likelihood ContributionsIterative Algorithms for Model FittingConvergence CriteriaExistence of Maximum Likelihood EstimatesEffect-Selection MethodsModel Fitting InformationGeneralized Coefficient of DeterminationScore Statistics and TestsConfidence Intervals for ParametersOdds Ratio EstimationRank Correlation of Observed Responses and Predicted ProbabilitiesLinear Predictor, Predicted Probability, and Confidence LimitsClassification TableOverdispersionThe Hosmer-Lemeshow Goodness-of-Fit TestReceiver Operating Characteristic CurvesTesting Linear Hypotheses about the Regression CoefficientsJoint Tests and Type 3 TestsRegression DiagnosticsScoring Data SetsConditional Logistic RegressionExact Conditional Logistic RegressionInput and Output Data SetsComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesStepwise Logistic Regression and Predicted ValuesLogistic Modeling with Categorical PredictorsOrdinal Logistic RegressionNominal Response Data: Generalized Logits ModelStratified SamplingLogistic Regression DiagnosticsROC Curve, Customized Odds Ratios, Goodness-of-Fit Statistics, R-Square, and Confidence LimitsComparing Receiver Operating Characteristic CurvesGoodness-of-Fit Tests and SubpopulationsOverdispersionConditional Logistic Regression for Matched Pairs DataExact Conditional Logistic RegressionFirth’s Penalized Likelihood Compared with Other ApproachesComplementary Log-Log Model for Infection RatesComplementary Log-Log Model for Interval-Censored Survival TimesScoring Data SetsUsing the LSMEANS StatementPartial Proportional Odds Model
- References
Confidence Intervals for Parameters
There are two methods of computing confidence intervals for the regression parameters. One is based on the profile-likelihood function, and the other is based on the asymptotic normality of the parameter estimators. The latter is not as time-consuming as the former, because it does not involve an iterative scheme; however, it is not thought to be as accurate as the former, especially with small sample size. You use the CLPARM= option to request confidence intervals for the parameters.
Likelihood Ratio-Based Confidence Intervals
The likelihood ratio-based confidence interval is also known as the profile-likelihood confidence interval. The construction
of this interval is derived from the asymptotic 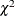 distribution of the generalized likelihood ratio test (Venzon and Moolgavkar 1988). Suppose that the parameter vector is
distribution of the generalized likelihood ratio test (Venzon and Moolgavkar 1988). Suppose that the parameter vector is 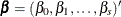 and you want to compute a confidence interval for
and you want to compute a confidence interval for 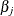 . The profile-likelihood function for
. The profile-likelihood function for 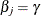 is defined as
is defined as
![\[ l_ j^*(\gamma ) = \max _{\bbeta \in {\mc{B}}_ j(\gamma )} l(\bbeta ) \]](images/statug_logistic0283.png)
where 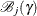 is the set of all
is the set of all 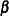 with the jth element fixed at
with the jth element fixed at 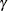 , and
, and 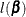 is the log-likelihood function for . If
is the log-likelihood function for . If 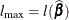 is the log likelihood evaluated at the maximum likelihood estimate
is the log likelihood evaluated at the maximum likelihood estimate 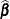 , then
, then 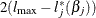 has a limiting chi-square distribution with one degree of freedom if is the true parameter value. Let
has a limiting chi-square distribution with one degree of freedom if is the true parameter value. Let 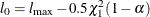 , where
, where 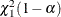 is the
is the 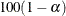 th percentile of the chi-square distribution with one degree of freedom. A % confidence interval for is
th percentile of the chi-square distribution with one degree of freedom. A % confidence interval for is
![\[ \{ \gamma : l_ j^*(\gamma ) \geq l_{0} \} \]](images/statug_logistic0290.png)
The endpoints of the confidence interval are found by solving numerically for values of that satisfy equality in the preceding relation. To obtain an iterative algorithm for computing the confidence limits, the
log-likelihood function in a neighborhood of is approximated by the quadratic function
![\[ \tilde{l}(\bbeta + \bdelta ) = l(\bbeta ) + \bdelta ’\mb{g} + \frac{1}{2}\bdelta ’ \bV \bdelta \]](images/statug_logistic0291.png)
where 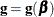 is the gradient vector and
is the gradient vector and 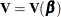 is the Hessian matrix. The increment
is the Hessian matrix. The increment 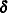 for the next iteration is obtained by solving the likelihood equations
for the next iteration is obtained by solving the likelihood equations
![\[ \frac{d}{d\bdelta }\{ \tilde{l}(\bbeta + \bdelta ) + \lambda ( \mb{e}_ j’\bdelta - \gamma )\} = \bm {0} \]](images/statug_logistic0295.png)
where 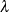 is the Lagrange multiplier,
is the Lagrange multiplier, 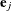 is the jth unit vector, and is an unknown constant. The solution is
is the jth unit vector, and is an unknown constant. The solution is
![\[ \bdelta = -\bV ^{-1}(\mb{g} + \lambda \mb{e}_ j) \]](images/statug_logistic0298.png)
By substituting this into the equation 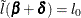 , you can estimate as
, you can estimate as
![\[ \lambda = \pm \biggl (\frac{2(l_0 - l(\bbeta ) + \frac{1}{2}\mb{g}'\bV ^{-1}\mb{g})}{\mb{e}_ j'\bV ^{-1}\mb{e}_ j}\biggr )^{ \frac{1}{2}} \]](images/statug_logistic0300.png)
The upper confidence limit for 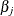 is computed by starting at the maximum likelihood estimate of and iterating with positive values of until convergence is attained. The process is repeated for the lower confidence limit by using negative values of .
is computed by starting at the maximum likelihood estimate of and iterating with positive values of until convergence is attained. The process is repeated for the lower confidence limit by using negative values of .
Convergence is controlled by the value  specified with the PLCONV=
option in the MODEL
statement (the default value of is 1E–4). Convergence is declared on the current iteration if the following two conditions are satisfied:
specified with the PLCONV=
option in the MODEL
statement (the default value of is 1E–4). Convergence is declared on the current iteration if the following two conditions are satisfied:
![\[ |l(\bbeta )-l_{0}| \leq \epsilon \]](images/statug_logistic0303.png)
and
![\[ ({\mb{g}} + \lambda {\mb{e}_ j})’{\bV }^{-1}({\mb{g}} + \lambda {\mb{e}_ j}) \leq \epsilon \]](images/statug_logistic0304.png)
Wald Confidence Intervals
Wald confidence intervals are sometimes called the normal confidence intervals. They are based on the asymptotic normality
of the parameter estimators. The % Wald confidence interval for is given by
![\[ {\widehat{\beta }}_ j \pm z_{1-\alpha /2}\widehat{\sigma }_ j \]](images/statug_logistic0305.png)
where 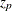 is the 100pth percentile of the standard normal distribution,
is the 100pth percentile of the standard normal distribution, 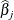 is the maximum likelihood estimate of , and
is the maximum likelihood estimate of , and 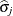 is the standard error estimate of .
is the standard error estimate of .