The QLIM Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsOrdinal Discrete Choice ModelingLimited Dependent Variable ModelsStochastic Frontier Production and Cost ModelsHeteroscedasticity and Box-Cox TransformationBivariate Limited Dependent Variable ModelingSelection ModelsMultivariate Limited Dependent ModelsVariable SelectionTests on ParametersEndogeneity and Instrumental VariablesPanel Data AnalysisBayesian AnalysisPrior DistributionsAutomated MCMCMarginal LikelihoodStandard DistributionsOutput to SAS Data SetOUTEST= Data SetNamingODS Table NamesODS Graphics
-
Examples
- References
ENDOGENOUS Statement
-
ENDOGENOUS variables ~ options ;
The ENDOGENOUS statement specifies the type of dependent variables that appear on the left-hand side of the equation. Endogenous variables listed refer to the dependent variables that appear on the left-hand side of the equation.
Discrete Variable Options
Censored Variable Options
Truncated Variable Options
Stochastic Frontier Variable Options
Selection Options
Endogeneity and Overidentification Test Options
- ENDOTEST (regressors)
-
requests the test of endogeneity for a list of regressors in the model. More specifically, this option tests the null hypothesis that the specified regressors are exogenous. Each of these regressors must also have a model of its own. The former model is considered the structural model, and the latter models are considered reduced form models.
The following example illustrates the use of the ENDOTEST option by testing whether the regressors
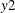 and
and 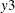 are endogenous in the model for
are endogenous in the model for 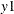 :
:
proc qlim; model y1 = y2 y3 x1; model y2 = x1 x2 x3 x4 x5; model y3 = x1 x2 x3 x4 x5; endogenous y1 ~ endotest(y2 y3); run;The ENDOTEST option is not available when you specify the SELECT or FRONTIER option. You can specify the ENDOTEST option only once for each ENDOGENOUS statement.
For more information about the test for endogeneity, see the section Test for Endogeneity.
- OVERID (variables)
-
requests the overidentification test for a list of variables. These variables are the overidentifying instrumental variables that you provide from the reduced form models. For more information, see the section Overidentification Test.
The following example illustrates the use of the OVERID option:
proc qlim; model y1 = y2 y3 x1; model y2 = x1 x2 x3 x4 x5; model y3 = x1 x2 x3 x4 x5; endogenous y1 ~ overid(y2.x4 y3.x5); run;The regressors
and in the model for are the endogenous variables. Therefore, each of these variables has its own models, which are considered reduced form models.
The overidentifying instrumental variables are 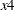 and
and 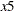 . If you specify the OVERID option as
. If you specify the OVERID option as
endogenous y1 ~ overid(y2.x4 y2.x5);then you consider only the regressor
to be endogenous, and the model for is ignored during the testing process.
The OVERID option is not available when you specify the SELECT or FRONTIER option. You can specify the OVERID option only once for each ENDOGENOUS statement.