The SPP Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsTesting for Complete Spatial RandomnessExploring Interpoint InteractionDistance Functions for Multitype Point PatternsBorder Edge Correction for Distance FunctionsConfidence Intervals for Summary StatisticsRipley-Rasson Window EstimatorCovariate Dependence TestsNonparametric Intensity EstimationInhomogeneous Poisson Process Model FittingNegative Binomial ModelingOutput Data SetsDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
Nearest-Neighbor Distance Functions
The SPP procedure implements the following nearest-neighbor distance functions:
-
empty-space F function
-
nearest-neighbor G function
-
J function
A typical test that uses any nearest-neighbor function compares the empirical distribution function with the corresponding
function for a homogeneous Poisson process that has first-order intensity 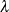 . Usually, the first-order intensity is obtained as the number of observations per unit of area,
. Usually, the first-order intensity is obtained as the number of observations per unit of area, 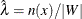 .
.
The empty-space F function is defined as the empirical distribution function of the observed empty-space distances, 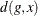 , which is measured from a set of reference grid points g to the nearest point in the point pattern. The empty-space distance can be defined as
, which is measured from a set of reference grid points g to the nearest point in the point pattern. The empty-space distance can be defined as
![\[ d(g,x) = \min \{ ||g-x_ i||, \text {for }x_ i \in x\} \]](images/statug_spp0034.png)
In practice, the computation of the empty-space F function also involves an edge correction. The edge-corrected empty-space F function is defined as
![\[ \hat{F}(r) = \sum _ j e(g_ j,r) \Strong{1} \{ d(g_ j,x) \leq r\} \]](images/statug_spp0035.png)
where 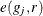 is an edge correction. PROC SPP implements the border edge correction (Illian et al. 2008, p. 185–186) as described in the section Border Edge Correction for Distance Functions.
is an edge correction. PROC SPP implements the border edge correction (Illian et al. 2008, p. 185–186) as described in the section Border Edge Correction for Distance Functions.
For a homogeneous Poisson process that has first-order intensity , the F function is
![\[ F_ P(r) = 1 - \exp {(-\lambda \pi r^{2})} \]](images/statug_spp0037.png)
You compare the empirical and Poisson empty-space F function by using the EDF and the P-P plot in the F function summary
panel plot. Values of 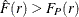 suggest a regularly spaced pattern, and values of
suggest a regularly spaced pattern, and values of 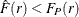 suggest a clustered pattern (Baddeley and Turner 2005).
suggest a clustered pattern (Baddeley and Turner 2005).
The nearest-neighbor G function is the empirical distribution of the observed nearest-neighbor distance of the points within the point pattern. In practice, the G function also involves an edge correction and is defined as
![\[ \hat{G}(r) = \sum _ i e(x_ i,r) \Strong{1} \{ d_ i \leq r\} \]](images/statug_spp0040.png)
where 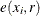 is the border edge correction (Illian et al. 2008, p. 185-186) as described in the section Border Edge Correction for Distance Functions and
is the border edge correction (Illian et al. 2008, p. 185-186) as described in the section Border Edge Correction for Distance Functions and 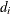 is the distance to the nearest neighbor for the ith point.
is the distance to the nearest neighbor for the ith point.
For a homogeneous Poisson process that has first-order intensity , the G function can be defined as
![\[ G_ P(r) = 1 - \exp {(-\lambda \pi r^{2})} \]](images/statug_spp0043.png)
The interpretation of 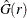 is opposite to the interpretation of
is opposite to the interpretation of 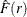 . That is, values of
. That is, values of 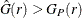 imply a clustered pattern, and values of
imply a clustered pattern, and values of 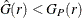 suggest a regular pattern (Baddeley and Turner 2005).
suggest a regular pattern (Baddeley and Turner 2005).
The third type of nearest-neighbor distance function is the J function, which is defined as a combination of both the F and
G functions (Baddeley et al. 2000). The J function is defined for all distances r such that 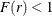 . The J function can be defined as
. The J function can be defined as
![\[ J(r) = \frac{1-G(r)}{1-F(r)} \]](images/statug_spp0049.png)
For a homogeneous Poisson process, 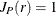 . When
. When 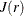 takes values greater than 1, regularity is indicated; when takes values less than 1, the underlying process is more clustered than expected. As can be seen from the expression of , the estimate is an uncorrected estimate of the J-function and hence its computation does not require an edge correction (Baddeley
et al. 2000).
takes values greater than 1, regularity is indicated; when takes values less than 1, the underlying process is more clustered than expected. As can be seen from the expression of , the estimate is an uncorrected estimate of the J-function and hence its computation does not require an edge correction (Baddeley
et al. 2000).