The QUANTSELECT Procedure

MODEL Statement
-
MODEL dependent = <effects> / <options>;
The MODEL statement names the dependent variable and the covariate effects, including covariates, main effects, constructed effects, interactions, and nested effects; see the section Specification of Effects in Chapter 46: The GLM Procedure, for more information. If you omit the explanatory effects, PROC QUANTSELECT fits an intercept-only model.
After the keyword MODEL, specify the dependent (response) variable, followed by an equal sign, followed by the explanatory effects.
Table 96.9 summarizes the options available in the MODEL statement.
Table 96.9: MODEL Statement Options
|
Option |
Description |
|---|---|
|
Specifies the level of effect selection detail to display |
|
|
Specifies hierarchy of effects to impose |
|
|
Specifies models without an explicit intercept |
|
|
Specifies quantile levels to be applied |
|
|
Specifies effect selection method |
|
|
Specifies additional statistics to be displayed |
|
|
Specifies the test type for computing significance levels |
The following list provides details about the options that you can specify in the MODEL statement after a slash (/):
- DETAILS=level | STEPS <(step options)>
-
specifies the level of effect selection detail that is displayed, where level can be ALL, STEPS, or SUMMARY. The default if the DETAILS= option is omitted is DETAILS=SUMMARY that produces only the selection summary table. The DETAILS=ALL option produces the following:
-
entry and removal statistics for each variable that is selected in the model building process
-
fit statistics and parameter estimates
-
entry and removal statistics for the top five candidates for inclusion or exclusion at each step
-
a selection summary table
The option DETAILS=STEPS <(step options)> provides the step information and the selection summary table. The following suboptions can be specified within parentheses after the DETAILS=STEPS option:
-
-
HIERARCHY=keyword
HIER=keyword -
specifies whether and how the model hierarchy requirement is applied. This option also controls whether a single effect or multiple effects are allowed to enter or leave the model in one step. You can specify that only CLASS effects, or both CLASS and continuous effects, be subject to the hierarchy requirement. This option is ignored unless you also specify one of the following options: SELECTION= FORWARD, SELECTION= BACKWARD, or SELECTION= STEPWISE.
Model hierarchy refers to the requirement that for any term to be in the model, all model effects contained in the term must be present in the model. For example, in order for the interaction A*B to enter the model, the main effects A and B must be in the model. Likewise, neither effect A nor effect B can leave the model while the interaction A*B is in the model.
You can specify the following keywords:
The default is HIERARCHY=NONE.
- NOINT
-
suppresses the intercept term that is otherwise included in the model.
-
QUANTILES=number-list | PROCESS <(option)>
QUANTILE=<number-list | PROCESS <(option)>> -
specifies the quantile levels for the quantile regression. You can specify any number of quantile levels in
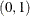 . You can also specify QUANTILE=0 or QUANTILE=1 for the ALGORITHM=SIMPLEX algorithm. See the section Quantile Regression for Extremal Quantile Levels for more information about extremal quantile levels.
. You can also specify QUANTILE=0 or QUANTILE=1 for the ALGORITHM=SIMPLEX algorithm. See the section Quantile Regression for Extremal Quantile Levels for more information about extremal quantile levels.
If you do not specify this option, the QUANTSELECT procedure performs median regression effect selection that corresponds to QUANTILES=0.5.
If you specify the QUANTILES=PROCESS option, the QUANTSELECT procedure performs effect selection for quantile process regression. See the section Quantile Process Regression for more information about quantile process regression. The QUANTILES=PROCESS option cannot be used with LASSO selection methods. You can specify the following option in parentheses after QUANTILES=PROCESS.
- NTAU=n | ALL
-
specifies how many quantile levels that you expect to cover for the quantile process. If you specify NTAU=ALL, the QUANTSELECT procedure performs effect selection for accurate quantile process regression. If you specify NTAU=n, the QUANTSELECT procedure performs effect selection for approximate quantile process regression. The approximate quantile process is computed at n equally spaced quantile levels:
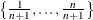 besides three control quantile levels
besides three control quantile levels 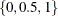 . If the number of observations for training is more than 1000, by default, NTAU=500. Otherwise, the default is NTAU=ALL.
. If the number of observations for training is more than 1000, by default, NTAU=500. Otherwise, the default is NTAU=ALL.
- SELECTION=method <(method-options)>
-
specifies the method used to select the model, optionally followed by parentheses that enclose method-options that apply to the specified method. The default is SELECTION=STEPWISE.
You can specify the following methods, which are explained in detail in the section Effect Selection Methods.
- NONE
-
specifies full model fitting without effect selection.
- FORWARD
-
specifies forward selection. This method starts with no effects in the model and adds effects.
- BACKWARD
-
specifies backward elimination. This method starts with all effects in the model and deletes effects.
- STEPWISE
-
specifies stepwise regression. This is similar to the FORWARD method except that effects already in the model do not necessarily stay there.
- LASSO
-
specifies a method that adds and deletes parameters based on a version of estimated check risk where the weighted L1-norm of certain weighted regression coefficients is penalized. For more information, see the section LASSO Method (LASSO). If the model contains CLASS variables or constructed effects, these CLASS variables or constructed effects are split into separate covariates.
Table 96.10 lists the applicable method-options for each method.
Table 96.10: Applicable method-options for Each method
method-option
FORWARD
BACKWARD
STEPWISE
LASSO
ADAPTIVE
x
CHOOSE=
x
x
x
x
INCLUDE=
x
x
x
x
MAXSTEP=
x
x
x
x
SELECT=
x
x
x
SLENTRY=
x
x
SLSTAY=
x
x
STOP=
x
x
x
x
STOPHORIZON=
x
x
x
x
You can specify the following method-option in parentheses after the method. As described in Table 96.10, not all method-options apply to every SELECTION= method.
-
STAT=name | (names)
STATS=name | (names) -
specifies which model fit statistics to display in the selection summary table. To specify multiple model fit statistics, specify a list of names in parentheses. If you omit this option, the default set of statistics that are displayed in these tables includes all the criteria that are specified in any of the CHOOSE= , SELECT= , and STOP= method-options.
You can specify the following values for name:
- ADJR1
- AIC
- AICC
- ACL
-
displays the average check losses for the training, test, and validation data. The ACL statistics for the test and validation data are reported only if you have specified the TESTDATA= option or the VALDATA= option in the PROC QUANTSELECT statement or if you have reserved part of the input data for testing or validation by using either a PARTITION statement or a
_ROLE_variable in the input data. - R1
- SBC
The statistics ADJR1, AIC, AICC, and SBC can be computed with little computation cost. However, computing ACL for test and validation data when these are not used in any of the CHOOSE= , SELECT= , and STOP= method-options can hurt performance.
- TEST=name
-
specifies the test type for computing significance levels.
You can specify the following values for name:
- LR1
-
specifies the likelihood ratio test Type I. The LR1 test score is
![\[ {2(D_1(\tau )-D_2(\tau ))\over \tau (1-\tau )\hat{s}} \]](images/statug_qrsel0014.png)
where
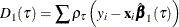 is the sum of check losses for the reduced model,
is the sum of check losses for the reduced model, 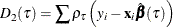 is the sum of check losses for the extended model, and
is the sum of check losses for the extended model, and 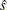 is the estimated sparsity function. See the section Quasi-Likelihood Ratio Tests for more information.
is the estimated sparsity function. See the section Quasi-Likelihood Ratio Tests for more information.
- LR2
-
specifies the likelihood ratio test Type II. The LR2 test score is
![\[ {2D_2(\tau )\left(\log (D_1(\tau ))-\log (D_2(\tau ))\right)\over \tau (1-\tau )\hat{s}}. \]](images/statug_qrsel0018.png)
See the section Quasi-Likelihood Ratio Tests for more information.