The CALIS Procedure
-
Overview

-
Getting Started
-
Syntax
Classes of Statements in PROC CALIS Single-Group Analysis Syntax Multiple-Group Multiple-Model Analysis Syntax PROC CALIS Statement BOUNDS Statement BY Statement COSAN Statement COV Statement DETERM Statement EFFPART Statement FACTOR Statement FITINDEX Statement FREQ Statement GROUP Statement LINCON Statement LINEQS Statement LISMOD Statement LMTESTS Statement MATRIX Statement MEAN Statement MODEL Statement MSTRUCT Statement NLINCON Statement NLOPTIONS Statement OUTFILES Statement PARAMETERS Statement PARTIAL Statement PATH Statement PCOV Statement PVAR Statement RAM Statement REFMODEL Statement RENAMEPARM Statement SAS Programming Statements SIMTESTS Statement STD Statement STRUCTEQ Statement TESTFUNC Statement VAR Statement VARIANCE Statement VARNAMES Statement WEIGHT Statement
-
Details
Input Data Sets Output Data Sets The COSAN Model The FACTOR Model The LINEQS Model The LISMOD Model and Submodels The MSTRUCT Model The PATH Model The RAM Model Naming Variables and Parameters Setting Constraints on Parameters Automatic Variable Selection Estimation Criteria Relationships among Estimation Criteria Gradient, Hessian, Information Matrix, and Approximate Standard Errors Counting the Degrees of Freedom Assessment of Fit Total, Direct, and Indirect Effects Standardized Solutions Modification Indices Missing Values and the Analysis of Missing Patterns Measures of Multivariate Kurtosis Initial Estimates Use of Optimization Techniques Computational Problems Displayed Output ODS Table Names ODS Graphics
-
Examples
Estimating Covariances and Correlations Estimating Covariances and Means Simultaneously Testing Uncorrelatedness of Variables Testing Covariance Patterns Testing Some Standard Covariance Pattern Hypotheses Linear Regression Model Multivariate Regression Models Measurement Error Models Testing Specific Measurement Error Models Measurement Error Models with Multiple Predictors Measurement Error Models Specified As Linear Equations Confirmatory Factor Models Confirmatory Factor Models: Some Variations The Full Information Maximum Likelihood Method Comparing the ML and FIML Estimation Path Analysis: Stability of Alienation Simultaneous Equations with Mean Structures and Reciprocal Paths Fitting Direct Covariance Structures Confirmatory Factor Analysis: Cognitive Abilities Testing Equality of Two Covariance Matrices Using a Multiple-Group Analysis Testing Equality of Covariance and Mean Matrices between Independent Groups Illustrating Various General Modeling Languages Testing Competing Path Models for the Career Aspiration Data Fitting a Latent Growth Curve Model Higher-Order and Hierarchical Factor Models Linear Relations among Factor Loadings Multiple-Group Model for Purchasing Behavior Fitting the RAM and EQS Models by the COSAN Modeling Language Second-Order Confirmatory Factor Analysis Linear Relations among Factor Loadings: COSAN Model Specification Ordinal Relations among Factor Loadings Longitudinal Factor Analysis
- References
| Automatic Variable Selection |
When you specify your model, you use the main and subsidiary model statements to define variable relationships and parameters. PROC CALIS checks the variables mentioned in these statements against the variable list of the input data set. If a variable in your model is also found in your data set, PROC CALIS knows that it is a manifest variable. Otherwise, it is either a latent variable or an invalid variable.
To save computational resources, only manifest variables defined in your model are automatically selected for analysis. For example, even if you have  variables in your input data set, only a covariance matrix of
variables in your input data set, only a covariance matrix of 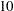 manifest variables is computed for the analysis of the model if only 10 variables are selected for analysis.
manifest variables is computed for the analysis of the model if only 10 variables are selected for analysis.
In some special circumstances, the automatic variable selection performed for the analysis might be a drawback. For example, if you are interested in modification indices connected to some of the variables that are not used in the model, automatic variable selection in the specification stage will exclude those variables from consideration in computing modification indices. Fortunately, a little trick can be done. You can use the VAR statement to include as many exogenous manifest variables as needed. Any variables in the VAR statement that are defined in the input data set but are not used in the main and subsidiary model specification statements are included in the model as exogenous manifest variables.
For example, the first three steps in a stepwise regression analysis of the Werner Blood Chemistry data (Jöreskog and Sörbom; 1988, p. 111) can be performed as follows:
proc calis data=dixon method=gls nobs=180 print mod; var x1-x7; lineqs y = e; variance e = var; run; proc calis data=dixon method=gls nobs=180 print mod; var x1-x7; lineqs y = g1 x1 + e; variance e = var; run; proc calis data=dixon method=gls nobs=180 print mod; var x1-x7; lineqs y = g1 x1 + g6 x6 + e; variance e = var; run;
In the first analysis, no independent manifest variables are included in the regression equation for dependent variable y. However, x1–x7 are specified in the VAR statement so that in computing the Lagrange multiplier tests these variables would be treated as potential predictors in the regression equation for dependent variable y. Similarly, in the next analysis, x1 is already a predictor in the regression equation, while x2–x7 are treated as potential predictors in the LM tests. In the last analysis, x1 and x6 are predictors in the regression equation, while other x-variables are treated as potential predictors in the LM tests.