The CALIS Procedure
-
Overview

-
Getting Started
-
Syntax
Classes of Statements in PROC CALIS Single-Group Analysis Syntax Multiple-Group Multiple-Model Analysis Syntax PROC CALIS Statement BOUNDS Statement BY Statement COSAN Statement COV Statement DETERM Statement EFFPART Statement FACTOR Statement FITINDEX Statement FREQ Statement GROUP Statement LINCON Statement LINEQS Statement LISMOD Statement LMTESTS Statement MATRIX Statement MEAN Statement MODEL Statement MSTRUCT Statement NLINCON Statement NLOPTIONS Statement OUTFILES Statement PARAMETERS Statement PARTIAL Statement PATH Statement PCOV Statement PVAR Statement RAM Statement REFMODEL Statement RENAMEPARM Statement SAS Programming Statements SIMTESTS Statement STD Statement STRUCTEQ Statement TESTFUNC Statement VAR Statement VARIANCE Statement VARNAMES Statement WEIGHT Statement
-
Details
Input Data Sets Output Data Sets The COSAN Model The FACTOR Model The LINEQS Model The LISMOD Model and Submodels The MSTRUCT Model The PATH Model The RAM Model Naming Variables and Parameters Setting Constraints on Parameters Automatic Variable Selection Estimation Criteria Relationships among Estimation Criteria Gradient, Hessian, Information Matrix, and Approximate Standard Errors Counting the Degrees of Freedom Assessment of Fit Total, Direct, and Indirect Effects Standardized Solutions Modification Indices Missing Values and the Analysis of Missing Patterns Measures of Multivariate Kurtosis Initial Estimates Use of Optimization Techniques Computational Problems Displayed Output ODS Table Names ODS Graphics
-
Examples
Estimating Covariances and Correlations Estimating Covariances and Means Simultaneously Testing Uncorrelatedness of Variables Testing Covariance Patterns Testing Some Standard Covariance Pattern Hypotheses Linear Regression Model Multivariate Regression Models Measurement Error Models Testing Specific Measurement Error Models Measurement Error Models with Multiple Predictors Measurement Error Models Specified As Linear Equations Confirmatory Factor Models Confirmatory Factor Models: Some Variations The Full Information Maximum Likelihood Method Comparing the ML and FIML Estimation Path Analysis: Stability of Alienation Simultaneous Equations with Mean Structures and Reciprocal Paths Fitting Direct Covariance Structures Confirmatory Factor Analysis: Cognitive Abilities Testing Equality of Two Covariance Matrices Using a Multiple-Group Analysis Testing Equality of Covariance and Mean Matrices between Independent Groups Illustrating Various General Modeling Languages Testing Competing Path Models for the Career Aspiration Data Fitting a Latent Growth Curve Model Higher-Order and Hierarchical Factor Models Linear Relations among Factor Loadings Multiple-Group Model for Purchasing Behavior Fitting the RAM and EQS Models by the COSAN Modeling Language Second-Order Confirmatory Factor Analysis Linear Relations among Factor Loadings: COSAN Model Specification Ordinal Relations among Factor Loadings Longitudinal Factor Analysis
- References
| COSAN Statement |
- COSAN <VAR=variable-list,> term <
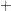 term...> ;
term...> ;
where variable-list is a list of observed variables and term represents either one of the following forms:
matrix_definition <  matrix_definition ...> <mean_definition>
matrix_definition ...> <mean_definition>
or
mean_definition
where matrix_definition is of the following form:
matrix_name <( number_of_columns < , matrix_type < ,transformation >>)>
and mean_definition is one of the following forms:
[ / mean_vector]
or
[ MEAN=mean_vector]
where mean_vector is a vector name.
COSAN stands for covariance structure analysis (McDonald; 1978, 1980). The COSAN model in PROC CALIS is a generalized version of the original COSAN model. See the section The COSAN Model for details of the generalized COSAN model. You can analyze a very wide class of mean and covariance structures with the COSAN modeling language, which consists of the COSAN statement as the main model specification statement and the MATRIX statement as the subsidiary model specification statement. Use the following syntax to specify a COSAN model:
-
COSAN
<VAR=variable-list,> term < term...>
;
- MATRIX matrix-name parameters-in-matrix ;
- /* Repeat the MATRIX statement as needed */ ;
- VARNAMES name_assignments ;
The PROC CALIS statement invokes the COSAN modeling language. You can specify at most one COSAN statement in a model within the scope of either the PROC CALIS statement or a MODEL statement. To complete the COSAN model specification, you might need to add as many MATRIX statements as needed. Optionally, you can provide the variable names for the COSAN model matrices in the VARNAMES statement.
In the COSAN statement, you specify the list of observed variables for analysis in the VAR= option and the formulas for covariance and mean structures in the terms. If specified at all, the VAR= option must be specified at the very beginning of the COSAN statement. The order of the variables in the VAR= option is important. It is the same order assumed for the row and column variables in the mean and covariance structures defined in the terms. If you do not specify the VAR= option, PROC CALIS selects all the numerical variables in the associated groups for analysis. To avoid confusion about the variables being analyzed in the model, it is recommended that you set the VAR= list explicitly in the COSAN statement.
To define the matrix formulas for the covariance and mean structures, you specify the terms, matrix_definitions, and mean_vector in the COSAN statement. The forms of the covariance and mean structures that are supported in PROC CALIS are mentioned in the section The COSAN Model. In each term, you specify the covariance structures by listing the matrices in the matrix_definitions. These matrices must be in the proper order such that their matrix product produces the intended covariance structures. If you want to analyze the corresponding mean structures, specify the trailing mean_vectors in the terms whenever needed.
To illustrate the COSAN statement syntax, consider a factor-analytic model with six variables (var1–var6) and two factors. The covariance structures of the six variables are described by the matrix formula
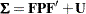 |
where 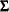 is a
is a 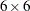 symmetric matrix for the covariance matrix,
symmetric matrix for the covariance matrix, 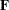 is a
is a 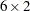 factor loading matrix,
factor loading matrix, 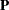 is a
is a 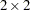 (symmetric) factor covariance matrix, and
(symmetric) factor covariance matrix, and 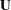 is a
is a 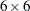 diagonal matrix of unique variances. You can use the following COSAN statement to specify the covariance structures of this factor model:
diagonal matrix of unique variances. You can use the following COSAN statement to specify the covariance structures of this factor model:
cosan var = var1-var6,
F(2,GEN) * P(2,SYM) + U(6,DIA);
In the VAR= option of the COSAN statement, you define a list of six observed variables in the covariance structures. The order of the variables in the VAR= list determines the order of the row variables in the first matrix of each term in the model. That is, both matrices and have these six observed variables as their row variables, which are ordered the same way as in the VAR= list.
Next, you define the formula for the covariance structures by listing the matrices in the desired order up to the central covariance matrix in each term. In the first term of this example, you need to specify only 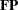 instead of the complete covariance structure formula
instead of the complete covariance structure formula 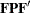 . The reason is that the latter part of the term (that is, after the central covariance matrix) contains only the transpose of the matrices that have already been defined. Hence, PROC CALIS can easily generate the complete term with the nonredundant information given.
. The reason is that the latter part of the term (that is, after the central covariance matrix) contains only the transpose of the matrices that have already been defined. Hence, PROC CALIS can easily generate the complete term with the nonredundant information given.
In each of the matrix_definitions, you can provide the number of columns in the first argument (that is, the number_of_columns field) inside a pair of parentheses. You do not need to provide the number of rows because this information can be deduced from the given covariance structure formula. By using some keywords, you can optionally provide the matrix type in the second argument (that is, the matrix_type field) and the matrix transformation in the third argument (that is, the transformation field).
In the current example, F(2,GEN) represents a general rectangular (GEN) matrix with two columns. Implicitly, it has six rows because it is the first matrix of the first term in the covariance structure formula. P(2,SYM) represents a symmetric (SYM) matrix with two columns. Implicitly, it has two rows because it is premultiplied with , which has two columns. In the second term, U(6,DIA) represents a diagonal (DIA) matrix with six rows and six columns. Because you do not specify the third argument in these matrix_definitions, no transformation is applied to any of the matrices in the covariance structure formula.
PROC CALIS supports the following keywords for matrix_type:
- IDE
specifies an identity matrix. If the matrix is not square, this specification describes an identity submatrix followed by a rectangular zero submatrix.
- ZID
specifies an identity matrix. If the matrix is not square, this specification describes a rectangular zero submatrix followed by an identity submatrix.
- DIA
specifies a diagonal matrix. If the matrix is not square, this specification describes a diagonal submatrix followed by a rectangular zero submatrix.
- ZDI
specifies a diagonal matrix. If the matrix is not square, this specification describes a rectangular zero submatrix followed by a diagonal submatrix.
- LOW
specifies a lower triangular matrix. The matrix can be rectangular.
- UPP
specifies an upper triangular matrix. The matrix can be rectangular.
- SYM
specifies a symmetric matrix. The matrix cannot be rectangular.
- GEN
specifies a general rectangular matrix (default).
If you omit the matrix_type argument, PROC CALIS sets the type of matrix by default. For central covariance matrices, the default for matrix_type is SYM. For all other matrices, the default for matrix_type is GEN. For example, if 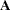 is not a central covariance matrix in the covariance structure formula, the following specifications are equivalent for a general matrix with three columns:
is not a central covariance matrix in the covariance structure formula, the following specifications are equivalent for a general matrix with three columns:
A(3,GEN)
A(3)
A(3,)
A(3, ,)
PROC CALIS supports the following two keywords for transformation:
- INV
uses the inverse of the matrix.
- IMI
uses the inverse of the difference between the identity and the matrix. For example, A(3,GEN,IMI) represents
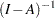 .
.
Both INV or IMI require square (but not necessarily symmetric) matrices to transform. If you omit the transformation argument, no transformation is applied.
Caution: You can specify the same matrix by using the same matrix_name in different locations of the matrix formula in the COSAN statement. The number_of_columns and the matrix_type fields for matrices with identical matrix_names must be consistent. This consistency can be maintained easily by specifying each of these two fields only once in any of the locations of the same matrix. However, there is no restriction on the transformation for the same matrix in different locations. For example, while 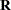 must be the same
must be the same  symmetric matrix throughout the formula in the following specification, the INV transformation of applies only to the matrix in the second term, but not to the same matrix in the first term:
symmetric matrix throughout the formula in the following specification, the INV transformation of applies only to the matrix in the second term, but not to the same matrix in the first term:
cosan var = var1-var6,
B(3,GEN) * R(3,SYM) + H(3,DIA) * R(3,SYM,INV);
Mean and Covariance Structures
Suppose now you want to analyze the mean structures in addition to the covariance structures of the preceding factor model. The mean structure formula for 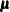 of the observed variables is
of the observed variables is
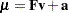 |
where is a 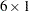 vector for the observed variable means,
vector for the observed variable means,  is a
is a 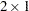 vector for the factor means, and
vector for the factor means, and  is a vector for the intercepts of the observed variables. To include the mean structures in the COSAN model, you need to specify the mean vector at the end of the terms, as shown in the following statement:
is a vector for the intercepts of the observed variables. To include the mean structures in the COSAN model, you need to specify the mean vector at the end of the terms, as shown in the following statement:
cosan var = var1-var6,
F(2,GEN) * P(2,SYM) [/ v] + U(6,DIA) [/ a];
If you take the mean vectors within the brackets away from each of the terms, the formula for the covariance structures is generated as
|
which is exactly the same covariance structure as described in a preceding example. Now, with the mean vectors specified at the end of each term, you analyze the corresponding mean structures simultaneously with the covariance structures.
To generate the mean structure formula, PROC CALIS replaces the central covariance matrices with the mean vectors in the terms. In the current example the mean structure formula is formed by replacing and with and , respectively. Hence, the first term of the mean structure formula is 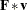 , and the second term of the mean structure formula is simply . Adding these two terms yields the desired mean structure formula for the model.
, and the second term of the mean structure formula is simply . Adding these two terms yields the desired mean structure formula for the model.
To make the mean vector specification more explicit, you can use the following equivalent syntax with the MEAN= option:
cosan var = var1-var6,
F(2,GEN) * P(2,SYM) [mean=v] + U(6,DIA) [mean=a];
If a term in the specification does not have a mean vector (covariance matrix) specification, a zero mean vector (null covariance matrix) is assumed. For example, the following specification generates the same mean and covariance structures as the preceding example:
cosan var = var1-var6,
F(2,GEN) * P(2,SYM) [/ v] + U(6,DIA) + [/ a];
The covariance structure formula for this specification is
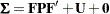 |
where 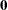 in the last term represents a null matrix. The corresponding mean structure formula is
in the last term represents a null matrix. The corresponding mean structure formula is
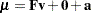 |
where in the second term represents a zero vector.
Specifying Models with No Explicit Central Covariance Matrices
In some situations, the central covariance matrices in the covariance structure formula are not defined explicitly. For example, the covariance structure formula for an orthogonal factor model is:
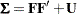 |
Again, assuming that is a 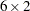 factor loading matrix and is a diagonal matrix for unique variances, you can specify the covariance structure formula as in the following COSAN statement:
factor loading matrix and is a diagonal matrix for unique variances, you can specify the covariance structure formula as in the following COSAN statement:
cosan var = var1-var6,
F(2,GEN) + U(6,DIA);
In determining the proper formula for the covariance structures, PROC CALIS detects whether the last matrix specified in each term is symmetric. If you specify this last matrix explicitly with the SYM, IDE (with the same number of rows and columns), or DIA type, it is certainly a symmetric matrix. If you specify this last matrix without an explicit matrix_type and it has the same number of rows and columns, it is also treated as a symmetric matrix for the central covariance matrix of the term. Otherwise, this last matrix is not symmetric and PROC CALIS treats the term as if an identity matrix has been inserted for the central covariance matrix. For example, for the orthogonal factor model specified in the preceding statement, PROC CALIS correctly generates the first term as 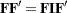 and the second term as .
and the second term as .
Certainly, you might also specify your own central covariance matrix explicitly for the orthogonal factor model. That is, you add an identity matrix into the COSAN model specification as shown in the following statement:
cosan var = var1-var6,
F(2,GEN) * I(2,IDE) + U(6,DIA);
Specifying Mean Structures for Models with No Central Covariance Matrices
When you specify covariance structures with central covariance matrices explicitly defined in the terms, the corresponding mean structure formula is formed by replacing the central covariance matrices with the mean_vectors that are specified in the brackets. However, when there is no central covariance matrix explicitly specified in a term, the last matrix of the term in the covariance structure formula is replaced with the mean_vector to generate the mean structure formula. Consider the following specification where there is no central covariance matrix defined explicitly in the first term of the COSAN model:
cosan var = var1-var6,
A(6,GEN) [ / v];
The generated formulas for the covariance and mean structures are
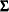 |
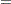 |
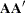 |
|||
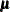 |
|
 |
If, instead, you intend to fit the following covariance and mean structures
|
|
|
|||
|
|
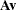 |
you must put an explicit identity matrix for the central covariance matrix in the first term. That is, you can use the following specification:
cosan var = var1-var6,
A(6,GEN) * I(6,IDE) [ / v];
Specifying Parameters in Matrices
By specifying the COSAN statement, you define the covariance and mean structures in matrix formulas for the observed variables. To specify the parameters in the model matrices, you need to use the MATRIX statements.
For example, for an orthogonal factor model with six variables (var1–var6) and two factors, the factor loading matrix might take the following form:
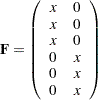 |
The unique variance matrix might take the following form:
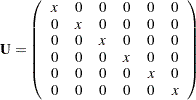 |
where each  in the matrices represents a free parameter to estimate and
in the matrices represents a free parameter to estimate and 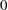 represents a fixed zero value. The covariance structures for the observed variables are described by the following formula:
represents a fixed zero value. The covariance structures for the observed variables are described by the following formula:
|
To specify the entire model, you use the following statements to define the covariance structure formula and the free parameters in the model matrices:
cosan var = var1-var6,
F(2,GEN) + U(6,DIA);
matrix F [1 to 3,@1],[4 to 6,@2];
matrix U [1,1],[2,2],[3,3],[4,4],[5,5],[6,6];
In the MATRIX statements, you specify the free parameters in the matrices. For the factor loading matrix , you specify that rows 1, 2, and 3 in column 1 and rows 4, 5, and 6 in column 2 are free parameters. For the unique variance matrix , you specify that all diagonal elements are free parameters. All other unspecified entries in the matrices are fixed zeros by default. Certainly, you can also specify fixed zeros explicitly. For the current example, you can specify matrix equivalently as:
matrix F [1 to 3,@1],[4 to 6,@2],
[4 to 6,@1] = 0. 0. 0.,
[1 to 3,@2] = 0. 0. 0.;
See the MATRIX statement for various ways to specify the parameters in matrices.
Matrix Names versus Parameter Names
Although parameter names and matrix names in PROC CALIS are both arbitrary SAS names for denoting mathematical entities in the model, their usages are very different in one aspect. That is, parameter names are globally defined in the procedure, while matrix names are only locally defined in models.
Consider the following two-group analysis example:
proc calis;
group 1 / data=g1;
group 2 / data=g2;
model 1 / group=1;
cosan var = var1-var6,
F(2,GEN) * I(2,IDE) + U(6,DIA);
matrix F [1 to 3,@1],[4 to 6,@2];
matrix U [1,1] = u1-u6;
model 2 / group=2;
cosan var = var1-var6,
F(1,GEN) * I(1,IDE) + D(6,DIA);
matrix F [1 to 6,@1];
matrix D [1,1] = u1-u6;
run;
In this example, you fit Model 1 to Group 1 and Model 2 to Group 2. You specify a matrix called in each of the models. However, the two models are not constrained by this "same" matrix . In fact, matrix in Model 1 is a matrix but matrix in Model 2 is a matrix. In addition, none of the parameters in the matrices are constrained by the parameter names (simply because no parameter names are used). This illustrates that matrix names in PROC CALIS are defined only locally within models.
In contrast, in this example you use different matrix names for the second terms of the two models. In Model 1, you define a diagonal matrix for the second term; and in Model 2, you define a diagonal matrix  for the second term. Are these two matrices necessarily different? The answer depends on how you define the parameters in these matrices. In the MATRIX statement for , all diagonal elements of are specified as free parameters u1–u6. Similarly, in the MATRIX statement for , all diagonal elements of as also specified free parameters u1–u6. Because you use the same sets of parameter names in both of these MATRIX statements, matrices and are essentially constrained to be the same even though their names are different. This illustrates that parameter names are defined globally in PROC CALIS.
for the second term. Are these two matrices necessarily different? The answer depends on how you define the parameters in these matrices. In the MATRIX statement for , all diagonal elements of are specified as free parameters u1–u6. Similarly, in the MATRIX statement for , all diagonal elements of as also specified free parameters u1–u6. Because you use the same sets of parameter names in both of these MATRIX statements, matrices and are essentially constrained to be the same even though their names are different. This illustrates that parameter names are defined globally in PROC CALIS.
The following points summarize how PROC CALIS treats matrix and parameter names differently:
Matrices with the same name in the same model are treated as identical.
Matrices with the same name in different models are not treated as identical.
Parameters with the same name are identical throughout the entire PROC CALIS specification.
Cross-model constraints on matrix elements are set by using the same parameter names, but not the same matrix names.
Row and Column Variable Names for Matrices
You can use the VARNAMES statement to define the column variable names for the model matrices of a COSAN model. However, you do not specify the row variable names for the model matrices directly because they are determined by the column variable names of the related matrices in the covariance and mean structure formulas. For example, the following specification names the column variables of matrices and  :
:
cosan var = var1-var6,
F(2,GEN) * I(2,IDE) + U(6,DIA);
varnames
F = [Factor1 Factor2],
I = F;
The column names for matrix are Factor1 and Factor2. The row names of matrix are var1–var6 because it is the first matrix in the first term. Matrix has the same column variable names as those for matrix , as specified in the last specification of the VARNAMES statement. Because matrix is a central covariance matrix, its row variable names are the same as its column variable names: Factor1 and Factor2. You do not specify the column variables names for matrix in the VARNAMES statement. However, because it is the first matrix in the second term, its row variable names are the same as that of the VAR= list in the COSAN statement. Because matrix is also the central covariance matrix in the second term, its column variable names are the same its row variable names, which has been determined to be var1–var6. See the VARNAMES statement for more details.
Default Parameters
Unlike other modeling languages in PROC CALIS, the COSAN modeling language does not set any default free parameters for the model matrices. There is only one type of default parameters in the COSAN model: fixed values for matrix elements. These fixed values can be 0 or 1. For matrices with the IDE or ZID type, all elements are predetermined with either 0 or 1. They are fixed matrices in the sense that you cannot override these default fixed values. For all other matrix types, PROC CALIS sets their elements to fixed zeros by default. You can override these default zeros by specifying them explicitly in the MATRIX statements.
Modifying a COSAN Model from a Reference Model
In this section, it is assumed that you use a REFMODEL statement within the scope of a MODEL statement and the reference model (or base model) is also a COSAN model. The reference model is referred to as the old model, while the model that makes reference to this old model is referred to as the new model. If the new model is not intended to be an exact copy of the old model, you can use the following extended COSAN modeling language to make modifications within the scope of the MODEL statement for the new model. The syntax is similar to, but not exactly the same as, the ordinary COSAN modeling language. (See the section COSAN Statement.) The respecification syntax for a COSAN model is as follows:
- COSAN ;
- MATRIX matrix-name parameters-in-matrix ;
- /* Repeat the MATRIX statement as needed */ ;
- VARNAMES name_assignments ;
In the respecification, the COSAN statement is optional. In fact, the purpose of using the COSAN statement at all is to remind yourself that a COSAN model is used in the model definition. If you use the COSAN statement, you cannot specify the VAR= option or the covariance and mean structure formula. This means that the model form and the observed variable references of the new model must be the same as the old (reference) model. The reason for enforcing these model structures is to ensure that the MATRIX statement respecifications are consistently interpreted.
You can optionally use the VARNAMES statement in the respecification. If the variable names for a COSAN matrix are defined in the old model but not redefined the new model, all variable names for that matrix are duplicated in the new model. However, specification of variable names for a COSAN matrix in the new model overrides the corresponding specification in the old model.
You can respecify or modify the elements of the COSAN model matrices by using the MATRIX matrix-name statements. The syntax of the MATRIX statements for respecifications is the same as that in the ordinary COSAN modeling language, but with one more feature. In the respecification syntax, you can use the missing value '.' to drop a parameter specification from the old model.
The new model is formed by integrating with the old model in the following ways:
- Duplication:
If you do not specify in the new model a parameter location that exists in the old model, the old parameter specification is duplicated in the new model.
- Addition:
If you specify in the new model a parameter location that does not exist in the old model, the new parameter specification is used in the new model.
- Deletion:
If you specify in the new model a parameter location that also exists in the old model and the new parameter is denoted by the missing value '.', the old parameter specification is not copied into the new model.
- Replacement:
If you specify in the new model a parameter location that also exists in the old model and the new parameter is not denoted by the missing value '.', the new parameter specification replaces the old one in the new model.
For example, the following two-group analysis specifies Model 2 by referring to Model 1 in the REFMODEL statement:
proc calis;
group 1 / data=d1;
group 2 / data=d2;
model 1 / group=1;
cosan
var = x1-x6,
F(2,GEN) * PHI(2,SYM) + PSI(6,SYM);
matrix F [1,1] = 1.,
[2,1] = load2,
[3,1] = load3,
[4,2] = 1.,
[5,2] = load5,
[6,2] = load6;
matrix PHI [1,1] = phi1,
[2,2] = phi2,
[2,1] = phi21;
matrix PSI [1,1] = psi1,
[2,2] = psi2,
[3,3] = psi3,
[4,4] = psi4,
[5,5] = psi5,
[6,6] = psi6;
varnames F = [Factor1 Factor2],
PHI = F;
model 2 / group=2;
refmodel 1;
matrix F [3,1] = load2; /* replacement */
matrix PHI [2,1] = .; /* deletion */
matrix PSI [3,1] = psi31; /* addition */
varnames F = [FF1 FF2],
run;
In this example, Model 2 is the new model which refers to the old model, Model 1. It illustrates the four types of model integration by using the MATRIX statements:
Duplication: Except for the
 and
and 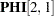 elements, all parameter specifications in the old model are duplicated in the new model.
elements, all parameter specifications in the old model are duplicated in the new model. Addition: The
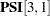 element is added with a new parameter psi31 in the new model. This indicates the presence of a correlated error in Model 2, but not in Model 1.
element is added with a new parameter psi31 in the new model. This indicates the presence of a correlated error in Model 2, but not in Model 1. Deletion: The
element is no longer a free parameter in the new model. This means that the two latent factors are correlated in Model 1, but not in Model 2. Replacement: The
element defined in Model 2 replaces the definition in the old model. This element is now a free parameter named load2. Because the 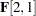 element (via duplication from the old model) is also a free parameter with this same name, and are constrained to be the same in Model 2, but not in Model 1.
element (via duplication from the old model) is also a free parameter with this same name, and are constrained to be the same in Model 2, but not in Model 1.
With the VARNAMES statement specification in Model 1, the two columns of matrix are labeled with Factor1 and Factor2, respectively. In addition, because PHI=F is specified in the VARNAMES statement of Model 1, the row and column of matrix 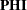 in Model 1 also contain Factor1 and Factor2 as the variable names. In Model 2, with the explicit VARNAMES specifications the two columns of matrix are labeled with FF1 and FF2, respectively. These names are not the same as those for matrix in the old (reference) model. However, because PHI=F is not specified in the VARNAMES statement of Model 2, the row and column of matrix in Model 2 contain Factor1 and Factor2 as the variable names, which are duplicated from the old (reference) model.
in Model 1 also contain Factor1 and Factor2 as the variable names. In Model 2, with the explicit VARNAMES specifications the two columns of matrix are labeled with FF1 and FF2, respectively. These names are not the same as those for matrix in the old (reference) model. However, because PHI=F is not specified in the VARNAMES statement of Model 2, the row and column of matrix in Model 2 contain Factor1 and Factor2 as the variable names, which are duplicated from the old (reference) model.
COSAN Models and Other Models
Because the COSAN model is a more general model than any other model considered in PROC CALIS, you can virtually fit any other type of model in PROC CALIS by using the COSAN modeling language. See the section Special Cases of the Generalized COSAN Model, Example 26.28, and Example 26.29 for illustrations and discussions.
In general, it is recommended that you use the more specific modeling languages such as FACTOR, LINEQS, LISMOD, MSTRUCT, PATH, and RAM. Because the COSAN model is very general in its formulation, PROC CALIS cannot exploit the specific model structures to generate reasonable initial estimates the way it does with other specific models such as FACTOR and PATH. If you do not provide initial estimates for a COSAN model, PROC CALIS uses some default starting values such as 0.5. See the START= option for controlling the starting value. See the RANDOM= option for setting random starting values. There are other reasons for preferring specific modeling languages whenever possible. The section Which Modeling Language? discusses these various reasons. However, when the covariance structures are complicated and are difficult to specify otherwise, the COSAN modeling language is a very useful tool. See Example 26.30 and Example 26.32 for illustrations.