IMSTAT Procedure (Analytics)
- Syntax
 Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementHYPERGROUP StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementNEURAL StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementTRANSFORM StatementQUIT Statement
Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementHYPERGROUP StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementNEURAL StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementTRANSFORM StatementQUIT Statement - Overview
- Using
- Examples Calculating Percentiles and QuartilesRetrieving Box ValuesRetrieving Box Plot Values with the NOUTLIERLIMIT= OptionRetrieving Distinct Value Counts and GroupingPerforming a Cluster AnalysisPerforming a Pairwise CorrelationCrosstabulation with Measures of Association and Chi-Square TestsTraining and Validating a Decision TreeStoring and Scoring a Decision TreePerforming a Multi-Dimensional SummaryFitting a Regression ModelForecasting and Automatic ModelingForecasting with Goal SeekingAggregating Time Series DataTraining and Validating a Neural NetworkPredicting Email Spam and Assessing the ModelTransforming Variables with Imputation and Binning
NEURAL Statement
The NEURAL statement trains feed-forward artificial neural networks (ANN) and can use the trained networks to score data sets. When you do not specify a target variable, the server encodes the input nodes for the purpose of dimensionality reduction.
| Examples: | Training and Validating a Neural Network |
Syntax
Optional Argument
target-variable
specifies the variable to model. If you do not specify a variable, then the server encodes the input nodes for the purpose of variable reduction.
NEURAL Statement Options
ACTIVATION=(activation-function-for-a-hidden-layer ...)
specifies the activation function for the neurons on each hidden layer. The following functions are available:
| IDENTITY | specifies the identify function. Values range between -∞ and ∞. For an input value of t, the function returns the same value, t. |
| LOGISTIC | specifies the logistic function. Values range between
zero and one. For an input value of t, the
function returns 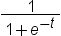 . .
|
| EXP | specifies the exponential function. Values range
between zero and ∞. For an input value of t,
the function returns 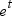 . .
|
| SIN | specifies the sine function. Values range between
zero and 1, inclusively. For an input value of t,
the function returns 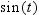 . .
|
| TANH | specifies the hyperbolic tangent function. Values
range between –1 and
1. For an input value of t, the function returns 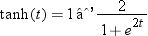 . .
|
| Aliases | ACT= |
| ACTIVATE= | |
| Default | TANH |
ARCHITECTURE= GLIM | MLP | DIRECT
specifies the network architecture to be trained. The GLIM architecture (Generalized Linear Model) specifies a two-layer perceptron (one is the input layer and the other is the output layer) without hidden layers or units. The MLP architecture specifies a multilayer perceptron with one or more hidden layers. The DIRECT architecture is an extension of MLP with direct connections between the input layer and the output layer.
| Alias | ARCH= |
| Default | GLIM. |
ASSESS
specifies that predicted probabilities are added to the scored data for all the levels of the nominal target variable when scoring is performed with the TEMPTABLE and LASRANN= options. It adds variables _NN_Level_ and _NN_P_ to the results. You can use these predicted probabilities in an ASSESS statement.
| Interaction | You must specify the TEMPTABLE and LASRANN= options along with this option. |
BIAS=r
specifies a fixed bias value for all the hidden and output neurons. In this case, the bias parameters are fixed and are not optimized.
CODE <(code-generation-options)>
requests that the server produce SAS scoring code based on the actions that it performed during the analysis. The server generates DATA step code. By default, the code is replayed as an ODS table by the procedure as part of the output of the statement. Frequently, you might want to write the scoring code to an external file by specifying options.
COMMENT
specifies to add comments to the code in addition to the header block. The header block is added by default.
FILENAME='path'
specifies the name of the external file to which the scoring code is written. This suboption applies only to the scoring code itself.
| Alias | FILE= |
| Interaction | If you do not specify this option, then the scoring code is displayed in an ODS result table. |
FORMATWIDTH=k
specifies the width to use in formatting derived numbers such as parameter estimates in the scoring code. The server applies the BEST format, and the default format for code generation is BEST20.
| Alias | FMTW= |
| Range | 12 to 32 |
LABELID=id
specifies a group identifier for group processing. The identifier is an integer and is used to create array names and statement labels in the generated code.
LINESIZE=n
specifies the line size for the generated code.
| Alias | LS= |
| Default | 72 |
| Range | 64 to 256 |
NOTRIM
specifies to format the variables using the full format width with padding. By default, leading and trailing blanks are removed from the formatted values.
REPLACE
specifies to overwrite the external file if a file with the specified name already exists. The option has no effect unless you specify the FILENAME= option.
COMBINATION=(combination-function-for-a-hidden-layer ...)
specifies the combination function for the neurons on each hidden layer. The available functions are described in the following list. When the COMBINATION= option is not specified, the hidden units use the LINEAR function.
| ADD | adds all the incoming values without using any weights
or biases. The function is defined as 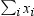 . .
|
| LINEAR | uses a linear combination of the incoming values
and weights. The function is defined as 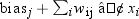 |
| RADIAL | uses a radial basis function with equal heights
and unequal widths for all units in the layer. The function is defined
as 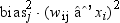 |
DELTA=r
specifies the annealing parameter when performing a simulated annealing (SA) global optimization. Without the DELTA= option, the step size option (STEP=) and the temperature option (T=) are used to perform a Monte Carlo (MC) global optimization. With the addition of the DELTA= option, the optimization becomes simulated annealing where the temperature is scaled by DELTA × T at every MC step.
DETAILS
specifies to display the convergence status and iteration results for training the network.
| Alias | DETAIL |
ERROR=error-function
specifies the error function to train the network. For interval variables, the default error function is NORMAL. For nominal variables, the default error function is ENTROPY. The available functions are as follows:
| GAMMA | uses the gamma distribution. The values of the target variable must be greater than zero. |
| ENTROPY | uses the cross or relative entropy for independent targets. The values of the target variable must be between zero and one. |
| NORMAL | uses the normal distribution. The target variable can have any value. |
| POISSON | uses the Poisson distribution. The values of the target variable must be greater than or equal to zero. |
FCONV=r
specifies a relative function convergence criterion.
| Default | 1e-5 |
FORMATS=("format-specification", ...)
specifies the formats for the input variables. If you do not specify the FORMATS= option, the default format is applied for that variable. Enclose each format specification in quotation marks and separate each format specification with a comma.
| Example | proc imstat data=lasr1.table1;
neural x / input=(a b) formats=("8.3", "$10");
quit; |
GCONV=r
specifies a relative gradient convergence criterion.
| Default | 1e-5 |
| Interaction | When TECH=NSIMP, there is no default value. |
HIDDEN=(positive-integer ...)
specifies the number
of hidden neurons for each hidden layer in the feed-forward artificial
neural network model. For example, HIDDEN=(5 3) specifies
two hidden layers. The first hidden layer has five hidden neurons
and the second has three hidden neurons.
| Alias | HIDDENS= |
| Interaction | When the HIDDEN= option is specified, the default architecture is MLP. |
IMPUTE
specifies to impute the output values with available target values when data is being scored. In this case, you are interested only in predicting the missing values of the target variable. This option can be used only when scoring is performed with the TEMPTABLE and LASRANN= options.
INPUT=variable-name
INPUT=(variable-name1 <variable-name2, ...>)
specifies the input variables for the network. You can add the target variable to the input list if you want to assign a format to the target variable by using the FORMATS= option. The number of input neurons on the input layer is determined by the number of input variables. The number of input variables equals the total number of levels from the nominal variables plus the number of interval variables.
LAMBDA=λ
specifies the weight decay number. The value must be zero or greater.
| Default | 0 |
LASRANN=table-name
specifies the table that contains the weights from a previously trained model. When the RESUME option is used with the LASRANN= option, training for that model resumes using the previously obtained weights as the new starting weights. Otherwise, the weights are used to score the active table.
| Alias | ANNLASR= |
LINESEARCH=i
specifies the line-search method for the CONGRA and QUANEW optimization techniques.
| Default | 2 |
| Range | An integer between 1 and 8. |
LISTNODE= ALL | INPUT | OUTPUT | HIDDEN
specifies the nodes to be included in the temporary table that is generated when you score a table with the NEURAL statement. When encoding of the input nodes is requested, the default is HIDDEN. This option is particularly useful when encoding is applied to reduce the dimension of the input nodes. By reusing the node output values, machine learning algorithms in the NEURAL, CLUSTER, DECISIONTREE, and RANDOMWOODS statements can use the newly encoded vectors as input.
| ALL | specifies to include all the nodes in the temporary table. |
| HIDDEN | specifies to include the hidden nodes only. |
| INPUT | specifies to include the input nodes only. |
| OUTPUT | specifies to include the output nodes only. |
LOWER=r
specifies a lower bound for the network weights.
| Default | –10.0 |
MAXFUNC=n
specifies the maximum number n of function calls in the iterative model fitting process. The default value depends on the optimization technique as follows:
|
Optimization Technique
|
Default Number of Function
Calls
|
|---|---|
|
TRUREG, NRRIDG, and
NEWRAP
|
125
|
|
QUANEW and DBLDOG
|
500
|
|
CONGRA
|
1000
|
|
NMSIMP
|
3000
|
|
LBFGS
|
Number of iterations
× 10
|
| Alias | MAXFU= |
MAXITER=i
specifies the maximum number of iterations in the model fitting process. The default value is 10 for all techniques.
MISSING= MIN | MEAN | MAX
specifies how to impute missing values for the input or target variables. When the MISSING= option is not specified, the observations with missing values are ignored. The MIN request imputes missing values for each variable with the minimum value. Similarly, the MAX request imputes the maximum value, and the MEAN request imputes the mean value. For nominal variables, a new missing category is created for the missing values.
MULTINET=i
specifies the number of networks to select out of the number of tries specified in the NUMTRIES= option. The networks with the smallest errors are selected as the set of best networks. When data is scored, the most frequent predicted values among the selected networks are used to make the final predictions. This option is required when performing Monte Carlo or simulated annealing optimizations. Those optimizations also use the DELTA=, STEP=, and T= options.
NOPREPARSE
prevents the procedure from preparsing and pregenerating code for temporary expressions, scoring programs, and other user-written SAS statements.
| Alias | NOPREP |
NOBIAS
specifies no bias parameters for the hidden and output units.
NOMINAL=variable-name
NOMINAL=(variable-list)
specifies the numeric variables to use as nominal variables. For the nominal input variables, neurons are created for every level. The values are coded as 0 or 1 indicator variables. Character variables are nominal and do not need to be included in the list.
NUMTRIES=i
specifies the number of optimizations to perform with different weight initializations when training networks. The network with the smallest error is selected as the best network. This option is required when performing Monte Carlo or simulated annealing global optimizations that also use the DELTA=, STEP=, and T= options.
| Default | 1 |
RESUME
specifies to resume a training optimization and use the weights that were obtained from previous training. The initial weights for resuming the optimization are read from a temporary table with the LASRANN= option. The specified framework of model options must be the same as the previous framework.
| Interaction | The RESUME option cannot be used with the MULTINET= option. |
SAVE=table-name
saves the result table so that you can use it in other IMSTAT procedure statements like STORE, REPLAY, and FREE. The value for table-name must be unique within the scope of the procedure execution. The name of a table that has been freed with the FREE statement can be used again in subsequent SAVE= options.
SCOREDATA=table-name
specifies the in-memory table that contains the scoring data. The table must exist in-memory on the server. The NEURAL statement in the IMSTAT procedure does not transfer a local data set to the server.
SEED=number
specifies the random number seed to use for generating random numbers. The random numbers are used to initialize the network weights.
STD= MIDRANGE | NONE | STD
specifies the standardization to use on the input interval variables.
| MIDRANGE | Variables are scaled to a midrange of 0 and a half-range of 1. |
| NONE | Variables are not altered. |
| STD | Variables are scaled to a mean of 0 and a standard deviation of 1. |
| Default | STD |
STEP=r
specifies a step size for perturbations on the network weights when performing Monte Carlo or simulated annealing global optimizations.
| Default | 0.01 |
T=r
specifies the artificial temperature parameter when performing Monte Carlo or simulated annealing global optimizations.
| Default | 1000 |
TARGETACT=activation-function-for-target-variable
specifies the activation function for the neurons on the output layer. The available functions are IDENTITY, LOGISTIC, EXP, SIN, TANH, and SOFTMAX. The definitions of these functions are described in the ACTIVATION=(activation-function-for-a-hidden-layer ...) option. The SOFTMAX function is unique to this option and is described as follows:
| SOFTMAX | performs the multiple logistic function. Values
range between zero and one. For an input value of t, the function
returns 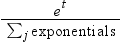 |
| Alias | TARACT= |
TARGETCOMB=combination-function-for-target-variable
specifies the combination function for the neurons on the target output nodes. The available functions are ADD, LINEAR, and RADIAL. The definitions of these functions are described in the COMBINATION=(combination-function-for-a-hidden-layer ...) option.
| Alias | TARCOMB= |
| Default | LINEAR |
TECHNIQUE=value
specifies the optimization technique for the iterative model-fitting process. The valid values are as follows:
| CONGRA (CG) | performs a conjugate-gradient optimization. |
| DBLDOG (DD) | performs a version of the double-dogleg optimization. |
| LBFGS | performs a limited-memory Broyden–Fletcher–Goldfarb–Shanno optimization. |
| NMSIMP (NS) | performs a Nelder-Mead simplex optimization. |
| QUANEW (QN) | performs a quasi-Newton optimization. |
| TRUREG (TR) | performs a trust-region optimization. |
| Alias | TECH= |
| Default | LBFGS |
TEMPEXPRESS="SAS-expressions"
TEMPEXPRESS=file-reference
specifies either a quoted string that contains the SAS expression that defines the temporary variables or a file reference to an external file with the SAS statements.
| Alias | TE= |
TEMPNAMES=variable-name
TEMPNAMES=(variable-list)
specifies the list of temporary variables for the request. Each temporary variable must be defined through SAS statements that you supply with the TEMPEXPRESS= option.
| Alias | TN= |
TEMPTABLE
generates an in-memory temporary table from the result set. The IMSTAT procedure displays the name of the table and stores it in the &_TEMPLAST_ macro variable, provided that the statement executed successfully.
TIMEOUT=seconds
specifies the maximum number of seconds that the server should run the statement. If the time-out is reached, the server terminates the request and generates an error and error message. By default, there is no time-out.
UPPER=r
specifies an upper bound for the network weights.
| Default | 10.0 |
VARS=variable-name
VARS=(variable-name1 <, variable-name2, ...>)
specifies the names of the variables to transfer from the active table to a temporary table that contains the scoring results. This option is ignored unless you score an in-memory table and the TEMPTABLE option is specified. The observations with these variables are copied to the generated temporary table.
| Alias | IDVARS= |
WEIGHT=variable-name
specifies a variable to weight the prediction errors (the difference between the output of the network value and the target value specified in the input data set) for each observation during training.
Details
ODS Table Names
|
ODS Table Name
|
Description
|
Option
|
|---|---|---|
|
ANNWeightInfo
|
Parameter estimates
|
Default, not shown when
TEMPTABLE is specified.
|
|
CodeGen
|
Generated DATA step
code for scoring
|
CODE
|
|
ConvergenceStatus
|
Convergence status of
optimization
|
DETAILS
|
|
ModelInfo
|
Model information
|
Default
|
|
OptIterHistory
|
Iteration history
|
DETAILS
|
|
ScoreInfo
|
Score information
|
LASRANN=
|