IMSTAT Procedure (Analytics)
- Syntax
 Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementHYPERGROUP StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementNEURAL StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementTRANSFORM StatementQUIT Statement
Procedure SyntaxPROC IMSTAT (Analytics) StatementAGGREGATE StatementARM StatementASSESS StatementBOXPLOT StatementCLUSTER StatementCORR StatementCROSSTAB StatementDECISIONTREE StatementDISTINCT StatementFORECAST StatementFREQUENCY StatementGENMODEL StatementGLM StatementGROUPBY StatementHISTOGRAM StatementHYPERGROUP StatementKDE StatementLOGISTIC StatementMDSUMMARY StatementNEURAL StatementOPTIMIZE StatementPERCENTILE StatementRANDOMWOODS StatementREGCORR StatementSUMMARY StatementTEXTPARSE StatementTOPK StatementTRANSFORM StatementQUIT Statement - Overview
- Using
- Examples Calculating Percentiles and QuartilesRetrieving Box ValuesRetrieving Box Plot Values with the NOUTLIERLIMIT= OptionRetrieving Distinct Value Counts and GroupingPerforming a Cluster AnalysisPerforming a Pairwise CorrelationCrosstabulation with Measures of Association and Chi-Square TestsTraining and Validating a Decision TreeStoring and Scoring a Decision TreePerforming a Multi-Dimensional SummaryFitting a Regression ModelForecasting and Automatic ModelingForecasting with Goal SeekingAggregating Time Series DataTraining and Validating a Neural NetworkPredicting Email Spam and Assessing the ModelTransforming Variables with Imputation and Binning
TRANSFORM Statement
The TRANSFORM statement can perform multiple transformations on a set of input variables. Each transformation can perform imputation, outlier detection and treatment, functional transformation, binning, and output.
| Example: | Transforming Variables with Imputation and Binning |
Syntax
Request Options
request
specifies the transform phases to perform on the input variables. If a request is not specified properly, it is ignored but does not stop other requests from processing. If you do not specify a request at all, the TRANSFORM statement bins the numeric variables from the active table with the BUCKET(5) method.
-
performs a simple imputation using the mean, median, or a specified value
-
detects outliers and can treat them by trimming or Winsorization
-
computes various functions for rescaling or standardization
-
performs discretization with either supervised or unsupervised methods
-
scores the input variables according to the specified requests, generates summarization tables, and can score code
NAME="request-name"
specifies the transformation request name. The names should be unique among the requests. If you do not specify unique names or do not provide names, then unique names are generated. Specifying a name can be useful because the name is displayed in the output and is used as a prefix to names of the transformed variables.
INPUT=variable-name
INPUT=(variable-name1 variable-name2 ...)
specifies the input variables to transform. If you do not specify input variables, then all numeric variables in the table are transformed.
| Alias | TRANSVAR= |
Imputation Phase Options
IMPUTE= NONE | MEAN | MEDIAN | VALUE(number)
specifies how to impute missing values for the input variables. The imputed values can be the mean, median, or a user-specified value.
| Default | NONE |
Outlier Phase Options
OUTLIER<=(outlier-boundaries <outlier-treatment>)>
specifies how to define outlier boundaries and how to treat outliers. The options for defining the outlier-boundaries are either IQR or PERC. The options for defining outlier-treatment are TRIM or WINSOR.
IQR<(m)>
specifies outliers based on a multiple of the interquartile range. Values outside the range [Q1 – m*IQR, Q3 + m*IQR] are considered outliers.
| Default | 1.5 |
PERC<(p)>
PERC<(lower upper)>
specifies outliers based on percentiles. If you specify a value for p, then it specifies the percentage of the distribution to be defined as outliers. Specifically, it defines the p/2 and (100-p/2) percentiles to use as the lower and upper bounds. Alternatively, you can specify the percentiles directly with the lower and upper options. This option also enables you to define nonsymmetric bounds. The default percentiles for the lower and upper bounds are 5 and 95 (or p=10).
TRIM
specifies to remove outliers by assigning them to missing values.
WINSOR
specifies to replace outliers with the lower and upper bounds determined by the outlier definition.
| Default | The default outlier boundaries are IQR(1.5). The default outlier treatment is TRIM. |
Functional Phase Options
FUNC=function-name<(arguments)>
specifies a function for rescaling or standardization to use during the functional transformation phase. The available functions are as follows:
ABS
returns the absolute value of each of the variables specified in the INPUT= option.
ARCSIN
returns the angular transformation for proportional data for each of the variables specified in the INPUT= option. Mathematically, the function is computed as arcsine(sqrt(x)).
BOXCOX<(λ)>
returns the Box-Cox transformation for each of the variables specified in the INPUT= option.
| Default | 2 |
CENTER<(LOC=location)>
returns the distance to the mean or median value for each of the variables specified in the INPUT= option. Values for location are MEAN or MEDIAN.
| Default | LOC=MEAN |
COSH
returns the hyperbolic cosine for each of the variables specified in the INPUT= option.
EXP
returns the exponential value for each of the variables specified in the INPUT= option.
INVERSE
returns the value of 1/variable for each of the variables specified in the INPUT= option.
LOG<(base)>
returns the logarithm for each of the variables specified in the INPUT= option. If you do not specify a value for base, then the natural logarithm is used.
POWER<(power)>
returns the power transform for each of the variables specified in the INPUT= option.
| Default | 2 |
RANGE<(MIN=lower MAX=upper)>
returns the value of each variable specified in the INPUT= option, subject to the upper bound and lower bound of the range.
| Default | MIN=0 and MAX=1 |
SQRT
returns the square root for each of the variables specified in the INPUT= option.
STANDARDIZE<(LOC=location SCALE=scale-specification)>
returns the standardized values for each variable in the INPUT= option. The value of location can be MEDIAN or MEAN.
SCALE=IQR<(m)>
SCALE=STD<(m)>
specifies the scale as a multiple of the interquartile range or a multiple of the standard deviation as follows.
| Default | LOC=MEAN and SCALE=STD(1) |
| For SCALE=IQR, the default value is 1.5. For SCALE=STD, the default value is 1. |
TANH
returns the hyperbolic tangent for each of the variables specified in the INPUT= option.
Binning Phase Options
BIN=method<(options)>
specifies a supervised or unsupervised discretization method. The unsupervised methods determine cutpoints without a target variable.
BUCKET<(n)>
specifies to create equal width bins according to the minimum value, maximum value, and the number of bins requested in n.
| Default | 5 |
QUANTILE<(n)>
specifies to create equal frequency bins.
| Default | 5 |
CHIMERGE<(<MIN=n> <MAX=n>)>
specifies to use the chi-merge algorithm for binning.
DTREE<(options)>
specifies to construct a one-level decision tree and discretize the variables by one-to-one mapping of the leaves of the decision tree to bins. You can use the following options to control the discretization.
GAIN
specifies to use the information gain as criteria, instead of information gain ratio.
MAX=n
specifies the maximum number of bins.
| Alias | MAXBRANCH= |
| Default | The default value for MAX= option is the number of levels (classes) of the TARGET= variable. |
MDLP<(<MIN=n> <MAX=n>)>
specifies to use minimum description length principle for binning.
| Default | BIN=BUCKET(5) |
EVENT=("event-category1" <"event-category2" ...>)
specifies the event category for binary target variables specified in the TARGET= option. Event categories are needed for the WOE, IV, or GINI index binning evaluation statistics. Multiple event categories are matched in pairs with multiple target variables based on the order they are listed. If more events are listed than target variables, the remaining events are ignored. If more target variables are listed than events, the last event value is used for the remaining target variables.
| Example | target=(saleFlag over18Flag) event=('1' '1') |
TARGET=variable-name
TARGET=(variable-name1 variable-name2 ...)
specifies target variables for performing supervised binning or for computing evaluation statistics with the EVALSTATS= option. Multiple target variables are matched in pairs with multiple input variables based on the order the variables are listed. If more target variables are listed than input variables, the remaining target variables are ignored. If more input variables are listed than target variables, the last target variable is used for the remaining input variables.
| Alias | EVALVAR= |
Output Phase Options
CODE <(code-generation-options)>
requests that the server produce SAS scoring code based on the actions that it performed during the analysis. The server generates DATA step code. By default, the code is replayed as an ODS table by the procedure as part of the output of the statement. More frequently, you might want to write the scoring code to an external file by specifying options.
COMMENT
specifies to add comments to the code in addition to the header block. The header block is added by default.
FILENAME='path'
specifies the name of the external file to which the scoring code is written. This suboption applies only to the scoring code itself.
| Alias | FILE= |
FORMATWIDTH=k
specifies the width to use in formatting derived numbers such as parameter estimates in the scoring code. The server applies the BEST format, and the default format for code generation is BEST20.
| Alias | FMTW= |
| Range | 12 to 32 |
LINESIZE=n
specifies the line size for the generated code.
| Alias | LS= |
| Default | 100 |
| Range | 100 to 256 |
DETAILS
specifies to display the bin details that result from a binning transformation phase.
SCORE
specifies to score the input variables according to the transformation requests. The scored results and the variables specified in the INPUT=, TARGET=, and FREQ= options are stored in a temporary table. If you want to transfer additional variables, you can specify them with the IDVARS= option.
| Alias | TEMPTABLE |
TRANSFORM Statement Options
ALLIDVARS
requests that all variables in the input table are treated as ID variables when a scoring table is produced. In other words, if this option is specified, all variables from the input table, including computed columns, are transferred to the scoring table. This option has no effect unless you specify the SCORE option.
ALPHA=number
specifies a number between 0 and 1 from which to determine the confidence level when the BIN= option uses the CHIMERGE= method. The default is α = 0.05, which leads to 100 x (1- α)% = 95% confidence limits for the parameter estimates.
| Default | 0.05 |
BININIT=(binning-initialization)
specifies how to initialize the bins for supervised binning methods (MDLP, CHIMERGE, or DTREE). The n value for the BUCKET and QUANTILE options is the starting number of bins. The default value is 100.
BUCKET<(n)>
specifies to use equal width binning.
EXACT
DISTINCT
specifies to use the distinct levels of the input variables. This binning initialization method is not compatible with outlier and functional phases. If you specify this initialization method, then transformation requests that contain an outlier phase or functional phase are ignored.
QUANTILE<(n)>
specifies to use equal frequency binning.
BINMISSING
specifies to place missing values in a separate bin during the binning phase.
EMPTYBINS
avoids the default merging of bins with no observations (empty bins) with their left neighbors. This option is applicable to the MDLP binning method. Empty bins can occur from initializing the number of bins with the BININIT= option set to BUCKET or QUANTILE.
EVALSTATS=(list-of-binning-evaluation-statistics)
specifies to compute binning evaluation statistics. These statistics are computed from two-way contingency tables between the scored variables and a target variable. The available statistics are as follows:
| CHISQ | chi-square statistic |
| FTEST | F-test statistic |
| G2 | G2 log-likelihood-ratio statistic |
| GINI | Gini index statistic |
| IV | information value statistic |
| WOE | weight of evidence statistic |
FREQ=variable-name
specifies a numeric variable with a value that represents the frequency of the observation. For example, if the FREQ= variable has the value 5 for a given observation, then that observation represents five observations. The FREQ= option is not available for transform requests that require percentiles in any of the transformation phase. Consequently, if the FREQ= option is specified and percentiles are required, then all such transformation requests are ignored.
IDVARS=(variable-list)
IDVARS=variable-name
specifies the variables from the active table to transfer to the temporary table that is created by scoring the input table. This option has no effect unless the SCORE option is also specified. (See the SCORE option for details about which variables are added to the temporary table by default.) The IDVARS= option should be used to transfer additional columns from the input table to the scoring table.
| Alias | ID= |
| Tip | Instead of this option, you can specify the ALLIDVARS option to transfer all variables from the input table to the scoring table. |
PERCEPSILON=number
specifies the convergence tolerance for the iterative algorithm that is used to compute percentiles. Percentiles are calculated in the outlier transformation phase and can also be calculated in the binning transformation phase if quantiles are requested.
| Default | 1e-5 |
PERCMAXITER=i
specifies the maximum number of iterations in the percentile algorithm. The percentile algorithm is iterative and avoids the cost of copying and sorting the data with multiple passes through the data. You can limit the number of iterations with the PERCMAXITER= option. You can also control the computational demand with the PERCEPSILON= option, which affects the tolerance criterion by which the convergence of the iterative algorithm is judged. If the percentile computations for a particular variable do not converge, the transformation that depends on those percentiles is not performed.
| Default | 10 |
TEMPEXPRESS="SAS-expressions"
TEMPEXPRESS=file-reference
specifies either a quoted string that contains the SAS expression that defines the temporary variables or a file reference to an external file with the SAS statements.
| Alias | TE= |
TEMPNAMES=variable-name
TEMPNAMES=(variable-list)
specifies the list of temporary variables for the request. Each temporary variable must be defined through SAS statements that you supply with the TEMPEXPRESS= option.
| Alias | TN= |
Details
Understanding Transformation Requests
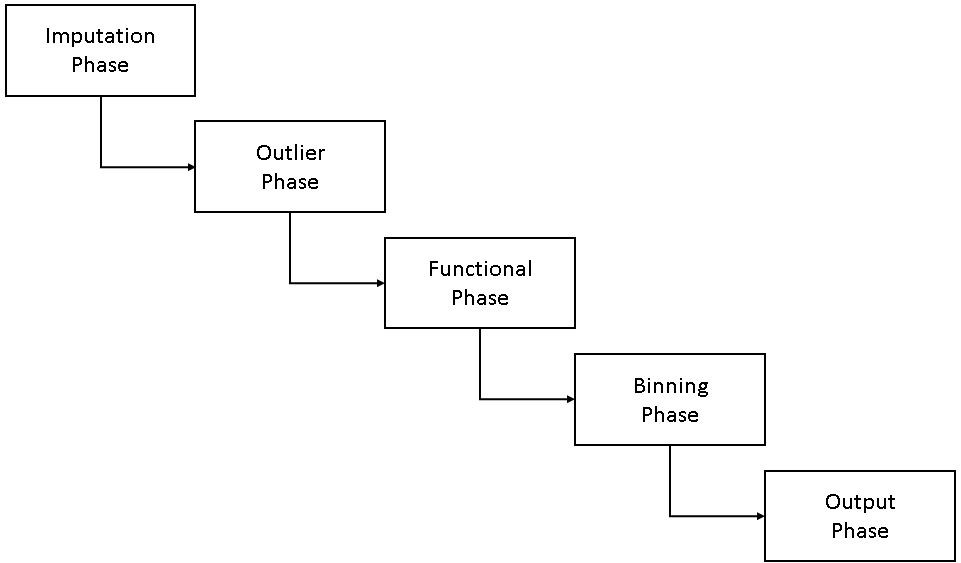
-
You can specify the phases in any order in a transform request. The server executes them in the sequence that is shown in the figure.
-
You can specify any subset of the phases that you want to use or all five phases. For example, in one TRANSFORM statement you can use one request to impute values and bin them. In another request, you can determine outliers, apply a functional transformation, and then bin the variables.
-
You can specify a phase more than once to modify a set of variables in a different way. For example, the following code fragment imputes missing values of the Oxygen variable by replacing with the mean value. For the RunPulse variable, missing values are replaced with the value 155.
transform (impute=mean input=(oxygen) name="impute") (impute=value(155) input=(runpulse) name="imputepulse155");
ODS Table Names
|
ODS Table Name
|
Description
|
Option
|
|---|---|---|
|
TransInfo
|
Phase-wise information
about the transformations
|
Default
|
|
NumVarSummary
|
Summary statistics for
numeric variables
|
Default
|
|
NomVarSummary
|
Summary statistics for
nominal variables
|
TARGET= or BININIT=EXACT
|
|
VarTransInfo
|
Variable transformation
information
|
Default
|
|
BinDetails
|
Detailed binning information
for numeric variables
|
BIN= and DETAILS
|
|
TempTable
|
Information about a
temporary table
|
SCORE or TEMPTABLE
|