The SPP Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsTesting for Complete Spatial RandomnessExploring Interpoint InteractionDistance Functions for Multitype Point PatternsBorder Edge Correction for Distance FunctionsConfidence Intervals for Summary StatisticsRipley-Rasson Window EstimatorCovariate Dependence TestsNonparametric Intensity EstimationInhomogeneous Poisson Process Model FittingNegative Binomial ModelingOutput Data SetsDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
Likelihood Methods for Model Fitting
The intensity function 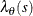 is assumed to be log linear in the parameters
is assumed to be log linear in the parameters 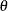 . So
. So
![\[ \log \lambda _\theta (s) = \theta \cdot Z(s) \]](images/statug_spp0169.png)
where 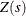 is a real-valued or vector-valued function of location s. can include a polynomial function of coordinate variables or a spatial covariate. The log likelihood for the parameters is given by
is a real-valued or vector-valued function of location s. can include a polynomial function of coordinate variables or a spatial covariate. The log likelihood for the parameters is given by
![\[ \log L(\theta ;x) = \sum _{i=1}^{n} \log \lambda _\theta (x_ i) - \int _ W \lambda _\theta (s)ds \]](images/statug_spp0171.png)
The integral in the expression for the log likelihood can be approximated using quadrature as
![\[ \int _ W \lambda _\theta (s;x)ds \approx \sum _{j=1}^{m}\lambda _\theta (s_ j;x)w_ j \]](images/statug_spp0172.png)
for some quadrature weights 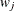 . Hence, the log likelihood can be rewritten as follows:
. Hence, the log likelihood can be rewritten as follows:
![\[ \log L(\theta ;x) \approx \sum _{i=1}^{n(x)}\log \lambda _\theta (x_ i;x) - \sum _{j=1}^{m}\lambda _\theta (s_ j;x)w_ j \]](images/statug_spp0174.png)
Based on the observation by Berman and Turner (1992) and Baddeley and Turner (2000), the log likelihood can be approximated as
![\[ \log L(\theta ;x) \approx \sum _{j=1}^{m}(y_ j\log \lambda _ j-\lambda _ j)w_ j \]](images/statug_spp0175.png)
where 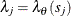 . If the list of points
. If the list of points 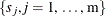 also includes the collection of data points
also includes the collection of data points 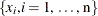 , then
, then 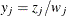 and
and
![\[ z_ j = \begin{cases} 1 & \text {if } s_ j \text {is a data point, } s_ j \in x \\ 0 & \text {if } s_ j \text {is a dummy point, } s_ j \not\in x \end{cases} \]](images/statug_spp0180.png)
The log pseudolikelihood can be maximized using standard optimization algorithms.