The PROBIT Procedure
- Overview
-
Getting Started

-
SyntaxPROC PROBIT StatementBY StatementCDFPLOT StatementCLASS StatementEFFECTPLOT StatementESTIMATE StatementINSET StatementIPPPLOT StatementLPREDPLOT StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementPREDPPLOT StatementSLICE StatementSTORE StatementTEST StatementWEIGHT Statement
-
DetailsMissing ValuesResponse Level OrderingComputational MethodDistributionsINEST= SAS-data-setModel SpecificationLack-of-Fit TestsRescaling the Covariance MatrixTolerance DistributionInverse Confidence LimitsOUTEST= SAS-data-setXDATA= SAS-data-setTraditional High-Resolution GraphicsDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
Overview: PROBIT Procedure
The PROBIT procedure calculates maximum likelihood estimates of regression parameters and the natural (or threshold) response rate for quantal response data from biological assays or other discrete event data. This includes probit, logit, ordinal logistic, and extreme value (or gompit) regression models.
Probit analysis developed from the need to analyze qualitative (dichotomous or polytomous) dependent variables within the regression framework. Many response variables are binary by nature (yes/no), while others are measured ordinally rather than continuously (degree of severity). Researchers have shown ordinary least squares (OLS) regression to be inadequate when the dependent variable is discrete (Collett 2003; Agresti 2002). Probit or logit analyses are more appropriate in this case.
The PROBIT procedure computes maximum likelihood estimates of the parameters 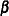 and C of the probit equation by using a modified Newton-Raphson algorithm.
When the response Y is binary, with values 0 and 1, the probit equation is
and C of the probit equation by using a modified Newton-Raphson algorithm.
When the response Y is binary, with values 0 and 1, the probit equation is
![\[ p = \mbox{Pr}(Y = 0) = C + (1 - C) F(\mb{x}^{\prime }\bbeta ) \]](images/statug_probit0002.png)
where
Notice that PROC PROBIT, by default, models the probability of the lower response levels. The choice of the distribution function F (normal for the probit model, logistic for the logit model, and extreme value or Gompertz for the gompit model) determines the type of analysis. For most problems, there is relatively little difference between the normal and logistic specifications of the model. Both distributions are symmetric about the value zero. The extreme value (or Gompertz) distribution, however, is not symmetric, approaching 0 on the left more slowly than it approaches 1 on the right. You can use the extreme value distribution where such asymmetry is appropriate.
For ordinal response models, the response, Y, of an individual or an experimental unit can be restricted to one of a (usually small) number, 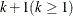 , of ordinal values, denoted for convenience by
, of ordinal values, denoted for convenience by 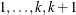 . For example, the severity of coronary disease can be classified into three response categories as 1=no disease, 2=angina
pectoris, and 3=myocardial infraction. The PROBIT procedure fits a common slopes cumulative model, which is a parallel-lines
regression model based on the cumulative probabilities of the response categories rather than on their individual probabilities.
The cumulative model has the form
. For example, the severity of coronary disease can be classified into three response categories as 1=no disease, 2=angina
pectoris, and 3=myocardial infraction. The PROBIT procedure fits a common slopes cumulative model, which is a parallel-lines
regression model based on the cumulative probabilities of the response categories rather than on their individual probabilities.
The cumulative model has the form
![\[ \Pr (Y \le 1~ |~ \mb{x})= F(\mb{x}^{\prime }\bbeta ) \]](images/statug_probit0006.png)
![\[ \Pr (Y \le i~ |~ \mb{x})= F(\alpha _ i + \mb{x}^{\prime }\bbeta ) , \quad 2 \le i \le k \]](images/statug_probit0007.png)
where 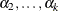 are k – 1 intercept parameters. By default, the covariate vector
are k – 1 intercept parameters. By default, the covariate vector  contains an overall intercept term.
contains an overall intercept term.
You can set or estimate the natural (threshold) response rate C. Estimation of C can begin either from an initial value that you specify or from the rate observed in a control group. By default, the natural response rate is fixed at zero.
An observation in the data set analyzed by the PROBIT procedure might contain the response and explanatory values for one subject. Alternatively, it might provide the number of observed events from a number of subjects at a particular setting of the explanatory variables. In this case, PROC PROBIT models the probability of an event.
The PROBIT procedure uses ODS Graphics to create graphs as part of its output. For general information about ODS Graphics, see Chapter 21: Statistical Graphics Using ODS. For specific information about the graphics available in the PROBIT procedure, see the section ODS Graphics.