The PROBIT Procedure
- Overview
-
Getting Started

-
SyntaxPROC PROBIT StatementBY StatementCDFPLOT StatementCLASS StatementEFFECTPLOT StatementESTIMATE StatementINSET StatementIPPPLOT StatementLPREDPLOT StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementPREDPPLOT StatementSLICE StatementSTORE StatementTEST StatementWEIGHT Statement
-
DetailsMissing ValuesResponse Level OrderingComputational MethodDistributionsINEST= SAS-data-setModel SpecificationLack-of-Fit TestsRescaling the Covariance MatrixTolerance DistributionInverse Confidence LimitsOUTEST= SAS-data-setXDATA= SAS-data-setTraditional High-Resolution GraphicsDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
Model Specification
For a two-level response, the probability that the lesser response occurs is modeled by the probit equation as
![\[ p = C + (1 - C) F(\mb{x}^{\prime }\mb{b}) \]](images/statug_probit0064.png)
The probability of the other (complementary) event is 1 – p.
For a multilevel response with outcomes labeled 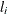 for
for 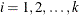 , the probability,
, the probability, 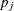 , of observing level
, of observing level 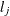 is as follows:
is as follows:
![\begin{eqnarray*} p_1 & = & C + (1 - C) F(\mb{x}^{\prime }\mb{b}) \\[0.05in] p_2 & = & (1 - C) \left( F(a_2 + {\mb{x}^{\prime }\mb{b}}) - F({\mb{x}^{\prime }\mb{b}}) \right) \\ & \vdots & \\ p_ j & = & (1 - C) \left( F(a_ j + {\mb{x}^{\prime }\mb{b}}) - F(a_{j-1} + {\mb{x}^{\prime }\mb{b}}) \right) \\ & \vdots & \\ p_ k & = & (1 - C) (1 - F(a_{k-1} + {\mb{x}^{\prime }\mb{b}}) ) \end{eqnarray*}](images/statug_probit0069.png)
Thus, for a k-level response, there are k – 2 additional parameters, 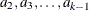 , estimated. These parameters are denoted by
, estimated. These parameters are denoted by Interceptj, 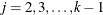 , in the output.
, in the output.
An intercept parameter is always added to the set of independent variables as the first term in the model unless the NOINT option is specified in the MODEL statement. If a classification variable taking on k levels is used as one of the independent variables, a set of k indicator variables is generated to model the effect of this variable. Because of the presence of the intercept term, there are at most k – 1 degrees of freedom for this effect in the model.