The MIANALYZE Procedure
- Overview
- Getting Started
-
Syntax

-
Details
-
ExamplesReading Means and Standard Errors from a DATA= Data SetReading Means and Covariance Matrices from a DATA= COV Data SetReading Regression Results from a DATA= EST Data SetReading Mixed Model Results from PARMS= and COVB= Data SetsReading Generalized Linear Model ResultsReading GLM Results from PARMS= and XPXI= Data SetsReading Logistic Model Results from a PARMS= Data SetReading Mixed Model Results with Classification CovariatesReading Nominal Logistic Model ResultsUsing a TEST statementCombining Correlation CoefficientsSensitivity Analysis with Control-Based Pattern ImputationSensitivity Analysis with the Tipping-Point Approach
- References
Multivariate Inferences
Multivariate inference based on Wald tests can be done with m imputed data sets. The approach is a generalization of the approach taken in the univariate case (Rubin 1987, p. 137; Schafer 1997, p. 113). Suppose that 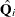 and
and 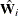 are the point and covariance matrix estimates for a p-dimensional parameter
are the point and covariance matrix estimates for a p-dimensional parameter 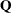 (such as a multivariate mean) from the
(such as a multivariate mean) from the 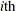 imputed data set, i = 1, 2, …, m. Then the combined point estimate for from the multiple imputation is the average of the m complete-data estimates:
imputed data set, i = 1, 2, …, m. Then the combined point estimate for from the multiple imputation is the average of the m complete-data estimates:
![\[ \overline{\mb{Q}} = \frac{1}{m} \sum _{i=1}^{m} \hat{\mb{Q}_ i} \]](images/statug_mianalyze0042.png)
Suppose that 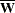 is the within-imputation covariance matrix,
which is the average of the m complete-data estimates:
is the within-imputation covariance matrix,
which is the average of the m complete-data estimates:
![\[ \overline{\mb{W}} = \frac{1}{m} \sum _{i=1}^{m} \hat{\mb{W}_ i} \]](images/statug_mianalyze0044.png)
And suppose that 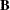 is the between-imputation covariance matrix:
is the between-imputation covariance matrix:
![\[ \mb{B} = \frac{1}{m-1} \sum _{i=1}^{m} (\hat{\mb{Q}_ i}-\overline{\mb{Q}}) (\hat{\mb{Q}_ i}-\overline{\mb{Q}})’ \]](images/statug_mianalyze0046.png)
Then the covariance matrix associated with 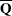 is the total covariance matrix
is the total covariance matrix
![\[ \mb{T}_{0} = \overline{\mb{W}} + (1+\frac{1}{m})\mb{B} \]](images/statug_mianalyze0048.png)
The natural multivariate extension of the t statistic used in the univariate case is the F statistic
![\[ F_{0} = (\mb{Q}-\overline{\mb{Q}})’ \mb{T}_{0}^{-1} (\mb{Q}-\overline{\mb{Q}}) \]](images/statug_mianalyze0049.png)
with degrees of freedom p and
![\[ v=(m-1)(1+1/r)^{2} \]](images/statug_mianalyze0050.png)
where
![\[ r = (1+\frac{1}{m}) \, \mr{trace} (\mb{B} \overline{\mb{W}}^{-1}) / p \]](images/statug_mianalyze0051.png)
is an average relative increase in variance due to nonresponse (Rubin 1987, p. 137; Schafer 1997, p. 114).
However, the reference distribution of the statistic 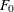 is not easily derived. Especially for small m, the between-imputation covariance matrix is unstable and does not have full rank for
is not easily derived. Especially for small m, the between-imputation covariance matrix is unstable and does not have full rank for 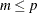 (Schafer 1997, p. 113).
(Schafer 1997, p. 113).
One solution is to make an additional assumption that the population between-imputation and within-imputation covariance matrices
are proportional to each other (Schafer 1997, p. 113). This assumption implies that the fractions of missing information for all components of are equal. Under this assumption, a more stable estimate of the total covariance matrix is
![\[ \mb{T} = (1+r) \overline{\mb{W}} \]](images/statug_mianalyze0054.png)
With the total covariance matrix 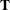 , the F statistic (Rubin 1987, p. 137)
, the F statistic (Rubin 1987, p. 137)
![\[ F = (\mb{Q}-\overline{\mb{Q}})’ \mb{T}^{-1} (\mb{Q}-\overline{\mb{Q}}) / p \]](images/statug_mianalyze0056.png)
has an F distribution with degrees of freedom p and 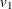 ,
where
,
where
![\[ v_{1} = \frac{1}{2} (p+1) (m-1) (1+\frac{1}{r})^{2} \]](images/statug_mianalyze0058.png)
For 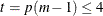 , PROC MIANALYZE uses the degrees of freedom in the analysis. For
, PROC MIANALYZE uses the degrees of freedom in the analysis. For 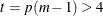 , PROC MIANALYZE uses
, PROC MIANALYZE uses 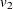 , a better approximation of the degrees of freedom
given by Li, Raghunathan, and Rubin (1991):
, a better approximation of the degrees of freedom
given by Li, Raghunathan, and Rubin (1991):
![\[ v_{2} = 4 + (t-4) \left[ 1+ \frac{1}{r} (1-\frac{2}{t}) \right]^{2} \]](images/statug_mianalyze0062.png)