The MIANALYZE Procedure
- Overview
- Getting Started
-
Syntax

-
Details
-
ExamplesReading Means and Standard Errors from a DATA= Data SetReading Means and Covariance Matrices from a DATA= COV Data SetReading Regression Results from a DATA= EST Data SetReading Mixed Model Results from PARMS= and COVB= Data SetsReading Generalized Linear Model ResultsReading GLM Results from PARMS= and XPXI= Data SetsReading Logistic Model Results from a PARMS= Data SetReading Mixed Model Results with Classification CovariatesReading Nominal Logistic Model ResultsUsing a TEST statementCombining Correlation CoefficientsSensitivity Analysis with Control-Based Pattern ImputationSensitivity Analysis with the Tipping-Point Approach
- References
Multiple Imputation Efficiency
The relative efficiency (RE)
of using the finite m imputation estimator, rather than using an infinite number for the fully efficient imputation, in units of variance, is approximately
a function of m and 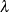 (Rubin 1987, p. 114):
(Rubin 1987, p. 114):
![\[ \mr{RE} = (1 + \frac{\lambda }{m})^{-1} \]](images/statug_mianalyze0036.png)
Table 76.2 shows relative efficiencies with different values of m and .
Table 76.2: Relative Efficiencies
|
|
||||||
|---|---|---|---|---|---|---|
|
m |
10% |
20% |
30% |
50% |
70% |
|
|
3 |
0.9677 |
0.9375 |
0.9091 |
0.8571 |
0.8108 |
|
|
5 |
0.9804 |
0.9615 |
0.9434 |
0.9091 |
0.8772 |
|
|
10 |
0.9901 |
0.9804 |
0.9709 |
0.9524 |
0.9346 |
|
|
20 |
0.9950 |
0.9901 |
0.9852 |
0.9756 |
0.9662 |
|
The table shows that for situations with little missing information, only a small number of imputations are necessary. In practice, the number of imputations needed can be informally verified by replicating sets of m imputations and checking whether the estimates are stable between sets (Horton and Lipsitz 2001, p. 246).