The MIANALYZE Procedure
- Overview
- Getting Started
-
Syntax

-
Details
-
ExamplesReading Means and Standard Errors from a DATA= Data SetReading Means and Covariance Matrices from a DATA= COV Data SetReading Regression Results from a DATA= EST Data SetReading Mixed Model Results from PARMS= and COVB= Data SetsReading Generalized Linear Model ResultsReading GLM Results from PARMS= and XPXI= Data SetsReading Logistic Model Results from a PARMS= Data SetReading Mixed Model Results with Classification CovariatesReading Nominal Logistic Model ResultsUsing a TEST statementCombining Correlation CoefficientsSensitivity Analysis with Control-Based Pattern ImputationSensitivity Analysis with the Tipping-Point Approach
- References
Combining Inferences from Imputed Data Sets
With m imputations, m different sets of the point and variance estimates for a parameter Q can be computed. Suppose that 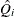 and
and 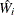 are the point and variance estimates, respectively, from the ith imputed data set, i = 1, 2, …, m. Then the combined point estimate for Q from multiple imputation is the average of the m complete-data estimates:
are the point and variance estimates, respectively, from the ith imputed data set, i = 1, 2, …, m. Then the combined point estimate for Q from multiple imputation is the average of the m complete-data estimates:
![\[ {\overline Q} = \frac{1}{m} \sum _{i=1}^{m} \hat{Q_ i} \]](images/statug_mianalyze0017.png)
Suppose that 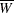 is the within-imputation variance,
which is the average of the m complete-data estimates:
is the within-imputation variance,
which is the average of the m complete-data estimates:
![\[ {\overline W} = \frac{1}{m} \sum _{i=1}^{m} \hat{W_ i} \]](images/statug_mianalyze0019.png)
And suppose that B is the between-imputation variance:
![\[ B = \frac{1}{m-1} \sum _{i=1}^{m} (\hat{Q_ i}-{\overline Q})^2 \]](images/statug_mianalyze0020.png)
Then the variance estimate associated with 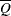 is the total variance (Rubin 1987)
is the total variance (Rubin 1987)
![\[ T = {\overline W} + (1+\frac{1}{m}) B \]](images/statug_mianalyze0022.png)
The statistic 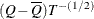 is approximately distributed as t with
is approximately distributed as t with 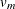 degrees of freedom (Rubin 1987), where
degrees of freedom (Rubin 1987), where
![\[ v_{m} = (m-1) {\left[ 1 + \frac{{\overline W}}{(1+m^{-1})B} \right]}^2 \]](images/statug_mianalyze0025.png)
The degrees of freedom depend on m and the ratio
![\[ r = \frac{(1+m^{-1})B}{\overline W} \]](images/statug_mianalyze0026.png)
The ratio r is called the relative increase in variance due to nonresponse (Rubin 1987).
When there is no missing information about Q, the values of r and B are both zero. With a large value of m or a small value of r, the degrees of freedom will be large and the distribution of will be approximately normal.
Another useful statistic is the fraction of missing information about Q:
![\[ \hat{\lambda } = \frac{r+2/(v_{m}+3)}{r+1} \]](images/statug_mianalyze0027.png)
Both statistics r and 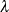 are helpful diagnostics for assessing how the missing data contribute to the uncertainty about Q.
are helpful diagnostics for assessing how the missing data contribute to the uncertainty about Q.
When the complete-data degrees of freedom 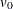 are small, and there is only a modest proportion of missing data, the computed degrees of freedom, , can be much larger than , which is inappropriate. For example, with m = 5 and r = 10%, the computed degrees of freedom
are small, and there is only a modest proportion of missing data, the computed degrees of freedom, , can be much larger than , which is inappropriate. For example, with m = 5 and r = 10%, the computed degrees of freedom 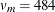 , which is inappropriate for data sets with complete-data degrees of freedom less than 484.
, which is inappropriate for data sets with complete-data degrees of freedom less than 484.
Barnard and Rubin (1999) recommend the use of adjusted degrees of freedom
![\[ v_{m}^{*} = \, \left[ \frac{1}{v_{m}} + \frac{1}{\hat{v}_{\mathit{obs}}} \right] ^{-1} \]](images/statug_mianalyze0031.png)
where 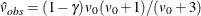 and
and 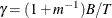 .
.
If you specify the complete-data degrees of freedom with the EDF= option, the MIANALYZE procedure uses the adjusted degrees of freedom, 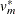 , for inference. Otherwise, the degrees of freedom are used.
, for inference. Otherwise, the degrees of freedom are used.