The GENMOD Procedure
-
Overview

-
Getting Started
-
Syntax
PROC GENMOD Statement ASSESS Statement BAYES Statement BY Statement CLASS Statement CONTRAST Statement DEVIANCE Statement EFFECTPLOT Statement ESTIMATE Statement EXACT Statement EXACTOPTIONS Statement FREQ Statement FWDLINK Statement INVLINK Statement LSMEANS Statement LSMESTIMATE Statement MODEL Statement OUTPUT Statement Programming Statements REPEATED Statement SLICE Statement STORE Statement STRATA Statement VARIANCE Statement WEIGHT Statement ZEROMODEL Statement
-
Details
Generalized Linear Models Theory Specification of Effects Parameterization Used in PROC GENMOD Type 1 Analysis Type 3 Analysis Confidence Intervals for Parameters F Statistics Lagrange Multiplier Statistics Predicted Values of the Mean Residuals Multinomial Models Zero-Inflated Models Generalized Estimating Equations Assessment of Models Based on Aggregates of Residuals Case Deletion Diagnostic Statistics Bayesian Analysis Exact Logistic and Exact Poisson Regression Missing Values Displayed Output for Classical Analysis Displayed Output for Bayesian Analysis Displayed Output for Exact Analysis ODS Table Names ODS Graphics
-
Examples
Logistic Regression Normal Regression, Log Link Gamma Distribution Applied to Life Data Ordinal Model for Multinomial Data GEE for Binary Data with Logit Link Function Log Odds Ratios and the ALR Algorithm Log-Linear Model for Count Data Model Assessment of Multiple Regression Using Aggregates of Residuals Assessment of a Marginal Model for Dependent Data Bayesian Analysis of a Poisson Regression Model Exact Poisson Regression
- References
| The GENMOD Procedure |
The GENMOD procedure fits a generalized linear model to the data by maximum likelihood estimation of the parameter vector 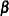 . There is, in general, no closed form solution for the maximum likelihood estimates of the parameters. The GENMOD procedure estimates the parameters of the model numerically through an iterative fitting process. The dispersion parameter
. There is, in general, no closed form solution for the maximum likelihood estimates of the parameters. The GENMOD procedure estimates the parameters of the model numerically through an iterative fitting process. The dispersion parameter 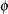 is also estimated by maximum likelihood or, optionally, by the residual deviance or by Pearson’s chi-square divided by the degrees of freedom. Covariances, standard errors, and
is also estimated by maximum likelihood or, optionally, by the residual deviance or by Pearson’s chi-square divided by the degrees of freedom. Covariances, standard errors, and 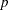 -values are computed for the estimated parameters based on the asymptotic normality of maximum likelihood estimators.
-values are computed for the estimated parameters based on the asymptotic normality of maximum likelihood estimators.
A number of popular link functions and probability distributions are available in the GENMOD procedure. The built-in link functions are as follows:
identity:
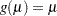
logit:
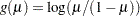
probit:
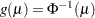 , where
, where 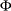 is the standard normal cumulative distribution function
is the standard normal cumulative distribution function power:
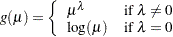
log:
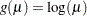
complementary log-log:

The available distributions and associated variance functions are as follows:
normal:
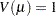
binomial (proportion):
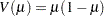
Poisson:
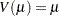
gamma:
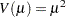
inverse Gaussian:
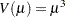
negative binomial:
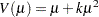
geometric:

multinomial
zero-inflated Poisson
zero-inflated negative binomial
The negative binomial and zero-inflated negative binomial are distributions with an additional parameter 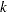 in the variance function. PROC GENMOD estimates by maximum likelihood, or you can optionally set it to a constant value. See McCullagh and Nelder (1989), Hilbe (1994), Hilbe (2007), Long (1997), Cameron and Trivedi (1998), or Lawless (1987) for discussions of the negative binomial distribution.
in the variance function. PROC GENMOD estimates by maximum likelihood, or you can optionally set it to a constant value. See McCullagh and Nelder (1989), Hilbe (1994), Hilbe (2007), Long (1997), Cameron and Trivedi (1998), or Lawless (1987) for discussions of the negative binomial distribution.
The multinomial distribution is sometimes used to model a response that can take values from a number of categories. The binomial is a special case of the multinomial with two categories. See the section Multinomial Models and McCullagh and Nelder (1989, Chapter 5) for a description of the multinomial distribution.
The zero-inflated Poisson and zero-inflated negative binomial are included in PROC GENMOD even though they are not generalized linear models. They are useful extensions of generalized linear models. See the section Zero-Inflated Models for information about the zero-inflated distributions.
In addition, you can easily define your own link functions or distributions through DATA step programming statements used within the procedure.
An important aspect of generalized linear modeling is the selection of explanatory variables in the model. Changes in goodness-of-fit statistics are often used to evaluate the contribution of subsets of explanatory variables to a particular model. The deviance, defined to be twice the difference between the maximum attainable log likelihood and the log likelihood of the model under consideration, is often used as a measure of goodness of fit. The maximum attainable log likelihood is achieved with a model that has a parameter for every observation. See the section Goodness of Fit for formulas for the deviance.
One strategy for variable selection is to fit a sequence of models, beginning with a simple model with only an intercept term, and then to include one additional explanatory variable in each successive model. You can measure the importance of the additional explanatory variable by the difference in deviances or fitted log likelihoods between successive models. Asymptotic tests computed by the GENMOD procedure enable you to assess the statistical significance of the additional term.
The GENMOD procedure enables you to fit a sequence of models, up through a maximum number of terms specified in a MODEL statement. A table summarizes twice the difference in log likelihoods between each successive pair of models. This is called a Type 1 analysis in the GENMOD procedure, because it is analogous to Type I (sequential) sums of squares in the GLM procedure. As with the PROC GLM Type I sums of squares, the results from this process depend on the order in which the model terms are fit.
The GENMOD procedure also generates a Type 3 analysis analogous to Type III sums of squares in the GLM procedure. A Type 3 analysis does not depend on the order in which the terms for the model are specified. A GENMOD procedure Type 3 analysis consists of specifying a model and computing likelihood ratio statistics for Type III contrasts for each term in the model. The contrasts are defined in the same way as they are in the GLM procedure. The GENMOD procedure optionally computes Wald statistics for Type III contrasts. This is computationally less expensive than likelihood ratio statistics, but it is thought to be less accurate because the specified significance level of hypothesis tests based on the Wald statistic might not be as close to the actual significance level as it is for likelihood ratio tests.
A Type 3 analysis generalizes the use of Type III estimable functions in linear models. Briefly, a Type III estimable function (contrast) for an effect is a linear function of the model parameters that involves the parameters of the effect and any interactions with that effect. A test of the hypothesis that the Type III contrast for a main effect is equal to 0 is intended to test the significance of the main effect in the presence of interactions. See Chapter 41, The GLM Procedure, and Chapter 15, The Four Types of Estimable Functions, for more information about Type III estimable functions. Also refer to Littell, Freund, and Spector (1991).
Additional features of the GENMOD procedure include the following:
likelihood ratio statistics for user-defined contrasts—that is, linear functions of the parameters and
-values based on their asymptotic chi-square distributions estimated values, standard errors, and confidence limits for user-defined contrasts and least squares means
ability to create a SAS data set corresponding to most tables displayed by the procedure (see Table 39.8 and Table 39.9)
confidence intervals for model parameters based on either the profile likelihood function or asymptotic normality
syntax similar to that of PROC GLM for the specification of the response and model effects, including interaction terms and automatic coding of classification variables
ability to fit GEE models for clustered response data
ability to perform Bayesian analysis by Gibbs sampling