The UNIVARIATE Procedure
- Overview
-
Getting Started

-
Syntax
-
Details
Missing Values Rounding Descriptive Statistics Calculating the Mode Calculating Percentiles Tests for Location Confidence Limits for Parameters of the Normal Distribution Robust Estimators Creating Line Printer Plots Creating High-Resolution Graphics Using the CLASS Statement to Create Comparative Plots Positioning Insets Formulas for Fitted Continuous Distributions Goodness-of-Fit Tests Kernel Density Estimates Construction of Quantile-Quantile and Probability Plots Interpretation of Quantile-Quantile and Probability Plots Distributions for Probability and Q-Q Plots Estimating Shape Parameters Using Q-Q Plots Estimating Location and Scale Parameters Using Q-Q Plots Estimating Percentiles Using Q-Q Plots Input Data Sets OUT= Output Data Set in the OUTPUT Statement OUTHISTOGRAM= Output Data Set OUTKERNEL= Output Data Set OUTTABLE= Output Data Set Tables for Summary Statistics ODS Table Names ODS Tables for Fitted Distributions ODS Graphics Computational Resources
-
Examples
Computing Descriptive Statistics for Multiple Variables Calculating Modes Identifying Extreme Observations and Extreme Values Creating a Frequency Table Creating Plots for Line Printer Output Analyzing a Data Set With a FREQ Variable Saving Summary Statistics in an OUT= Output Data Set Saving Percentiles in an Output Data Set Computing Confidence Limits for the Mean, Standard Deviation, and Variance Computing Confidence Limits for Quantiles and Percentiles Computing Robust Estimates Testing for Location Performing a Sign Test Using Paired Data Creating a Histogram Creating a One-Way Comparative Histogram Creating a Two-Way Comparative Histogram Adding Insets with Descriptive Statistics Binning a Histogram Adding a Normal Curve to a Histogram Adding Fitted Normal Curves to a Comparative Histogram Fitting a Beta Curve Fitting Lognormal, Weibull, and Gamma Curves Computing Kernel Density Estimates Fitting a Three-Parameter Lognormal Curve Annotating a Folded Normal Curve Creating Lognormal Probability Plots Creating a Histogram to Display Lognormal Fit Creating a Normal Quantile Plot Adding a Distribution Reference Line Interpreting a Normal Quantile Plot Estimating Three Parameters from Lognormal Quantile Plots Estimating Percentiles from Lognormal Quantile Plots Estimating Parameters from Lognormal Quantile Plots Comparing Weibull Quantile Plots Creating a Cumulative Distribution Plot Creating a P-P Plot
- References
| OUTPUT Statement |
The OUTPUT statement saves statistics and BY variables in an output data set. When you use a BY statement, each observation in the OUT= data set corresponds to one of the BY groups. Otherwise, the OUT= data set contains only one observation.
You can use any number of OUTPUT statements in the UNIVARIATE procedure. Each OUTPUT statement creates a new data set containing the statistics specified in that statement. You must use the VAR statement with the OUTPUT statement. The OUTPUT statement must contain a specification of the form keyword=names or the PCTLPTS= and PCTLPRE= specifications. See Example 4.7 and Example 4.8.
- OUT=SAS-data-set
-
identifies the output data set. If SAS-data-set does not exist, PROC UNIVARIATE creates it. If you omit OUT=, the data set is named DATAn, where n is the smallest integer that makes the name unique.
- keyword=names
-
specifies the statistics to include in the output data set and gives names to the new variables that contain the statistics. Specify a keyword for each desired statistic, followed by an equal sign, followed by the names of the variables to contain the statistic. In the output data set, the first variable listed after a keyword in the OUTPUT statement contains the statistic for the first variable listed in the VAR statement, the second variable contains the statistic for the second variable in the VAR statement, and so on. If the list of names following the equal sign is shorter than the list of variables in the VAR statement, the procedure uses the names in the order in which the variables are listed in the VAR statement. The available keywords are listed in the following tables:
Table 4.60 Descriptive Statistic Keywords Keyword
Description
CSS
corrected sum of squares
CV
coefficient of variation
KURTOSIS | KURT
kurtosis
MAX
largest value
MEAN
sample mean
MIN
smallest value
MODE
most frequent value
N
sample size
NMISS
number of missing values
NOBS
number of observations
RANGE
range
SKEWNESS | SKEW
skewness
STD | STDDEV
standard deviation
STDMEAN | STDERR
standard error of the mean
SUM
sum of the observations
SUMWGT
sum of the weights
USS
uncorrected sum of squares
VAR
variance
Table 4.61 Quantile Statistic Keywords Keyword
Description
P1
1st percentile
P5
5th percentile
P10
10th percentile
Q1 | P25
lower quartile (25th percentile)
MEDIAN | Q2 | P50
median (50th percentile)
Q3 | P75
upper quartile (75th percentile)
P90
90th percentile
P95
95th percentile
P99
99th percentile
QRANGE
interquartile range (Q3 - Q1)
Table 4.62 Robust Statistics Keywords Keyword
Description
GINI
Gini’s mean difference
MAD
median absolute difference about the median
QN
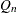 , alternative to MAD
, alternative to MAD SN
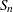 , alternative to MAD
, alternative to MAD STD_GINI
Gini’s standard deviation
STD_MAD
MAD standard deviation
STD_QN
standard deviation STD_QRANGE
interquartile range standard deviation
STD_SN
standard deviation Table 4.63 Hypothesis Testing Keywords Keyword
Description
MSIGN
sign statistic
NORMALTEST
test statistic for normality
SIGNRANK
signed rank statistic
PROBM
probability of a greater absolute value for the sign statistic
PROBN
probability value for the test of normality
PROBS
probability value for the signed rank test
PROBT
probability value for the Student’s
 test
test T
statistic for the Student’s
test The UNIVARIATE procedure automatically computes the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles for the data. These can be saved in an output data set by using keyword=names specifications. For additional percentiles, you can use the following percentile-options.
- PCTLPTS=percentiles
-
specifies one or more percentiles that are not automatically computed by the UNIVARIATE procedure. The PCTLPRE= and PCTLPTS= options must be used together. You can specify percentiles with an expression of the form start TO stop BY increment where start is a starting number, stop is an ending number, and increment is a number to increment by. The PCTLPTS= option generates additional percentiles and outputs them to a data set. These additional percentiles are not printed.
To compute the 50th, 95th, 97.5th, and 100th percentiles, submit the statement
output pctlpre=P_ pctlpts=50,95 to 100 by 2.5;
PROC UNIVARIATE computes the requested percentiles based on the method that you specify with the PCTLDEF= option in the PROC UNIVARIATE statement. You must use PCTLPRE=, and optionally PCTLNAME=, to specify variable names for the percentiles. For example, the following statements create an output data set named Pctls that contains the 20th and 40th percentiles of the analysis variables PreTest and PostTest:
proc univariate data=Score; var PreTest PostTest; output out=Pctls pctlpts=20 40 pctlpre=PreTest_ PostTest_ pctlname=P20 P40; run;PROC UNIVARIATE saves the 20th and 40th percentiles for PreTest and PostTest in the variables PreTest_P20, PostTest_P20, PreTest_P40, and PostTest_P40.
- PCTLPRE=prefixes
-
specifies one or more prefixes to create the variable names for the variables that contain the PCTLPTS= percentiles. To save the same percentiles for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement. The PCTLPRE= and PCTLPTS= options must be used together.
The procedure generates new variable names by using the prefix and the percentile values. If the specified percentile is an integer, the variable name is simply the prefix followed by the value. If the specified value is not an integer, an underscore replaces the decimal point in the variable name, and decimal values are truncated to one decimal place. For example, the following statements create the variables pwid20, pwid33_3, pwid66_6, and pwid80 for the 20th, 33.33rd, 66.67th, and 80th percentiles of Width, respectively:
proc univariate noprint; var Width; output pctlpts=20 33.33 66.67 80 pctlpre=pwid; run;
If you request percentiles for more than one variable, you should list prefixes in the same order in which the variables appear in the VAR statement. If combining the prefix and percentile value results in a name longer than 32 characters, the prefix is truncated so that the variable name is 32 characters.
- PCTLNAME=suffixes
-
specifies one or more suffixes to create the names for the variables that contain the PCTLPTS= percentiles. PROC UNIVARIATE creates a variable name by combining the PCTLPRE= value and suffix name. Because the suffix names are associated with the percentiles that are requested, list the suffix names in the same order as the PCTLPTS= percentiles. If you specify
 suffixes with the PCTLNAME= option and
suffixes with the PCTLNAME= option and  percentile values with the PCTLPTS= option where
percentile values with the PCTLPTS= option where 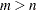 , the suffixes are used to name the first percentiles and the default names are used for the remaining
, the suffixes are used to name the first percentiles and the default names are used for the remaining  percentiles. For example, consider the following statements:
percentiles. For example, consider the following statements: proc univariate; var Length Width Height; output pctlpts = 20 40 pctlpre = pl pw ph pctlname = twenty; run;The value twenty in the PCTLNAME= option is used for only the first percentile in the PCTLPTS= list. This suffix is appended to the values in the PCTLPRE= option to generate the new variable names pltwenty, pwtwenty, and phtwenty, which contain the 20th percentiles for Length, Width, and Height, respectively. Because a second PCTLNAME= suffix is not specified, variable names for the 40th percentiles for Length, Width, and Height are generated using the prefixes and percentile values. Thus, the output data set contains the variables pltwenty, pl40, pwtwenty, pw40, phtwenty, and ph40.
You must specify PCTLPRE= to supply prefix names for the variables that contain the PCTLPTS= percentiles.
If the number of PCTLNAME= values is fewer than the number of percentiles or if you omit PCTLNAME=, PROC UNIVARIATE uses the percentile as the suffix to create the name of the variable that contains the percentile. For an integer percentile, PROC UNIVARIATE uses the percentile. Otherwise, PROC UNIVARIATE truncates decimal values of percentiles to two decimal places and replaces the decimal point with an underscore.
If either the prefix and suffix name combination or the prefix and percentile name combination is longer than 32 characters, PROC UNIVARIATE truncates the prefix name so that the variable name is 32 characters.
- PCTLNDEC=value
-
specifies the number of decimal places in percentile values that are incorporated into percentile variable names. The default value is 2. For example, the following statements create two output data sets, each containing one percentile variable. The variable in data set short is named pwid85_12, while the one in data set long is named pwid85_125.
proc univariate; var width; output out=short pctlpts=85.125 pctlpre=pwid; output out=long pctlpts=85.125 pctlpre=pwid pctlndec=3; run;