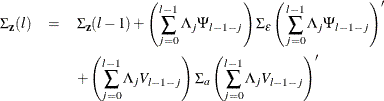The VARMAX Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsMissing ValuesVARMAX ModelDynamic Simultaneous Equations ModelingImpulse Response FunctionForecastingTentative Order SelectionVAR and VARX ModelingBayesian VAR and VARX ModelingVARMA and VARMAX ModelingModel Diagnostic ChecksCointegrationVector Error Correction ModelingI(2) ModelMultivariate GARCH ModelingOutput Data SetsOUT= Data SetOUTEST= Data SetOUTHT= Data SetOUTSTAT= Data SetPrinted OutputODS Table NamesODS GraphicsComputational Issues
-
Examples
- References
The optimal (minimum MSE) l-step-ahead forecast of ![]() is
is
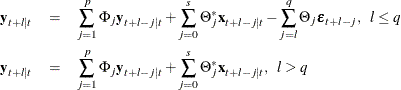
with ![]() and
and ![]() for
for ![]() . For the forecasts
. For the forecasts ![]() , see the section State-Space Representation.
, see the section State-Space Representation.
Under the stationarity assumption, the optimal (minimum MSE) l-step-ahead forecast of ![]() has an infinite moving-average form,
has an infinite moving-average form, ![]() . The prediction error of the optimal l-step-ahead forecast is
. The prediction error of the optimal l-step-ahead forecast is ![]() , with zero mean and covariance matrix,
, with zero mean and covariance matrix,
where ![]() with a lower triangular matrix
with a lower triangular matrix ![]() such that
such that ![]() . Under the assumption of normality of the
. Under the assumption of normality of the ![]() , the l-step-ahead prediction error
, the l-step-ahead prediction error ![]() is also normally distributed as multivariate
is also normally distributed as multivariate ![]() . Hence, it follows that the diagonal elements
. Hence, it follows that the diagonal elements ![]() of
of ![]() can be used, together with the point forecasts
can be used, together with the point forecasts ![]() , to construct l-step-ahead prediction intervals of the future values of the component series,
, to construct l-step-ahead prediction intervals of the future values of the component series, ![]() .
.
The following statements use the COVPE option to compute the covariance matrices of the prediction errors for a VAR(1) model. The parts of the VARMAX procedure output are shown in Figure 35.36 and Figure 35.37.
proc varmax data=simul1;
model y1 y2 / p=1 noint lagmax=5
printform=both
print=(decompose(5) impulse=(all) covpe(5));
run;
Figure 35.36 is the output in a matrix format associated with the COVPE option for the prediction error covariance matrices.
Figure 35.37 is the output in a univariate format associated with the COVPE option for the prediction error covariances. This printing format more easily explains the prediction error covariances of each variable.
Exogenous variables can be both stochastic and nonstochastic (deterministic) variables. Considering the forecasts in the VARMAX(p,q,s) model, there are two cases.
When exogenous (independent) variables are stochastic (future values not specified):
As defined in the section State-Space Representation, ![]() has the representation
has the representation
and hence
Therefore, the covariance matrix of the l-step-ahead prediction error is given as
where ![]() is the covariance of the white noise series
is the covariance of the white noise series ![]() , and
, and ![]() is the white noise series for the VARMA(p,q) model of exogenous (independent) variables, which is assumed not to be correlated with
is the white noise series for the VARMA(p,q) model of exogenous (independent) variables, which is assumed not to be correlated with ![]() or its lags.
or its lags.
When future exogenous (independent) variables are specified:
The optimal forecast ![]() of
of ![]() conditioned on the past information and also on known future values
conditioned on the past information and also on known future values ![]() can be represented as
can be represented as
and the forecast error is
Thus, the covariance matrix of the l-step-ahead prediction error is given as
In the relation ![]() , the diagonal elements can be interpreted as providing a decomposition of the l-step-ahead prediction error covariance
, the diagonal elements can be interpreted as providing a decomposition of the l-step-ahead prediction error covariance ![]() for each component series
for each component series ![]() into contributions from the components of the standardized innovations
into contributions from the components of the standardized innovations ![]() .
.
If you denote the (![]() )th element of
)th element of ![]() by
by ![]() , the MSE of
, the MSE of ![]() is
is
Note that ![]() is interpreted as the contribution of innovations in variable n to the prediction error covariance of the l-step-ahead forecast of variable i.
is interpreted as the contribution of innovations in variable n to the prediction error covariance of the l-step-ahead forecast of variable i.
The proportion, ![]() , of the l-step-ahead forecast error covariance of variable i accounting for the innovations in variable n is
, of the l-step-ahead forecast error covariance of variable i accounting for the innovations in variable n is
The following statements use the DECOMPOSE option to compute the decomposition of prediction error covariances and their proportions for a VAR(1) model:
proc varmax data=simul1;
model y1 y2 / p=1 noint print=(decompose(15))
printform=univariate;
run;
The proportions of decomposition of prediction error covariances of two variables are given in Figure 35.38. The output explains that about 91.356% of the one-step-ahead prediction error covariances of the variable ![]() is accounted for by its own innovations and about 8.644% is accounted for by
is accounted for by its own innovations and about 8.644% is accounted for by ![]() innovations.
innovations.
If the CENTER option is specified, the sample mean vector is added to the forecast.
If dependent (endogenous) variables are differenced, the final forecasts and their prediction error covariances are produced by integrating those of the differenced series. However, if the PRIOR option is specified, the forecasts and their prediction error variances of the differenced series are produced.
Let ![]() be the original series with some appended zero values that correspond to the unobserved past observations. Let
be the original series with some appended zero values that correspond to the unobserved past observations. Let ![]() be the
be the ![]() matrix polynomial in the backshift operator that corresponds to the differencing specified by the MODEL statement. The off-diagonal
elements of
matrix polynomial in the backshift operator that corresponds to the differencing specified by the MODEL statement. The off-diagonal
elements of ![]() are zero, and the diagonal elements can be different. Then
are zero, and the diagonal elements can be different. Then ![]() .
.
This gives the relationship
where ![]() and
and ![]() .
.
The l-step-ahead prediction of ![]() is
is
The l-step-ahead prediction error of ![]() is
is
Letting ![]() , the covariance matrix of the l-step-ahead prediction error of
, the covariance matrix of the l-step-ahead prediction error of ![]() ,
, ![]() , is
, is
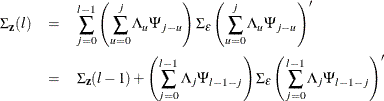
If there are stochastic exogenous (independent) variables, the covariance matrix of the l-step-ahead prediction error of ![]() ,
, ![]() , is
, is