The BCHOICE Procedure

A Simple Logit Model
This example uses a standard logit model in which the error component, 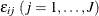 , is independently and identically distributed (iid) with the Type I extreme-value distribution,
, is independently and identically distributed (iid) with the Type I extreme-value distribution, 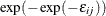 . This assumption provides a convenient form for the choice probability (McFadden 1974):
. This assumption provides a convenient form for the choice probability (McFadden 1974):
![\[ P(y_{ij}=1) = \frac{\exp (\mb{x}_{ij}'\bbeta )}{\sum _{k=1}^{J} \exp (\mb{x}_{ik}'\bbeta )}, ~ ~ ~ ~ i=1, \ldots , N ~ ~ \mbox{and}~ ~ j=1, \ldots , J \]](images/statug_bchoice0014.png)
The likelihood is formed by the product of the N independent multinomial distributions:
![\[ p(\bY | \bbeta ) = \prod _{i=1}^ N \prod _{j=1}^ J P(y_{ij}=1)^{y_{ij}} \]](images/statug_bchoice0015.png)
Suppose you want a normal prior on 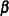
![\[ \pi (\bbeta )=\mbox{N}(\mb{0}, c\bI ) \]](images/statug_bchoice0016.png)
where 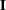 is the identity matrix and c is a scalar. c is often set to be large for a noninformative prior.
is the identity matrix and c is a scalar. c is often set to be large for a noninformative prior.
The posterior density of the parameter is
![\[ p(\bbeta | \bY ) \propto p(\bY | \bbeta ) \pi (\bbeta ) \]](images/statug_bchoice0018.png)
PROC BCHOICE obtains samples from the posterior distribution, produces summary and diagnostic statistics, and saves the posterior samples in an output data set that can be used for further analysis.
In this example (Kuhfeld 2010), each of 10 subjects is presented with eight different chocolate candies and asked to choose one. The eight candies consist
of the 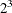 combinations of dark or milk chocolate, soft or chewy center, and nuts or no nuts. Each subject sees all eight alternatives
and makes one choice. Experimental choice data such as these are usually analyzed by using a multinomial logit model.
combinations of dark or milk chocolate, soft or chewy center, and nuts or no nuts. Each subject sees all eight alternatives
and makes one choice. Experimental choice data such as these are usually analyzed by using a multinomial logit model.
The following statements read the data:
title 'Conjoint Analysis of Chocolate Candies'; data Chocs; input Subj Choice Dark Soft Nuts; datalines; 1 0 0 0 0 1 0 0 0 1 1 0 0 1 0 1 0 0 1 1 1 1 1 0 0 1 0 1 0 1 ... more lines ... 10 0 1 0 0 10 1 1 0 1 10 0 1 1 0 10 0 1 1 1 ;
proc print data=Chocs (obs=16); run;
The data for the first two subjects are shown in Figure 27.1.
Figure 27.1: Data for the First Two Subjects
The data set contains 10 subjects and 80 observation lines. Each line of the data represents one alternative in the choice
set for each subject. It is required that the response variable, which is Choice in this study, indicate the chosen alternative by the value 1 and the unchosen alternatives by the value 0. Dark is 1 for dark chocolate and 0 for milk chocolate; Soft is 1 for soft center and 0 for chewy center; Nuts is 1 if the candy contains nuts and 0 if it does not contain nuts. In this example, subject 1 chose the fifth alternative
(Choice=1, which is Dark/Chewy/No Nuts) among the eight alternatives in the choice set. All the chosen and unchosen alternatives
must appear in the data set. If you have choice data in which all alternatives appear on one line, then you must rearrange
the data in the correct form (that is, the data must contain one observation line for each alternative of each choice set
for each subject).
The following statements fit a multinomial logit model:
ods graphics on;
proc bchoice data=Chocs outpost=Bsamp nmc=10000 thin=2 diag=(AutoCorr
ESS MCSE) seed=124;
class Dark(ref='0') Soft(ref='0') Nuts(ref='0') Subj;
model Choice = Dark Soft Nuts / choiceset=(Subj) cprior=normal(var=1000);
run;
The ODS GRAPHICS ON statement invokes the ODS Graphics environment and displays the diagnostic plots, such as the trace and autocorrelation function plots of the posterior samples. For more information about ODS, see Chapter 21: Statistical Graphics Using ODS.
The PROC BCHOICE statement invokes the procedure, and the DATA=
option specifies the input data set Chocs. The OUTPOST=
option requests an output data set called Bsamp to contain all the posterior samples. The NMC=
option specifies the number of posterior simulation iterations. The THIN=
option controls the thinning of the Markov chain and specifies that one of every two samples be kept. Thinning is often used
to reduce correlation among posterior sample draws. In this example, 5,000 simulated values are saved in the Bsamp data set. The DIAG=
(AUTOCORR ESS MCSE) option requests that three convergence diagnostics be output to help determine whether the chain has converged:
the autocorrelations, effective sample sizes, and Monte Carlo standard errors. The SEED=
option specifies a seed for the random number generator, which guarantees the reproducibility of the random stream.
The CLASS statement names the classification variables to be used in the model. The CLASS statement must precede the MODEL statement (as it must in most other SAS procedures). The REF = option specifies the reference level.
The MODEL
statement is required; it defines the dependent variable (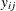 ) and independent variables (
) and independent variables (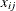 ). To the left of the equal sign in the MODEL
statement, you specify the dependent variable that indicates which alternatives are chosen and which ones are not chosen.
The dependent variable
). To the left of the equal sign in the MODEL
statement, you specify the dependent variable that indicates which alternatives are chosen and which ones are not chosen.
The dependent variable Choice has the value 1 (chosen) or 0 (unchosen). You specify the independent variables after the equal sign. The independent variables
often indicate attributes or characteristics of the alternatives in the choice set, such as Dark, Soft, and Nuts in this example. The CHOICESET
= option specifies how a choice set is defined. In this example, CHOICESET=(Subj) because there is one and only one choice
set per subject. The variable that you specify in the CHOICESET=
option must be a classification variable that appears in the CLASS
statement. Always use the CHOICESET=
option to define the choice set.
The first table that PROC BCHOICE produces is the "Model Information" table, as shown in Figure 27.2. This table displays basic information about the analysis, such as the name of the input data set, response variable, model type, sampling algorithm, burn-in size, simulation size, thinning number, and random number seed. The random number seed initializes the random number generators. If you repeat the analysis and use the same seed, you get an identical stream of random numbers.
Figure 27.2: Model Information
The "Choice Sets Summary" table is displayed by default; you can use it to check the data entry. In this case, there are 10 choice sets, one for each subject. All 10 choice sets display the same pattern: they have a total of eight alternatives, one of which is chosen and seven of which are unchosen. Sometimes there can be more than one pattern among the choice sets (for example, some choice sets have nine alternatives). Logit models can have different patterns as long as each choice set has at least two alternatives in total and only one chosen alternative. If more than one alternative is chosen or no alternative is chosen, the choice set is invalid. PROC BCHOICE deletes all the invalid choice sets and produces a warning message.
Figure 27.3: Choice Sets Summary
The next table is the "Number of Observations" table, as shown in Figure 27.4. This table lists the number of observations that are read from the DATA= data set and the number of nonmissing and valid observations that are used in the analysis. PROC BCHOICE does not impute missing values. If any missing value is encountered in a row of the DATA= data set, PROC BCHOICE skips that row and moves on to read the next row. If the missing value causes the corresponding choice set to be invalid, the entire choice set is discarded from analysis. In this example, all 80 observations are used.
Figure 27.4: Number of Observations
PROC BCHOICE reports posterior summary statistics (posterior means, standard deviations, and HPD intervals) for each parameter, as shown in Figure 27.5. For more information about posterior statistics, see the section Summary Statisticsin Chapter 7: Introduction to Bayesian Analysis Procedures.
Figure 27.5: PROC BCHOICE Posterior Summary Statistics
Before you examine the posterior summary statistics and try to draw any conclusions, you might want to verify that the simulation has converged. Convergence diagnostics are essential to inferring from simulations that are based on Markov chains. If the Markov chain has not converged, all conclusions that are based on the samples might be misleading. PROC BCHOICE computes the effective sample size by default. There are a number of other convergence diagnostics to help you determine whether the chain has converged: the Monte Carlo standard errors, the autocorrelations at selected lags, and so on. These statistics are shown in Figure 27.6. For details and interpretations of these diagnostics, see the section Assessing Markov Chain Convergence in Chapter 7: Introduction to Bayesian Analysis Procedures.
The "Posterior Autocorrelations" table shows that the autocorrelations among posterior samples reduce quickly. The "Effective Sample Sizes" table reports the number of effective sample sizes of the Markov chain. The "Monte Carlo Standard Errors" table indicates that the standard errors of the mean estimates for each of the variables are relatively small with respect to the posterior standard deviations. The values in the MCSE/SD column (ratios of the standard errors and the standard deviations) are small. This means that only a fraction of the posterior variability is caused by the simulation.
Figure 27.6: PROC BCHOICE Convergence Diagnostics
PROC BCHOICE produces a number of graphs, shown in Figure 27.7, which also aid convergence diagnostic checks. The trace plots have two important aspects to examine. First, you want to check whether the mean of the Markov chain has stabilized and appears constant over the graph. Second, you want to check whether the chain has good mixing and is "dense," in the sense that it quickly traverses the support of the distribution to explore both the tails and the mode areas efficiently. The plots show that the chains appear to have reached their stationary distributions.
Next, you want to examine the autocorrelation plots, which indicate the degree of autocorrelation for each of the posterior samples. High correlations usually imply slow mixing. Finally, the kernel density plots estimate the posterior marginal distributions for each parameter.
Figure 27.7: PROC BCHOICE Diagnostic Plots
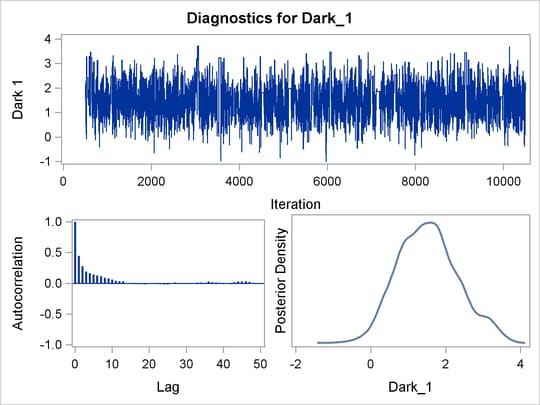
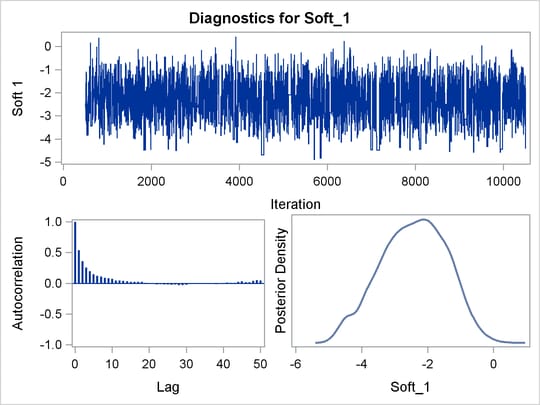
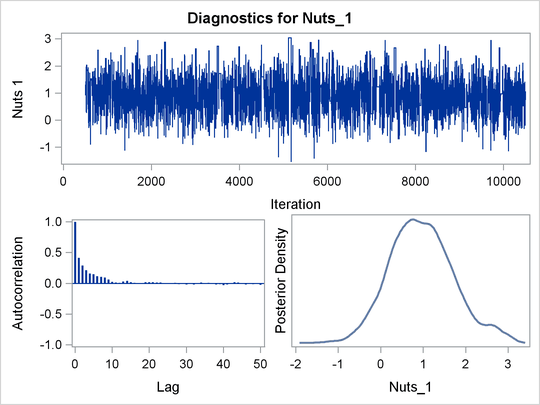
Because the chains seem to have reached their stationary distributions, you can go back to the posterior summary table for results and conclusions. As seen in Figure 27.5, the part-worth for dark chocolate is 1.5 and the part-worth for milk chocolate (base category) is structural 0; the part-worth for soft center is –2.4 and the part-worth for chewy center is structural 0; the part-worth for containing nuts is 1.0 and the part-worth for no nuts is structural 0. A positive part-worth implies being more favorable. Hence, dark chocolate is preferred over milk chocolate, soft centers are less popular than chewy centers, and candies with nuts are more popular than candies without nuts.