The BCHOICE Procedure

Example 27.3 Probit Modeling
A more general model is the probit model, which is derived under the assumption of jointly normal random utility components,
where the error vector has a multivariate normal distribution with a mean vector of 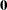 and a covariance matrix
and a covariance matrix 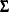 . For a full covariance matrix, PROC BCHOICE can accommodate any pattern of correlation and heteroscedasticity. Thus, this
model fits a very general error structure. For more information about probit models, see the section Probit.
. For a full covariance matrix, PROC BCHOICE can accommodate any pattern of correlation and heteroscedasticity. Thus, this
model fits a very general error structure. For more information about probit models, see the section Probit.
In Train (2009), a project team collected the following data from commuters about four available travel modes for their trips to work: car alone, carpool, bus, and railway. The time and cost of travel for each mode were determined for each commuter, based on the location of the commuter’s home and workplace.
data Commuter; input Subject Mode Choice Cost Time @@; datalines; 1 1 1 1.51 18.5 1 2 0 2.34 26.34 1 3 0 1.8 20.87 1 4 0 2.36 30.03 2 1 0 6.06 31.31 2 2 0 2.9 34.26 2 3 0 2.24 67.18 2 4 1 1.86 60.29 3 1 1 5.79 22.55 3 2 0 2.14 23.26 3 3 0 2.58 63.31 3 4 0 2.75 49.17 4 1 1 1.87 26.09 4 2 0 2.57 29.9 4 3 0 1.9 19.75 4 4 0 2.27 13.47 5 1 1 2.5 4.7 5 2 0 1.72 12.41 5 3 0 2.69 43.09 5 4 0 2.97 39.74 6 1 1 4.73 3.07 6 2 0 0.62 9.22 6 3 0 1.85 12.83 6 4 0 2.31 43.54 7 1 1 4.73 13.14 7 2 0 0.6 17.77 7 3 0 2.43 54.09 7 4 0 2 42.22 8 1 1 5.35 52.9 8 2 0 2.91 48.78 8 3 0 2.61 69.16 8 4 0 2.78 53.25 9 1 0 4.41 61.06 9 2 0 1.59 62.13 9 3 1 ... more lines ... 450 1 1 4.59 29.44 450 2 0 2.89 33.73 450 3 0 1.9 66.12 450 4 0 1.79 39.84 451 1 1 3.24 16.35 451 2 0 1.21 18.98 451 3 0 1.75 23.39 451 4 0 2.02 43.3 452 1 0 6.93 65.42 452 2 0 1.17 60.48 452 3 1 2.46 52.4 452 4 0 2.61 48.37 453 1 0 6.53 59.57 453 2 1 1.41 55.14 453 3 0 2.21 67.82 453 4 0 1.86 73.45 ;
proc print data=Commuter(obs=20); run;
The variable Mode has the value 1 for car alone, 2 for carpool, 3 for bus, and 4 for railway. The variable Choice is the response variable that represents the decision among the four travel modes for each commuter. The order in which the
alternatives appear in a choice set is important: the variable Mode should have the value 1 in the first alternative, 2 in the second alternative, then 3 in the third alternative, and finally
4 in the last alternative. The data for the first five commuters are shown in Output 27.3.1.
Output 27.3.1: Data for the First Five Commuters
| Obs | Subject | Mode | Choice | Cost | Time |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1.51 | 18.50 |
| 2 | 1 | 2 | 0 | 2.34 | 26.34 |
| 3 | 1 | 3 | 0 | 1.80 | 20.87 |
| 4 | 1 | 4 | 0 | 2.36 | 30.03 |
| 5 | 2 | 1 | 0 | 6.06 | 31.31 |
| 6 | 2 | 2 | 0 | 2.90 | 34.26 |
| 7 | 2 | 3 | 0 | 2.24 | 67.18 |
| 8 | 2 | 4 | 1 | 1.86 | 60.29 |
| 9 | 3 | 1 | 1 | 5.79 | 22.55 |
| 10 | 3 | 2 | 0 | 2.14 | 23.26 |
| 11 | 3 | 3 | 0 | 2.58 | 63.31 |
| 12 | 3 | 4 | 0 | 2.75 | 49.17 |
| 13 | 4 | 1 | 1 | 1.87 | 26.09 |
| 14 | 4 | 2 | 0 | 2.57 | 29.90 |
| 15 | 4 | 3 | 0 | 1.90 | 19.75 |
| 16 | 4 | 4 | 0 | 2.27 | 13.47 |
| 17 | 5 | 1 | 1 | 2.50 | 4.70 |
| 18 | 5 | 2 | 0 | 1.72 | 12.41 |
| 19 | 5 | 3 | 0 | 2.69 | 43.09 |
| 20 | 5 | 4 | 0 | 2.97 | 39.74 |
The following statements fit a probit model by specifying TYPE =PROBIT. The BCHOICE procedure’s implementation of the Gibbs sampler for the probit model exhibits a higher autocorrelation than that for the logit model. High autocorrelation is created by introducing the latent variable via data augmentation because of the dependence between the latent variable and the regression parameters. You might want to control the thinning rate of the simulation. For example, THIN =10 keeps every 10th sample in the simulation and discards the rest.
proc bchoice data=Commuter outpost=Commupostsamp thin=10 nmc=100000 seed=123; class Mode(ref='1') Subject; model Choice = Cost Time Mode / choiceset=(Subject) type=probit; run;
Output 27.3.2 shows the summary statistics for the part-worth (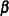 ) of each of the attributes (
) of each of the attributes (Cost, Time, Mode 2, Mode 3, and Mode 4) and the covariance of the error difference vector (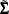 ), which is displayed by parameters labeled "Sigma 1 1," "Sigma 2 1," and so on.
), which is displayed by parameters labeled "Sigma 1 1," "Sigma 2 1," and so on.
Output 27.3.2: Posterior Summary Statistics
| Posterior Summaries and Intervals | |||||
|---|---|---|---|---|---|
| Parameter | N | Mean | Standard Deviation |
95% HPD Interval | |
| Cost | 10000 | -0.4643 | 0.0753 | -0.6206 | -0.3280 |
| Time | 10000 | -0.0495 | 0.00569 | -0.0610 | -0.0386 |
| Mode 2 | 10000 | -3.4074 | 0.7458 | -4.8666 | -2.0469 |
| Mode 3 | 10000 | -2.0063 | 0.2904 | -2.5885 | -1.4614 |
| Mode 4 | 10000 | -1.6257 | 0.2123 | -2.0489 | -1.2241 |
| Sigma 1 1 | 10000 | 1.0000 | 0 | 1.0000 | 1.0000 |
| Sigma 2 1 | 10000 | 1.1620 | 0.5604 | 0.0427 | 2.2958 |
| Sigma 2 2 | 10000 | 4.4616 | 2.2789 | 1.2285 | 8.7152 |
| Sigma 3 1 | 10000 | 0.5645 | 0.2149 | 0.1426 | 0.9928 |
| Sigma 3 2 | 10000 | 1.5985 | 0.9345 | -0.0286 | 3.6894 |
| Sigma 3 3 | 10000 | 1.3834 | 0.4737 | 0.5985 | 2.3179 |
It is well known that an identification problem exists in probit models, because location and scale transformations do not
change the choices that are made. The solution to the location shift is differencing with respect to the last alternative
in each choice set. (See the section Probit.) After that, a scale shift problem remains, because the parameters 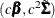 for any constant
for any constant 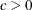 are equivalent to
are equivalent to 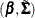 . A solution to the scaling problem is to normalize the parameters with respect to one of the diagonal elements of the covariance
of the error difference vector, . PROC BCHOICE reports
. A solution to the scaling problem is to normalize the parameters with respect to one of the diagonal elements of the covariance
of the error difference vector, . PROC BCHOICE reports 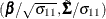 at each draw, where
at each draw, where 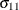 is the first diagonal entry of . This explains why "Sigma 1 1" is always 1 in Output 27.3.2.
is the first diagonal entry of . This explains why "Sigma 1 1" is always 1 in Output 27.3.2.
By the IIA property in a logit model, it is assumed that all alternatives are independent and have the same variance. Therefore, the normalized covariance matrix after differencing with respect to one of the alternatives is of the form
![\[ \tilde\bSigma = \begin{pmatrix} 1 & 0.5 & 0.5 \\ 0.5 & 1 & 0.5 \\ 0.5 & 0.5 & 1 \end{pmatrix} \]](images/statug_bchoice0213.png)
Obviously, this matrix is quite different from the estimated normalized covariance matrix for this data set. Fitting a standard logit model would be inappropriate.