The MCMC Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsHow PROC MCMC WorksBlocking of ParametersSampling MethodsTuning the Proposal DistributionDirect SamplingConjugate SamplingInitial Values of the Markov ChainsAssignments of ParametersStandard DistributionsUsage of Multivariate DistributionsSpecifying a New DistributionUsing Density Functions in the Programming StatementsTruncation and CensoringSome Useful SAS FunctionsMatrix Functions in PROC MCMCCreate Design MatrixModeling Joint LikelihoodRegenerating Diagnostics PlotsCaterpillar PlotAutocall Macros for PostprocessingGamma and Inverse-Gamma DistributionsPosterior Predictive DistributionHandling of Missing DataFunctions of Random-Effects ParametersFloating Point Errors and OverflowsHandling Error MessagesComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesSimulating Samples From a Known DensityBox-Cox TransformationLogistic Regression Model with a Diffuse PriorLogistic Regression Model with Jeffreys’ PriorPoisson RegressionNonlinear Poisson Regression ModelsLogistic Regression Random-Effects ModelNonlinear Poisson Regression Multilevel Random-Effects ModelMultivariate Normal Random-Effects ModelMissing at Random AnalysisNonignorably Missing Data (MNAR) AnalysisChange Point ModelsExponential and Weibull Survival AnalysisTime Independent Cox ModelTime Dependent Cox ModelPiecewise Exponential Frailty ModelNormal Regression with Interval CensoringConstrained AnalysisImplement a New Sampling AlgorithmUsing a Transformation to Improve MixingGelman-Rubin Diagnostics
- References
This example illustrates how to fit a nonlinear Poisson regression with PROC MCMC. In addition, it shows how you can improve the mixing of the Markov chain by selecting a different proposal distribution or by sampling on the transformed scale of a parameter. This example shows how to analyze count data for calls to a technical support help line in the weeks immediately following a product release. This information could be used to decide upon the allocation of technical support resources for new products. You can model the number of daily calls as a Poisson random variable, with the average number of calls modeled as a nonlinear function of the number of weeks that have elapsed since the product’s release. The data are input into a SAS data set as follows:
title 'Nonlinear Poisson Regression'; data calls; input weeks calls @@; datalines; 1 0 1 2 2 2 2 1 3 1 3 3 4 5 4 8 5 5 5 9 6 17 6 9 7 24 7 16 8 23 8 27 ;
During the first several weeks after a new product is released, the number of questions that technical support receives concerning
the product increases in a sigmoidal fashion. The expression for the mean value in the classic Poisson regression involves
the log link. There is some theoretical justification for this link, but with MCMC methodologies, you are not constrained
to exploring only models that are computationally convenient. The number of calls to technical support tapers off after the
initial release, so in this example you can use a logistic-type function to model the mean number of calls received weekly
for the time period immediately following the initial release. The mean function ![]() is modeled as follows:
is modeled as follows:
The likelihood for every observation ![]() is
is
Past experience with technical support data for similar products suggests the following prior distributions:
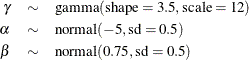
The following PROC MCMC statements fit this model:
ods graphics on;
proc mcmc data=calls outpost=callout seed=53197 ntu=1000 nmc=20000
propcov=quanew stats=none diag=ess;
ods select TADpanel ess;
parms alpha -4 beta 1 gamma 2;
prior gamma ~ gamma(3.5, scale=12);
prior alpha ~ normal(-5, sd=0.25);
prior beta ~ normal(0.75, sd=0.5);
lambda = gamma*logistic(alpha+beta*weeks);
model calls ~ poisson(lambda);
run;
The one PARMS
statement defines a block of all parameters and sets their initial values individually. The PRIOR
statements specify the informative prior distributions for the three parameters. The assignment statement defines ![]() , the mean number of calls. Instead of using the SAS function LOGISTIC, you can use the following statement to calculate
, the mean number of calls. Instead of using the SAS function LOGISTIC, you can use the following statement to calculate ![]() and get the same result:
and get the same result:
lambda = gamma / (1 + exp(-(alpha+beta*weeks)));
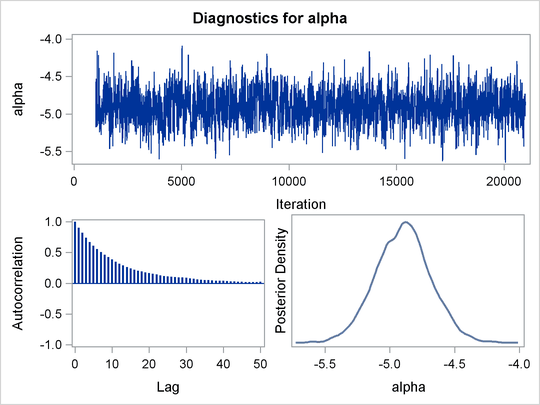
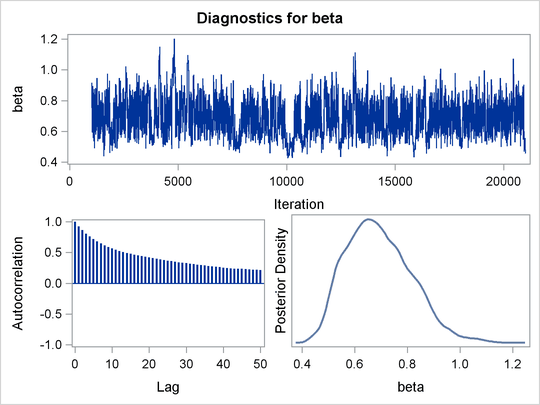
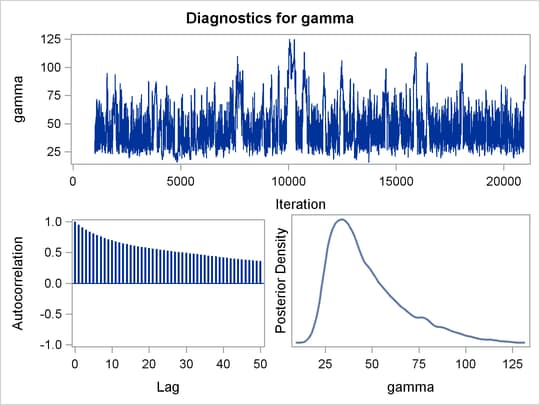
Mixing is not particularly good with this run of PROC MCMC. The ODS SELECT statement displays the diagnostic graphs and effective sample sizes (ESS) calculation while excluding all other output. The graphical output is shown in Output 61.6.1, and the ESS of each parameters are all relatively low (Output 61.6.2).
Often a simple scatter plot of the posterior samples can reveal a potential cause of the bad mixing. You can use PROC SGSCATTER to generate pairwise scatter plots of the three model parameters. The following statements generate Output 61.6.3:
proc sgscatter data=callout; matrix alpha beta gamma; run;
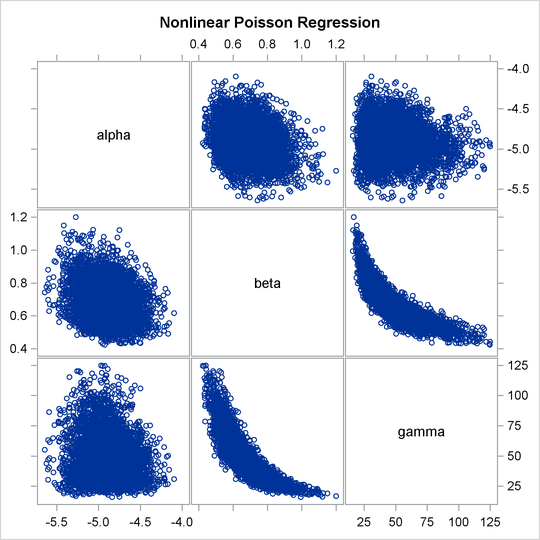
The nonlinearity in parameters beta and gamma stands out immediately. This explains why a random walk Metropolis with normal proposal has a difficult time exploring the
joint distribution efficiently—the algorithm works best when the target distribution is unimodal and symmetric (normal-like).
When there is nonlinearity in the parameters, it is impossible to find a single proposal scale parameter that optimally adapts
to different regions of the joint parameter space. As a result, the Markov chain can be inefficient in traversing some parts
of the distribution. This is evident in examining the trace plot of the gamma parameter. You see that the Markov chain sometimes gets stuck in the far-right tail and does not travel back to the high-density
area quickly. This effect can be seen around the simulations 8,000 and 18,000 in Output 61.6.1.
Reparameterization can often improve the mixing of the Markov chain. Note that the parameter gamma has a positive support and that the posterior distribution is right-skewed. This suggests that the chain might mix more rapidly
if you sample on the logarithm of the parameter gamma.
Let ![]() , and reparameterize the mean function as follows:
, and reparameterize the mean function as follows:
To obtain the same inference, you use an induced prior on delta based on the gamma prior on the gamma parameter. This involves a transformation of variables, and you can obtain the following equivalency, where ![]() is the Jacobian:
is the Jacobian:
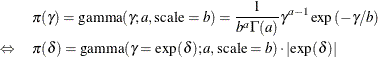
The distribution on ![]() simplifies to the following:
simplifies to the following:
PROC MCMC supports such a distribution on the logarithm transformation of a gamma random variable. It is called the ExpGamma distribution.
In the original model, you specify a prior on gamma:
prior gamma ~ gamma(3.5, scale=12);
You can obtain the same inference by specifying an ExpGamma
prior on delta and take an exponential transformation to get back to gamma:
prior delta ~ egamma(3.5, scale=12); gamma = exp(delta);
The following statements produce Output 61.6.6 and Output 61.6.4:
proc mcmc data=calls outpost=tcallout seed=53197 ntu=1000 nmc=20000
propcov=quanew diag=ess plots=(trace) monitor=(alpha beta gamma);
ods select PostSumInt ESS TRACEpanel;
parms alpha -4 beta 1 delta 2;
prior alpha ~ normal(-5, sd=0.25);
prior beta ~ normal(0.75, sd=0.5);
prior delta ~ egamma(3.5, scale=12);
gamma = exp(delta);
lambda = gamma*logistic(alpha+beta*weeks);
model calls ~ poisson(lambda);
run;
The PARMS
statement declares delta, instead of gamma, as a model parameter. The prior distribution of delta is egamma, as opposed to the gamma distribution. The GAMMA assignment statement transforms delta to gamma. The LAMBDA assignment statement calculates the mean for the Poisson by using the gamma parameter. The MODEL
statement specifies a Poisson likelihood for the calls response.
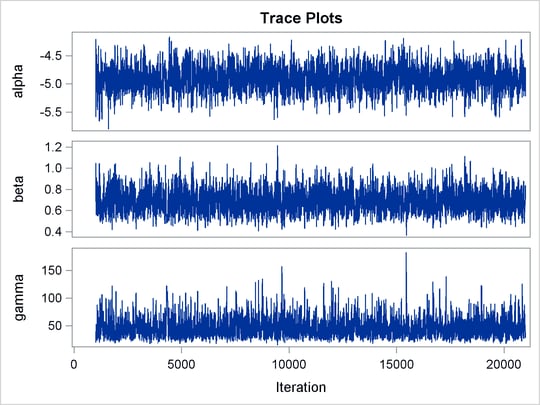
The trace plots in Output 61.6.4 show better mixing of the parameters, and the effective sample sizes in Output 61.6.5 show substantial improvements over the original formulation of the model. The improvements are especially obvious in beta and gamma, where the increase is fivefold to tenfold.
Output 61.6.6 shows the posterior summary and interval statistics of the nonlinear Poisson regression.
Note that the delta parameter has a more symmetric density than the skewed gamma parameter. A pairwise scatter plot (Output 61.6.7) shows a more linear relationship between beta and delta. The Metropolis algorithm always works better if the target distribution is approximately normal.
proc sgscatter data=tcallout; matrix alpha beta delta; run;
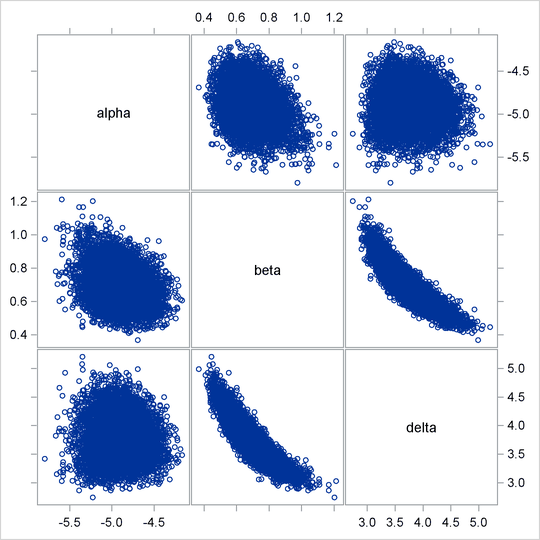
If you are still unsatisfied with the slight nonlinearity in the parameters beta and delta, you can try another transformation on beta. Normally you would not want to do a logarithm transformation on a parameter that has support on the real axis, because you
would risk taking the logarithm of negative values. However, because all the beta samples are positive and the marginal posterior distribution is away from 0, you can try a such a transformation.
Let ![]() . The prior distribution on
. The prior distribution on ![]() is the following:
is the following:
You can specify the prior distribution in PROC MCMC by using a GENERAL function:
parms kappa;
lprior = logpdf("normal", exp(kappa), 0.75, 0.5) + kappa;
prior kappa ~ general(lp);
beta = exp(kappa);
The PARMS
statement declares the transformed parameter kappa, which will be sampled. The LPRIOR assignment statement defines the logarithm of the prior distribution on kappa. The LOGPDF function is used here to simplify the specification of the distribution. The PRIOR
statement specifies the nonstandard distribution as the prior on kappa. Finally, the BETA assignment statement transforms kappa back to the beta parameter.
Applying logarithm transformations on both beta and gamma yields the best mixing. (The results are not shown here, but you can find the code in the file mcmcex6.sas in the SAS Sample Library.) The transformed parameters kappa and delta have much clearer linear correlation. However, the improvement over the case where gamma alone is transformed is only marginally significant (50% increase in ESS).
This example illustrates that PROC MCMC can fit Bayesian nonlinear models just as easily as Bayesian linear models. More importantly, transformations can sometimes improve the efficiency of the Markov chain, and that is something to always keep in mind. Also see Using a Transformation to Improve Mixing for another example of how transformations can improve mixing of the Markov chains.