The MI Procedure
- Overview
- Getting Started
-
Syntax

-
Details
Descriptive Statistics EM Algorithm for Data with Missing Values Statistical Assumptions for Multiple Imputation Missing Data Patterns Imputation Methods Monotone Methods for Data Sets with Monotone Missing Patterns Monotone and FCS Regression Methods Monotone and FCS Predictive Mean Matching Methods Monotone Propensity Score Method Monotone and FCS Discriminant Function Methods Monotone and FCS Logistic Regression Methods FCS Methods for Data Sets with Arbitrary Missing Patterns Checking Convergence in FCS Methods MCMC Method for Arbitrary Missing Multivariate Normal Data Producing Monotone Missingness with the MCMC Method MCMC Method Specifications Checking Convergence in MCMC Input Data Sets Output Data Sets Combining Inferences from Multiply Imputed Data Sets Multiple Imputation Efficiency Imputer’s Model Versus Analyst’s Model Parameter Simulation versus Multiple Imputation Summary of Issues in Multiple Imputation ODS Table Names ODS Graphics
-
Examples
EM Algorithm for MLE Monotone Propensity Score Method Monotone Regression Method Monotone Logistic Regression Method for CLASS Variables Monotone Discriminant Function Method for CLASS Variables FCS Method for Continuous Variables FCS Method for CLASS Variables FCS Method with Trace Plot MCMC Method Producing Monotone Missingness with MCMC Checking Convergence in MCMC Saving and Using Parameters for MCMC Transforming to Normality Multistage Imputation
- References
| Statistical Assumptions for Multiple Imputation |
The MI procedure assumes that the data are from a continuous multivariate distribution and contain missing values that can occur for any of the variables. It also assumes that the data are from a multivariate normal distribution when either the regression method or the MCMC method is used.
Suppose 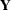 is the
is the 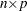 matrix of complete data, which is not fully observed, and denote the observed part of by
matrix of complete data, which is not fully observed, and denote the observed part of by 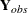 and the missing part by
and the missing part by 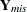 . The MI and MIANALYZE procedures assume that the missing data are missing at random (MAR); that is, the probability that an observation is missing can depend on , but not on (Rubin 1976; 1987, p. 53).
. The MI and MIANALYZE procedures assume that the missing data are missing at random (MAR); that is, the probability that an observation is missing can depend on , but not on (Rubin 1976; 1987, p. 53).
To be more precise, suppose that 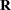 is the matrix of response indicators whose elements are zero or one depending on whether the corresponding elements of Y are missing or observed. Then the MAR assumption is that the distribution of can depend on
is the matrix of response indicators whose elements are zero or one depending on whether the corresponding elements of Y are missing or observed. Then the MAR assumption is that the distribution of can depend on 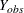 but not on
but not on 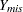 :
:
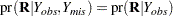 |
For example, consider a trivariate data set with variables 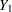 and
and 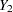 fully observed, and a variable
fully observed, and a variable 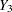 that has missing values. MAR assumes that the probability that is missing for an individual can be related to the individual’s values of variables and , but not to its value of . On the other hand, if a complete case and an incomplete case for with exactly the same values for variables and have systematically different values, then there exists a response bias for , and MAR is violated.
that has missing values. MAR assumes that the probability that is missing for an individual can be related to the individual’s values of variables and , but not to its value of . On the other hand, if a complete case and an incomplete case for with exactly the same values for variables and have systematically different values, then there exists a response bias for , and MAR is violated.
The MAR assumption is not the same as missing completely at random (MCAR), which is a special case of MAR. Under the MCAR assumption, the missing data values are a simple random sample of all data values; the missingness does not depend on the values of any variables in the data set.
Although the MAR assumption cannot be verified with the data and it can be questionable in some situations, the assumption becomes more plausible as more variables are included in the imputation model (Schafer 1997, pp. 27–28; van Buuren, Boshuizen, and Knook, 1999, p. 687).
Furthermore, the MI and MIANALYZE procedures assume that the parameters 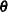 of the data model and the parameters
of the data model and the parameters 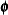 of the model for the missing-data indicators are distinct. That is, knowing the values of does not provide any additional information about , and vice versa. If both the MAR and distinctness assumptions are satisfied, the missing-data mechanism is said to be ignorable (Rubin 1987, pp. 50–54; Schafer 1997, pp. 10–11) .
of the model for the missing-data indicators are distinct. That is, knowing the values of does not provide any additional information about , and vice versa. If both the MAR and distinctness assumptions are satisfied, the missing-data mechanism is said to be ignorable (Rubin 1987, pp. 50–54; Schafer 1997, pp. 10–11) .