The MI Procedure
- Overview
- Getting Started
-
Syntax

-
Details
Descriptive Statistics EM Algorithm for Data with Missing Values Statistical Assumptions for Multiple Imputation Missing Data Patterns Imputation Methods Monotone Methods for Data Sets with Monotone Missing Patterns Monotone and FCS Regression Methods Monotone and FCS Predictive Mean Matching Methods Monotone Propensity Score Method Monotone and FCS Discriminant Function Methods Monotone and FCS Logistic Regression Methods FCS Methods for Data Sets with Arbitrary Missing Patterns Checking Convergence in FCS Methods MCMC Method for Arbitrary Missing Multivariate Normal Data Producing Monotone Missingness with the MCMC Method MCMC Method Specifications Checking Convergence in MCMC Input Data Sets Output Data Sets Combining Inferences from Multiply Imputed Data Sets Multiple Imputation Efficiency Imputer’s Model Versus Analyst’s Model Parameter Simulation versus Multiple Imputation Summary of Issues in Multiple Imputation ODS Table Names ODS Graphics
-
Examples
EM Algorithm for MLE Monotone Propensity Score Method Monotone Regression Method Monotone Logistic Regression Method for CLASS Variables Monotone Discriminant Function Method for CLASS Variables FCS Method for Continuous Variables FCS Method for CLASS Variables FCS Method with Trace Plot MCMC Method Producing Monotone Missingness with MCMC Checking Convergence in MCMC Saving and Using Parameters for MCMC Transforming to Normality Multistage Imputation
- References
Overview: MI Procedure
Missing values are an issue in a substantial number of statistical analyses. Most SAS statistical procedures exclude observations with any missing variable values from the analysis. These observations are called incomplete cases. While using only complete cases is simple, you lose information that is in the incomplete cases. Excluding observations with missing values also ignores the possible systematic difference between the complete cases and incomplete cases, and the resulting inference might not be applicable to the population of all cases, especially with a smaller number of complete cases.
Some SAS procedures use all the available cases in an analysis—that is, cases with useful information. For example, the CORR procedure estimates a variable mean by using all cases with nonmissing values for this variable, ignoring the possible missing values in other variables. The CORR procedure also estimates a correlation by using all cases with nonmissing values for this pair of variables. This estimation might make better use of the available data, but the resulting correlation matrix might not be positive definite.
Another strategy is single imputation, in which you substitute a value for each missing value. Standard statistical procedures for complete data analysis can then be used with the filled-in data set. For example, each missing value can be imputed from the variable mean of the complete cases. This approach treats missing values as if they were known in the complete-data analyses. Single imputation does not reflect the uncertainty about the predictions of the unknown missing values, and the resulting estimated variances of the parameter estimates are biased toward zero (Rubin 1987, p. 13).
Instead of filling in a single value for each missing value, multiple imputation replaces each missing value with a set of plausible values that represent the uncertainty about the right value to impute (Rubin 1976, 1987). The multiply imputed data sets are then analyzed by using standard procedures for complete data and combining the results from these analyses. No matter which complete-data analysis is used, the process of combining results from different data sets is essentially the same.
Multiple imputation does not attempt to estimate each missing value through simulated values, but rather to represent a random sample of the missing values. This process results in valid statistical inferences that properly reflect the uncertainty due to missing values; for example, valid confidence intervals for parameters.
Multiple imputation inference involves three distinct phases:
The missing data are filled in m times to generate m complete data sets.
The m complete data sets are analyzed by using standard procedures.
The results from the m complete data sets are combined for the inference.
The MI procedure is a multiple imputation procedure that creates multiply imputed data sets for incomplete p-dimensional multivariate data. It uses methods that incorporate appropriate variability across the m imputations. The imputation method of choice depends on the patterns of missingness in the data and the type of the imputed variable.
A data set with variables 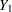 ,
, 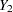 , ...,
, ..., 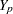 (in that order) is said to have a monotone missing pattern when the event that a variable
(in that order) is said to have a monotone missing pattern when the event that a variable 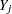 is missing for a particular individual implies that all subsequent variables
is missing for a particular individual implies that all subsequent variables 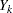 ,
, 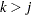 , are missing for that individual.
, are missing for that individual.
For data sets with monotone missing patterns, the variables with missing values can be imputed sequentially with covariates constructed from their corresponding sets of preceding variables. To impute missing values for a continuous variable, you can use a regression method (Rubin 1987, pp. 166–167), a predictive mean matching method (Heitjan and Little 1991; Schenker and Taylor 1996), or a propensity score method (Rubin 1987, pp. 124, 158; Lavori, Dawson, and Shera 1995). To impute missing values for a classification variable, you can use a logistic regression method when the classification variable has a binary or ordinal response, or use a discriminant function method when the classification variable has a binary or nominal response.
For data sets with arbitrary missing patterns, you can use either of the following methods to impute missing values: a Markov chain Monte Carlo (MCMC) method (Schafer 1997) that assumes multivariate normality, or a fully conditional specification (FCS) method (Brand 1999; van Buuren 2007) that assumes the existence of a joint distribution for all variables.
You can use the MCMC method to impute either all the missing values or just enough missing values to make the imputed data sets have monotone missing patterns. With a monotone missing data pattern, you have greater flexibility in your choice of imputation models, such as the monotone regression method that do not use Markov chains. You can also specify a different set of covariates for each imputed variable.
An FCS method does not start with an explicitly specified multivariate distribution for all variables, but rather uses a separate conditional distribution for each imputed variable. For each imputation, the process contains two phases: the preliminary filled-in phase followed by the imputation phase. At the filled-in phase, the missing values for all variables are filled in sequentially over the variables taken one at a time. These filled-in values provide starting values for these missing values at the imputation phase. At the imputation phase, the missing values for each variable are imputed sequentially for a number of burn-in iterations before the imputation.
For each imputation, the process begins with the filling in of all missing values sequentially over the variables taken one at a time, and then these filled-in values are imputed sequentially over the variables at each of the burn-in iterations before the imputation.
As in methods for data sets with monotone missing patterns, you can use a regression method or a predictive mean matching method to impute missing values for a continuous variable, a logistic regression method to impute missing values for a classification variable with a binary or ordinal response, and a discriminant function method to impute missing values for a classification variable with a binary or nominal response.
After the m complete data sets are analyzed using standard SAS procedures, the MIANALYZE procedure can be used to generate valid statistical inferences about these parameters by combining results from the m analyses.
Often, as few as three to five imputations are adequate in multiple imputation (Rubin 1996, p. 480). The relative efficiency of the small  imputation estimator is high for cases with little missing information (Rubin 1987, p. 114). (Also see the section Multiple Imputation Efficiency.)
imputation estimator is high for cases with little missing information (Rubin 1987, p. 114). (Also see the section Multiple Imputation Efficiency.)
Multiple imputation inference assumes that the model (variables) you used to analyze the multiply imputed data (the analyst’s model) is the same as the model used to impute missing values in multiple imputation (the imputer’s model). But in practice, the two models might not be the same. The consequences for different scenarios (Schafer 1997, pp. 139–143) are discussed in the section Imputer’s Model Versus Analyst’s Model.