The HPSEVERITY Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsPredefined DistributionsCensoring and TruncationParameter Estimation MethodDetails of Optimization AlgorithmsParameter InitializationEstimating Regression EffectsEmpirical Distribution Function Estimation MethodsStatistics of FitDistributed and Multithreaded ComputationDefining a Severity Distribution Model with the FCMP ProcedurePredefined Utility FunctionsCustom Objective FunctionsInput Data SetsOutput Data SetsDisplayed Output
-
ExamplesDefining a Model for Gaussian DistributionDefining a Model for the Gaussian Distribution with a Scale ParameterDefining a Model for Mixed-Tail DistributionsFitting a Scaled Tweedie Model with RegressorsFitting Distributions to Interval-Censored DataBenefits of Distributed and Multithreaded ComputingEstimating Parameters Using Cramér-von Mises Estimator
- References
PROC HPSEVERITY options ;
The PROC HPSEVERITY statement invokes the procedure. You can specify two types of options in the PROC HPSEVERITY statement. One set of options controls input and output. The other set of options controls the model estimation and selection process.
The following options control the input data sets used by PROC HPSEVERITY and various forms of output generated by PROC HPSEVERITY. The options are listed in alphabetical order:
The following options control the model estimation and selection process:
-
CRITERION=criterion-option
CRITERIA=criterion-option
CRIT=criterion-option -
specifies the model selection criterion.
If two or more models are specified for estimation, then the one with the best value for the selection criterion is chosen as the best model. If the OUTMODELINFO= data set is specified, then the best model’s observation has a value of 1 for the _SELECTED_ variable. You can specify one of the following criterion-options:
- AD
-
specifies the Anderson-Darling (AD) statistic value, which is computed by using the empirical distribution function (EDF) estimate, as the selection criterion. A lower value is deemed better.
- AIC
-
specifies Akaike’s information criterion (AIC) as the selection criterion. A lower value is deemed better.
- AICC
-
specifies the finite-sample corrected Akaike’s information criterion (AICC) as the selection criterion. A lower value is deemed better.
- BIC
-
specifies the Schwarz Bayesian information criterion (BIC) as the selection criterion. A lower value is deemed better.
- CUSTOM
-
specifies the custom objective function as the selection criterion. You can specify this only if you also specify the OBJECTIVE= option. A lower value is deemed better.
- CVM
-
specifies the Cra
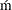
er-von Mises (CvM) statistic value, which is computed by using the empirical distribution function (EDF) estimate, as the selection criterion. A lower value is deemed better.
- KS
-
specifies the Kolmogorov-Smirnov (KS) statistic value, which is computed by using the empirical distribution function (EDF) estimate, as the selection criterion. A lower value is deemed better.
-
LOGLIKELIHOOD
LL -
specifies
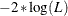 as the selection criterion, where
as the selection criterion, where 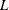 is the likelihood of the data. A lower value is deemed better. This is the default.
is the likelihood of the data. A lower value is deemed better. This is the default.
For more information about these criterion-options, see the section Statistics of Fit.
- EMPIRICALCDF | EDF=method
-
specifies the method to use for computing the nonparametric or empirical estimate of the cumulative distribution function of the data. You can specify one of the following values for method:
- AUTOMATIC | AUTO
-
specifies that the method be chosen automatically based on the data specification.
If you do not specify any censoring or truncation, then the standard empirical estimation method (STANDARD) is chosen. If you specify both right-censoring and left-censoring, then Turnbull’s estimation method (TURNBULL) is chosen. For all other combinations of censoring and truncation, the Kaplan-Meier method (KAPLANMEIER) is chosen.
- KAPLANMEIER | KM
-
specifies that the product limit estimator proposed by Kaplan and Meier (1958) be used. Specification of this method has no effect when both right-censoring and left-censoring are specified.
- MODIFIEDKM | MKM <(options)>
-
specifies that the modified product limit estimator be used. Specification of this method has no effect when both right-censoring and left-censoring are specified.
This method allows Kaplan-Meier’s product limit estimates to be more robust by ignoring the contributions to the estimate due to small risk-set sizes. The risk set is the set of observations at the risk of failing, where an observation is said to fail if it has not been processed yet and might experience censoring or truncation. The minimum risk-set size that makes it eligible to be included in the estimation can be specified either as an absolute lower bound on the size (RSLB= option) or a relative lower bound determined by the formula
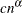 proposed by Lai and Ying (1991). Values of
proposed by Lai and Ying (1991). Values of  and
and  can be specified by using the C= and ALPHA= options, respectively. By default, the relative lower bound is used with values
of
can be specified by using the C= and ALPHA= options, respectively. By default, the relative lower bound is used with values
of 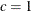 and
and 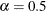 . However, you can modify the default by using the following options:
. However, you can modify the default by using the following options:
- ALPHA | A=number
-
specifies the value to use for
when the lower bound on the risk set size is defined as . This value must satisfy 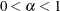 .
.
- C=number
-
specifies the value to use for
when the lower bound on the risk set size is defined as . This value must satisfy 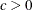 .
.
- RSLB=number
-
specifies the absolute lower bound on the risk set size to be included in the estimate.
- NOTURNBULL
-
specifies that the method be chosen automatically based on the data specification and that Turnbull’s method not be used. This is the default.
This method first replaces each left-censored or interval-censored observation with an uncensored observation. If the resulting set of observations has any truncated or right-censored observations, then the Kaplan-Meier method (KAPLANMEIER) is chosen. Otherwise, the standard empirical estimation method (STANDARD) is chosen. The observations are modified only for the purpose of computing the EDF estimates; the modification does not affect the parameter estimation process.
- STANDARD | STD
-
specifies that the standard empirical estimation method be used. This ignores any censoring or truncation information even if specified, and can thus result in estimates that are more biased than those obtained with other methods more suitable for such data. Specification of this method has no effect when both right-censoring and left-censoring are specified.
- TURNBULL | EM <(options)>
-
specifies that the Turnbull’s method be used. An iterative expectation-maximization (EM) algorithm proposed by Turnbull (1976) is used to compute the empirical estimates. If truncation is also specified, then the modification suggested by Frydman (1994) is used.
This method is used if both right-censoring and left-censoring are specified and if you have explicitly specified the EMPIRICALCDF=TURNBULL option.
You can modify the default behavior of the EM algorithm by using the following options:
For more information about each of the methods, see the section Empirical Distribution Function Estimation Methods.
- OBJECTIVE=symbol-name
-
names the symbol that represents the objective function in the specified SAS programming statements. For each model to be estimated, PROC HPSEVERITY executes the programming statements to compute the value of this symbol for each observation. The values are added across all observations to obtain the value of the objective function. The optimization algorithm estimates the model parameters such that the objective function value is minimized. A separate optimization problem is solved for each candidate distribution.
For more information about writing SAS programming statements to define your own objective function, see the section Custom Objective Functions.