The UNIVARIATE Procedure
- Overview
-
Getting Started

-
Syntax
-
Details
Missing Values Rounding Descriptive Statistics Calculating the Mode Calculating Percentiles Tests for Location Confidence Limits for Parameters of the Normal Distribution Robust Estimators Creating Line Printer Plots Creating High-Resolution Graphics Using the CLASS Statement to Create Comparative Plots Positioning Insets Formulas for Fitted Continuous Distributions Goodness-of-Fit Tests Kernel Density Estimates Construction of Quantile-Quantile and Probability Plots Interpretation of Quantile-Quantile and Probability Plots Distributions for Probability and Q-Q Plots Estimating Shape Parameters Using Q-Q Plots Estimating Location and Scale Parameters Using Q-Q Plots Estimating Percentiles Using Q-Q Plots Input Data Sets OUT= Output Data Set in the OUTPUT Statement OUTHISTOGRAM= Output Data Set OUTKERNEL= Output Data Set OUTTABLE= Output Data Set Tables for Summary Statistics ODS Table Names ODS Tables for Fitted Distributions ODS Graphics Computational Resources
-
Examples
Computing Descriptive Statistics for Multiple Variables Calculating Modes Identifying Extreme Observations and Extreme Values Creating a Frequency Table Creating Plots for Line Printer Output Analyzing a Data Set With a FREQ Variable Saving Summary Statistics in an OUT= Output Data Set Saving Percentiles in an Output Data Set Computing Confidence Limits for the Mean, Standard Deviation, and Variance Computing Confidence Limits for Quantiles and Percentiles Computing Robust Estimates Testing for Location Performing a Sign Test Using Paired Data Creating a Histogram Creating a One-Way Comparative Histogram Creating a Two-Way Comparative Histogram Adding Insets with Descriptive Statistics Binning a Histogram Adding a Normal Curve to a Histogram Adding Fitted Normal Curves to a Comparative Histogram Fitting a Beta Curve Fitting Lognormal, Weibull, and Gamma Curves Computing Kernel Density Estimates Fitting a Three-Parameter Lognormal Curve Annotating a Folded Normal Curve Creating Lognormal Probability Plots Creating a Histogram to Display Lognormal Fit Creating a Normal Quantile Plot Adding a Distribution Reference Line Interpreting a Normal Quantile Plot Estimating Three Parameters from Lognormal Quantile Plots Estimating Percentiles from Lognormal Quantile Plots Estimating Parameters from Lognormal Quantile Plots Comparing Weibull Quantile Plots Creating a Cumulative Distribution Plot Creating a P-P Plot
- References
| Descriptive Statistics |
This section provides computational details for the descriptive statistics that are computed with the PROC UNIVARIATE statement. These statistics can also be saved in the OUT= data set by specifying the keywords listed in Table 4.60 in the OUTPUT statement.
Standard algorithms (Fisher; 1973) are used to compute the moment statistics. The computational methods used by the UNIVARIATE procedure are consistent with those used by other SAS procedures for calculating descriptive statistics.
The following sections give specific details on a number of statistics calculated by the UNIVARIATE procedure.
Mean
The sample mean is calculated as
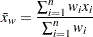 |
where  is the number of nonmissing values for a variable,
is the number of nonmissing values for a variable, 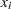 is the
is the 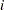 th value of the variable, and
th value of the variable, and 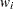 is the weight associated with the th value of the variable. If there is no WEIGHT variable, the formula reduces to
is the weight associated with the th value of the variable. If there is no WEIGHT variable, the formula reduces to
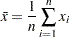 |
Sum
The sum is calculated as 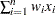 , where is the number of nonmissing values for a variable, is the th value of the variable, and is the weight associated with the th value of the variable. If there is no WEIGHT variable, the formula reduces to
, where is the number of nonmissing values for a variable, is the th value of the variable, and is the weight associated with the th value of the variable. If there is no WEIGHT variable, the formula reduces to 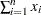 .
.
Sum of the Weights
The sum of the weights is calculated as 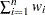 , where is the number of nonmissing values for a variable and is the weight associated with the th value of the variable. If there is no WEIGHT variable, the sum of the weights is .
, where is the number of nonmissing values for a variable and is the weight associated with the th value of the variable. If there is no WEIGHT variable, the sum of the weights is .
Variance
The variance is calculated as
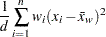 |
where is the number of nonmissing values for a variable, is the th value of the variable, 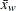 is the weighted mean, is the weight associated with the th value of the variable, and
is the weighted mean, is the weight associated with the th value of the variable, and 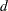 is the divisor controlled by the VARDEF= option in the PROC UNIVARIATE statement:
is the divisor controlled by the VARDEF= option in the PROC UNIVARIATE statement:
 |
If there is no WEIGHT variable, the formula reduces to
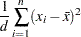 |
Standard Deviation
The standard deviation is calculated as
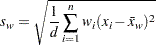 |
where is the number of nonmissing values for a variable, is the th value of the variable, is the weighted mean, is the weight associated with the th value of the variable, and is the divisor controlled by the VARDEF= option in the PROC UNIVARIATE statement. If there is no WEIGHT variable, the formula reduces to
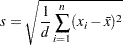 |
Skewness
The sample skewness, which measures the tendency of the deviations to be larger in one direction than in the other, is calculated as follows depending on the VARDEF= option:
VARDEF |
Formula |
|---|---|
DF (default) |
|
N |
|
WDF |
missing |
WEIGHT | WGT |
missing |
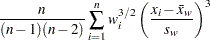
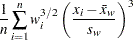
where is the number of nonmissing values for a variable, is the th value of the variable, 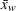 is the sample average,
is the sample average,  is the sample standard deviation, and is the weight associated with the th value of the variable. If VARDEF=DF, then must be greater than 2. If there is no WEIGHT variable, then
is the sample standard deviation, and is the weight associated with the th value of the variable. If VARDEF=DF, then must be greater than 2. If there is no WEIGHT variable, then 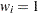 for all
for all 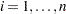 .
.
The sample skewness can be positive or negative; it measures the asymmetry of the data distribution and estimates the theoretical skewness 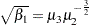 , where
, where 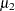 and
and 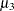 are the second and third central moments. Observations that are normally distributed should have a skewness near zero.
are the second and third central moments. Observations that are normally distributed should have a skewness near zero.
Kurtosis
The sample kurtosis, which measures the heaviness of tails, is calculated as follows depending on the VARDEF= option:
VARDEF |
Formula |
|---|---|
DF (default) |
|
N |
|
WDF |
missing |
WEIGHT | WGT |
missing |
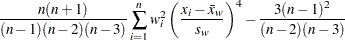
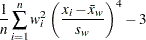
where is the number of nonmissing values for a variable, is the th value of the variable, is the sample average, 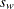 is the sample standard deviation, and is the weight associated with the th value of the variable. If VARDEF=DF, then must be greater than 3. If there is no WEIGHT variable, then for all .
is the sample standard deviation, and is the weight associated with the th value of the variable. If VARDEF=DF, then must be greater than 3. If there is no WEIGHT variable, then for all .
The sample kurtosis measures the heaviness of the tails of the data distribution. It estimates the adjusted theoretical kurtosis denoted as 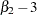 , where
, where 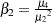 , and
, and 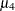 is the fourth central moment. Observations that are normally distributed should have a kurtosis near zero.
is the fourth central moment. Observations that are normally distributed should have a kurtosis near zero.
Coefficient of Variation (CV)
The coefficient of variation is calculated as
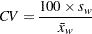 |