The NLMIXED Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsModeling Assumptions and NotationIntegral ApproximationsBuilt-in Log-Likelihood FunctionsHierarchical Model SpecificationOptimization AlgorithmsFinite-Difference Approximations of DerivativesHessian ScalingActive Set MethodsLine-Search MethodsRestricting the Step LengthComputational ProblemsCovariance MatrixPredictionComputational ResourcesDisplayed OutputODS Table Names
-
Examples
- References
Prediction
The nonlinear mixed model is a useful tool for statistical prediction. Assuming a prediction is to be made regarding the ith subject, suppose that  is a differentiable function predicting some quantity of interest. Recall that
is a differentiable function predicting some quantity of interest. Recall that 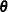 denotes the vector of unknown parameters and
denotes the vector of unknown parameters and 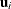 denotes the vector of random effects for the ith subject. A natural point prediction is
denotes the vector of random effects for the ith subject. A natural point prediction is  , where
, where 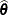 is the maximum likelihood estimate of and
is the maximum likelihood estimate of and 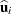 is the empirical Bayes estimate of described previously in the section Integral Approximations.
is the empirical Bayes estimate of described previously in the section Integral Approximations.
An approximate prediction variance matrix for  is
is
![\[ \bP = \left[ \begin{array}{ll} \widehat{\mb{H}}^{-1} & \widehat{\mb{H}}^{-1} \left( \frac{\partial \widehat{\mb{u}}_ i}{\partial \btheta } \right)^\prime \\ \left( \frac{\partial \widehat{\mb{u}}_ i}{\partial \btheta } \right) \widehat{\mb{H}}^{-1} & \widehat{\bGamma }^{-1} + \left( \frac{\partial \widehat{\mb{u}}_ i}{\partial \btheta } \right) \widehat{\mb{H}}^{-1} \left( \frac{\partial \widehat{\mb{u}}_ i}{\partial \btheta } \right)^\prime \end{array} \right] \]](images/statug_nlmixed0316.png)
where  is the approximate Hessian matrix from the optimization for ,
is the approximate Hessian matrix from the optimization for ,  is the approximate Hessian matrix from the optimization for , and
is the approximate Hessian matrix from the optimization for , and  is the derivative of with respect to , evaluated at . The approximate variance matrix for is the standard one discussed in the previous section, and that for is an approximation to the conditional mean squared error of prediction described by Booth and Hobert (1998).
is the derivative of with respect to , evaluated at . The approximate variance matrix for is the standard one discussed in the previous section, and that for is an approximation to the conditional mean squared error of prediction described by Booth and Hobert (1998).
The prediction variance for a general scalar function is defined as the expected squared difference ![$E[f(\widehat{\btheta },\widehat{\mb{u}}_ i) - f(\btheta ,\mb{u}_ i)]^2.$](images/statug_nlmixed0320.png) PROC NLMIXED computes an approximation to it as follows. The derivative of is computed with respect to each element of
PROC NLMIXED computes an approximation to it as follows. The derivative of is computed with respect to each element of  and evaluated at . If
and evaluated at . If 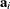 is the resulting vector, then the approximate prediction variance is
is the resulting vector, then the approximate prediction variance is  . This approximation is known as the delta method (Billingsley 1986; Cox 1998).
. This approximation is known as the delta method (Billingsley 1986; Cox 1998).