The UNIVARIATE Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsMissing ValuesRoundingDescriptive StatisticsCalculating the ModeCalculating PercentilesTests for LocationConfidence Limits for Parameters of the Normal DistributionRobust EstimatorsCreating Line Printer PlotsCreating High-Resolution GraphicsUsing the CLASS Statement to Create Comparative PlotsPositioning InsetsFormulas for Fitted Continuous DistributionsGoodness-of-Fit TestsKernel Density EstimatesConstruction of Quantile-Quantile and Probability PlotsInterpretation of Quantile-Quantile and Probability PlotsDistributions for Probability and Q-Q PlotsEstimating Shape Parameters Using Q-Q PlotsEstimating Location and Scale Parameters Using Q-Q PlotsEstimating Percentiles Using Q-Q PlotsInput Data SetsOUT= Output Data Set in the OUTPUT StatementOUTHISTOGRAM= Output Data SetOUTKERNEL= Output Data SetOUTTABLE= Output Data SetTables for Summary StatisticsODS Table NamesODS Tables for Fitted DistributionsODS GraphicsComputational Resources
-
ExamplesComputing Descriptive Statistics for Multiple VariablesCalculating ModesIdentifying Extreme Observations and Extreme ValuesCreating a Frequency TableCreating Basic Summary PlotsAnalyzing a Data Set With a FREQ VariableSaving Summary Statistics in an OUT= Output Data SetSaving Percentiles in an Output Data SetComputing Confidence Limits for the Mean, Standard Deviation, and VarianceComputing Confidence Limits for Quantiles and PercentilesComputing Robust EstimatesTesting for LocationPerforming a Sign Test Using Paired DataCreating a HistogramCreating a One-Way Comparative HistogramCreating a Two-Way Comparative HistogramAdding Insets with Descriptive StatisticsBinning a HistogramAdding a Normal Curve to a HistogramAdding Fitted Normal Curves to a Comparative HistogramFitting a Beta CurveFitting Lognormal, Weibull, and Gamma CurvesComputing Kernel Density EstimatesFitting a Three-Parameter Lognormal CurveAnnotating a Folded Normal CurveCreating Lognormal Probability PlotsCreating a Histogram to Display Lognormal FitCreating a Normal Quantile PlotAdding a Distribution Reference LineInterpreting a Normal Quantile PlotEstimating Three Parameters from Lognormal Quantile PlotsEstimating Percentiles from Lognormal Quantile PlotsEstimating Parameters from Lognormal Quantile PlotsComparing Weibull Quantile PlotsCreating a Cumulative Distribution PlotCreating a P-P Plot
- References
OUTPUT Statement
-
OUTPUT <OUT=SAS-data-set> < keyword1=names …keywordk=names > < percentile-options >;
The OUTPUT statement saves statistics and BY variables in an output data set. When you use a BY statement, each observation in the output data set corresponds to one of the BY groups. Otherwise, the output data set contains only one observation.
You can use any number of OUTPUT statements in the UNIVARIATE procedure. Each OUTPUT statement creates a new data set to contain the statistics specified in that statement. You must use the VAR statement with the OUTPUT statement. The OUTPUT statement must contain a specification of the form keyword=names or the PCTLPTS= and PCTLPRE= options. See Example 4.7 and Example 4.8.
You can use the OUT= option to specify the name of the output data set:
A keyword=names specification selects a statistic to be included in the output data set and gives the names of new variables that contain the statistic. Specify a keyword for each desired statistic, followed by an equal sign, followed by the names of the variables to contain the statistic. In the output data set, the first variable listed after a keyword in the OUTPUT statement contains the statistic for the first variable listed in the VAR statement, the second variable contains the statistic for the second variable in the VAR statement, and so on. If the list of names following the equal sign is shorter than the list of variables in the VAR statement, the procedure uses the names in the order in which the variables are listed in the VAR statement. The available keywords are listed in Table 4.14.
Table 4.14: Statistical Keywords
|
Keyword |
Description |
|---|---|
|
Descriptive Statistic Keywords |
|
|
CSS |
Corrected sum of squares |
|
CV |
Coefficient of variation |
|
GEOMEAN |
Geometric mean |
|
KURTOSIS | KURT |
Kurtosis |
|
MAX |
Largest value |
|
MEAN |
Sample mean |
|
MIN |
Smallest value |
|
MODE |
Most frequent value |
|
N |
Sample size |
|
NMISS |
Number of missing values |
|
NOBS |
Number of observations |
|
RANGE |
Range |
|
SKEWNESS | SKEW |
Skewness |
|
STD | STDDEV |
Standard deviation |
|
STDMEAN | STDERR |
Standard error of the mean |
|
SUM |
Sum of the observations |
|
SUMWGT |
Sum of the weights |
|
USS |
Uncorrected sum of squares |
|
VAR |
Variance |
|
Quantile Statistic Keywords |
|
|
P1 |
1st percentile |
|
P5 |
5th percentile |
|
P10 |
10th percentile |
|
Q1 | P25 |
Lower quartile (25th percentile) |
|
MEDIAN | Q2 | P50 |
Median (50th percentile) |
|
Q3 | P75 |
Upper quartile (75th percentile) |
|
P90 |
90th percentile |
|
P95 |
95th percentile |
|
P99 |
99th percentile |
|
QRANGE |
Interquartile range (Q3–Q1) |
|
Robust Statistic Keywords |
|
|
GINI |
Gini’s mean difference |
|
MAD |
Median absolute difference about the median |
|
QN |
|
|
SN |
|
|
STD_GINI |
Gini’s standard deviation |
|
STD_MAD |
MAD standard deviation |
|
STD_QN |
|
|
STD_QRANGE |
Interquartile range standard deviation |
|
STD_SN |
|
|
Hypothesis Testing Keywords |
|
|
MSIGN |
Sign statistic |
|
NORMALTEST |
Test statistic for normality |
|
SIGNRANK |
Signed rank statistic |
|
PROBM |
Probability of a greater absolute value for the sign statistic |
|
PROBN |
Probability value for the test of normality |
|
PROBS |
Probability value for the signed rank test |
|
PROBT |
Probability value for the Student’s t test |
|
T |
Statistic for the Student’s t test |
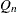
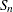
The UNIVARIATE procedure automatically computes the 1st, 5th, 10th, 25th, 50th, 75th, 90th, 95th, and 99th percentiles for the data. These can be saved in an output data set by using keyword=names specifications. You can request additional percentiles by using the PCTLPTS= option. The following percentile-options are related to these additional percentiles:
-
CIPCTLDF=(cipctl-options)
CIQUANTDF=(cipctl-options) -
requests distribution-free confidence limits for percentiles that are requested with the PCTLPTS= option. In other words, no specific parametric distribution such as the normal is assumed for the data. PROC UNIVARIATE uses order statistics (ranks) to compute the confidence limits as described by Hahn and Meeker (1991). This option does not apply if you use a WEIGHT statement. You can specify the following cipctl-options:
-
ALPHA=

-
specifies the level of significance
for 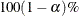 confidence intervals. The value must be between 0 and 1; the default value is 0.05, which results in 95% confidence intervals. The default value is the value
of ALPHA=
given in the PROC statement.
confidence intervals. The value must be between 0 and 1; the default value is 0.05, which results in 95% confidence intervals. The default value is the value
of ALPHA=
given in the PROC statement.
- LOWERPRE=prefixes
-
specifies one or more prefixes that are used to create names for variables that contain the lower confidence limits. To save lower confidence limits for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement.
- LOWERNAME=suffixes
-
specifies one or more suffixes that are used to create names for variables that contain the lower confidence limits. PROC UNIVARIATE creates a variable name by combining the LOWERPRE= value and suffix name. Because the suffixes are associated with the requested percentiles, list the suffixes in the same order as the PCTLPTS= percentiles.
- TYPE=keyword
-
specifies the type of confidence limit, where keyword is LOWER, UPPER, SYMMETRIC, or ASYMMETRIC. The default value is SYMMETRIC.
- UPPERPRE=prefixes
-
specifies one or more prefixes that are used to create names for variables that contain the upper confidence limits. To save upper confidence limits for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement.
- UPPERNAME=suffixes
-
specifies one or more suffixes that are used to create names for variables that contain the upper confidence limits. PROC UNIVARIATE creates a variable name by combining the UPPERPRE= value and suffix name. Because the suffixes are associated with the requested percentiles, list the suffixes in the same order as the PCTLPTS= percentiles.
Note: See the entries for the PCTLPTS= , PCTLPRE= , and PCTLNAME= options for a detailed description of how variable names are created using prefixes, percentile values, and suffixes.
-
ALPHA=
-
CIPCTLNORMAL=(cipctl-options)
CIQUANTNORMAL=(cipctl-options) -
requests confidence limits based on the assumption that the data are normally distributed for percentiles that are requested with the PCTLPTS= option. The computational method is described in Section 4.4.1 of Hahn and Meeker (1991) and uses the noncentral t distribution as given by Odeh and Owen (1980). This option does not apply if you use a WEIGHT statement. You can specify the following cipctl-options:
-
ALPHA=
-
specifies the level of significance
for confidence intervals. The value must be between 0 and 1; the default value is 0.05, which results in 95% confidence intervals. The default value is the value
of ALPHA=
given in the PROC statement.
- LOWERPRE=prefixes
-
specifies one or more prefixes that are used to create names for variables that contain the lower confidence limits. To save lower confidence limits for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement.
- LOWERNAME=suffixes
-
specifies one or more suffixes that are used to create names for variables that contain the lower confidence limits. PROC UNIVARIATE creates a variable name by combining the LOWERPRE= value and suffix name. Because the suffixes are associated with the requested percentiles, list the suffixes in the same order as the PCTLPTS= percentiles.
- TYPE=keyword
-
specifies the type of confidence limit, where keyword is LOWER, UPPER, or TWOSIDED. The default is TWOSIDED.
- UPPERPRE=prefixes
-
specifies one or more prefixes that are used to create names for variables that contain the upper confidence limits. To save upper confidence limits for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement.
- UPPERNAME=suffixes
-
specifies one or more suffixes that are used to create names for variables that contain the upper confidence limits. PROC UNIVARIATE creates a variable name by combining the UPPERPRE= value and suffix name. Because the suffixes are associated with the requested percentiles, list the suffixes in the same order as the PCTLPTS= percentiles.
Note: See the entries for the PCTLPTS= , PCTLPRE= , and PCTLNAME= options for a detailed description of how variable names are created using prefixes, percentile values, and suffixes.
-
ALPHA=
- PCTLGROUP=BYSTAT | BYVAR
-
specifies the order in which variables that you request with the PCTLPTS= option are added to the OUT= data set when the VAR statement lists more than one analysis variable. By default (or if you specify PCTLGROUP=BYSTAT), all variables that are associated with a percentile value are created consecutively. If you specify PCTLGROUP=BYVAR, all variables that are associated with an analysis variable are created consecutively.
Consider the following statements:
proc univariate data=Score; var PreTest PostTest; output out=ByStat pctlpts=20 40 pctlpre=Pre_ Post_; output out=ByVar pctlgroup=byvar pctlpts=20 40 pctlpre=Pre_ Post_; run;
The order of variables in the data set
ByStatisPre_20,Post_20,Pre_40,Post_40. The order of variables in the data setByVarisPre_20,Pre_40,Post_20,Post_40. - PCTLNAME=suffixes
-
specifies one or more suffixes to create the names for the variables that contain the PCTLPTS= percentiles. PROC UNIVARIATE creates a variable name by combining the PCTLPRE= value and suffix name. Because the suffix names are associated with the percentiles that are requested, list the suffix names in the same order as the PCTLPTS= percentiles. If you specify n suffixes with the PCTLNAME= option and m percentile values with the PCTLPTS= option where
 , the suffixes are used to name the first n percentiles and the default names are used for the remaining
, the suffixes are used to name the first n percentiles and the default names are used for the remaining  percentiles. For example, consider the following statements:
percentiles. For example, consider the following statements:
proc univariate; var Length Width Height; output pctlpts = 20 40 pctlpre = pl pw ph pctlname = twenty; run;The value twenty in the PCTLNAME= option is used for only the first percentile in the PCTLPTS= list. This suffix is appended to the values in the PCTLPRE= option to generate the new variable names
pltwenty,pwtwenty, andphtwenty, which contain the 20th percentiles forLength,Width, andHeight, respectively. Because a second PCTLNAME= suffix is not specified, variable names for the 40th percentiles forLength,Width, andHeightare generated using the prefixes and percentile values. Thus, the output data set contains the variablespltwenty,pl40,pwtwenty,pw40,phtwenty, andph40.You must specify PCTLPRE= to supply prefix names for the variables that contain the PCTLPTS= percentiles.
If the number of PCTLNAME= values is fewer than the number of percentiles or if you omit PCTLNAME=, PROC UNIVARIATE uses the percentile as the suffix to create the name of the variable that contains the percentile. For an integer percentile, PROC UNIVARIATE uses the percentile. Otherwise, PROC UNIVARIATE truncates decimal values of percentiles to two decimal places and replaces the decimal point with an underscore.
If either the prefix and suffix name combination or the prefix and percentile name combination is longer than 32 characters, PROC UNIVARIATE truncates the prefix name so that the variable name is 32 characters.
- PCTLNDEC=value
-
specifies the number of decimal places in percentile values that are incorporated into percentile variable names. The default value is 2. For example, the following statements create two output data sets, each containing one percentile variable. The variable in data set
shortis namedpwid85_12, while the one in data setlongis namedpwid85_125.proc univariate; var width; output out=short pctlpts=85.125 pctlpre=pwid; output out=long pctlpts=85.125 pctlpre=pwid pctlndec=3; run;
- PCTLPRE=prefixes
-
specifies one or more prefixes to create the variable names for the variables that contain the PCTLPTS= percentiles. To save the same percentiles for more than one analysis variable, specify a list of prefixes. The order of the prefixes corresponds to the order of the analysis variables in the VAR statement. The PCTLPRE= and PCTLPTS= options must be used together.
The procedure generates new variable names by using the prefix and the percentile values. If the specified percentile is an integer, the variable name is simply the prefix followed by the value. If the specified value is not an integer, an underscore replaces the decimal point in the variable name, and decimal values are truncated to one decimal place. For example, the following statements create the variables
pwid20,pwid33_3,pwid66_6, andpwid80for the 20th, 33.33rd, 66.67th, and 80th percentiles ofWidth, respectively:proc univariate noprint; var Width; output pctlpts=20 33.33 66.67 80 pctlpre=pwid; run;
If you request percentiles for more than one variable, you should list prefixes in the same order in which the variables appear in the VAR statement. If combining the prefix and percentile value results in a name longer than 32 characters, the prefix is truncated so that the variable name is 32 characters.
- PCTLPTS=percentiles
-
specifies one or more percentiles that are not automatically computed by the UNIVARIATE procedure. The PCTLPRE= and PCTLPTS= options must be used together. You can specify percentiles with an expression of the form start TO stop BY increment where start is a starting number, stop is an ending number, and increment is a number to increment by. The PCTLPTS= option generates additional percentiles and outputs them to a data set. These additional percentiles are not printed.
To compute the 50th, 95th, 97.5th, and 100th percentiles, submit the statement
output pctlpre=P_ pctlpts=50,95 to 100 by 2.5;
PROC UNIVARIATE computes the requested percentiles based on the method that you specify with the PCTLDEF= option in the PROC UNIVARIATE statement. You must use PCTLPRE=, and optionally PCTLNAME= , to specify variable names for the percentiles. For example, the following statements create an output data set named
Pctlsthat contains the 20th and 40th percentiles of the analysis variablesPreTestandPostTest:proc univariate data=Score; var PreTest PostTest; output out=Pctls pctlpts=20 40 pctlpre=PreTest_ PostTest_ pctlname=P20 P40; run;PROC UNIVARIATE saves the 20th and 40th percentiles for
PreTestandPostTestin the variablesPreTest_P20,PostTest_P20,PreTest_P40, andPostTest_P40.