The UNIVARIATE Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsMissing ValuesRoundingDescriptive StatisticsCalculating the ModeCalculating PercentilesTests for LocationConfidence Limits for Parameters of the Normal DistributionRobust EstimatorsCreating Line Printer PlotsCreating High-Resolution GraphicsUsing the CLASS Statement to Create Comparative PlotsPositioning InsetsFormulas for Fitted Continuous DistributionsGoodness-of-Fit TestsKernel Density EstimatesConstruction of Quantile-Quantile and Probability PlotsInterpretation of Quantile-Quantile and Probability PlotsDistributions for Probability and Q-Q PlotsEstimating Shape Parameters Using Q-Q PlotsEstimating Location and Scale Parameters Using Q-Q PlotsEstimating Percentiles Using Q-Q PlotsInput Data SetsOUT= Output Data Set in the OUTPUT StatementOUTHISTOGRAM= Output Data SetOUTKERNEL= Output Data SetOUTTABLE= Output Data SetTables for Summary StatisticsODS Table NamesODS Tables for Fitted DistributionsODS GraphicsComputational Resources
-
ExamplesComputing Descriptive Statistics for Multiple VariablesCalculating ModesIdentifying Extreme Observations and Extreme ValuesCreating a Frequency TableCreating Plots for Line Printer OutputAnalyzing a Data Set With a FREQ VariableSaving Summary Statistics in an OUT= Output Data SetSaving Percentiles in an Output Data SetComputing Confidence Limits for the Mean, Standard Deviation, and VarianceComputing Confidence Limits for Quantiles and PercentilesComputing Robust EstimatesTesting for LocationPerforming a Sign Test Using Paired DataCreating a HistogramCreating a One-Way Comparative HistogramCreating a Two-Way Comparative HistogramAdding Insets with Descriptive StatisticsBinning a HistogramAdding a Normal Curve to a HistogramAdding Fitted Normal Curves to a Comparative HistogramFitting a Beta CurveFitting Lognormal, Weibull, and Gamma CurvesComputing Kernel Density EstimatesFitting a Three-Parameter Lognormal CurveAnnotating a Folded Normal CurveCreating Lognormal Probability PlotsCreating a Histogram to Display Lognormal FitCreating a Normal Quantile PlotAdding a Distribution Reference LineInterpreting a Normal Quantile PlotEstimating Three Parameters from Lognormal Quantile PlotsEstimating Percentiles from Lognormal Quantile PlotsEstimating Parameters from Lognormal Quantile PlotsComparing Weibull Quantile PlotsCreating a Cumulative Distribution PlotCreating a P-P Plot
- References
PPPLOT <variables> < / options> ;
The PPPLOT statement creates a probability-probability plot (also referred to as a P-P plot or percent plot), which compares the empirical cumulative distribution function (ecdf) of a variable with a specified theoretical cumulative distribution function such as the normal. If the two distributions match, the points on the plot form a linear pattern that passes through the origin and has unit slope. Thus, you can use a P-P plot to determine how well a theoretical distribution models a set of measurements.
You can specify one of the following theoretical distributions with the PPPLOT statement:
-
beta
-
exponential
-
gamma
-
Gumbel
-
generalized Pareto
-
inverse Gaussian
-
lognormal
-
normal
-
power function
-
Rayleigh
-
Weibull
Note: Probability-probability plots should not be confused with probability plots, which compare a set of ordered measurements with percentiles from a specified distribution. You can create probability plots with the PROBPLOT statement.
You can use any number of PPPLOT statements in the UNIVARIATE procedure. The components of the PPPLOT statement are as follows.
Table 4.15 summarizes the options for requesting a specific theoretical distribution.
Table 4.15: Options for Specifying the Theoretical Distribution
|
Option |
Description |
|---|---|
|
specifies beta P-P plot |
|
|
specifies exponential P-P plot |
|
|
specifies gamma P-P plot |
|
|
specifies Gumbel P-P plot |
|
|
specifies generalized Pareto P-P plot |
|
|
specifies inverse Gaussian P-P plot |
|
|
specifies lognormal P-P plot |
|
|
specifies normal P-P plot |
|
|
specifies power function P-P plot |
|
|
specifies Rayleigh P-P plot |
|
|
specifies Weibull P-P plot |
Table 4.16 summarizes options that specify distribution parameters and control the display of the diagonal distribution reference line. Specify these options in parentheses after the distribution option. For example, the following statements use the NORMAL option to request a normal P-P plot:
proc univariate data=measures; ppplot length / normal(mu=10 sigma=0.3 color=red); run;
The MU= and SIGMA= normal-options specify ![]() and
and ![]() for the normal distribution, and the COLOR= normal-option specifies the color for the line.
for the normal distribution, and the COLOR= normal-option specifies the color for the line.
Table 4.16: Secondary Distribution Reference Line Options
|
Option |
Description |
|---|---|
|
Options Used with All Distributions |
|
|
specifies color of distribution reference line |
|
|
specifies line type of distribution reference line |
|
|
suppresses the distribution reference line |
|
|
specifies width of distribution reference line |
|
|
Beta-Options |
|
|
specifies shape parameter |
|
|
specifies shape parameter |
|
|
specifies scale parameter |
|
|
specifies lower threshold parameter |
|
|
Exponential-Options |
|
|
specifies scale parameter |
|
|
specifies threshold parameter |
|
|
Gamma-Options |
|
|
specifies shape parameter |
|
|
specifies change in successive estimates of |
|
|
specifies initial value for |
|
|
specifies maximum number of iterations in the Newton-Raphson approximation of |
|
|
specifies scale parameter |
|
|
specifies threshold parameter |
|
|
Gumbel-Options |
|
|
specifies location parameter |
|
|
specifies scale parameter |
|
|
IGauss-Options |
|
|
specifies shape parameter |
|
|
specifies mean |
|
|
Lognormal-Options |
|
|
specifies shape parameter |
|
|
specifies threshold parameter |
|
|
specifies scale parameter |
|
|
Normal-Options |
|
|
specifies mean |
|
|
specifies standard deviation |
|
|
Pareto-Options |
|
|
specifies shape parameter |
|
|
specifies scale parameter |
|
|
specifies threshold parameter |
|
|
Power-Options |
|
|
specifies shape parameter |
|
|
specifies scale parameter |
|
|
specifies threshold parameter |
|
|
Rayleigh-Options |
|
|
specifies scale parameter |
|
|
specifies threshold parameter |
|
|
Weibull-Options |
|
|
specifies shape parameter |
|
|
requests table of iteration history and optimizer details |
|
|
specifies maximum number of iterations in the Newton-Raphson approximation of |
|
|
specifies scale parameter |
|
|
specifies threshold parameter |
|
Table 4.17 lists options that control the appearance of the plots. For complete descriptions, see the sections Dictionary of Options and Dictionary of Common Options.
Table 4.17: General Graphics Options
|
Option |
Description |
|---|---|
|
General Graphics Options |
|
|
specifies reference lines perpendicular to the horizontal axis |
|
|
specifies line labels for HREF= lines |
|
|
specifies position for HREF= line labels |
|
|
suppresses label for horizontal axis |
|
|
suppresses label for vertical axis |
|
|
suppresses tick marks and tick mark labels for vertical axis |
|
|
displays P-P plot in square format |
|
|
specifies label for vertical axis |
|
|
specifies reference lines perpendicular to the vertical axis |
|
|
specifies line labels for VREF= lines |
|
|
specifies position for VREF= line labels |
|
|
Options for Traditional Graphics Output |
|
|
provides an annotate data set |
|
|
specifies color for axis |
|
|
specifies color for frame |
|
|
specifies colors for HREF= lines |
|
|
specifies color for text |
|
|
specifies colors for VREF= lines |
|
|
specifies description for plot in graphics catalog |
|
|
specifies software font for text |
|
|
specifies AXIS statement for horizontal axis |
|
|
specifies height of text used outside framed areas |
|
|
specifies number of minor tick marks on horizontal axis |
|
|
specifies software font for text inside framed areas |
|
|
specifies height of text inside framed areas |
|
|
specifies line types for HREF= lines |
|
|
specifies line types for VREF= lines |
|
|
specifies name for plot in graphics catalog |
|
|
suppresses frame around plotting area |
|
|
turns and vertically strings out characters in labels for vertical axis |
|
|
specifies AXIS statement for vertical axis |
|
|
specifies number of minor tick marks on vertical axis |
|
|
specifies line thickness for axes and frame |
|
|
Options for ODS Graphics Output |
|
|
specifies footnote displayed on plot |
|
|
specifies secondary footnote displayed on plot |
|
|
specifies title displayed on plot |
|
|
specifies secondary title displayed on plot |
|
|
overlays plots for different class levels (ODS Graphics only) |
|
|
Options for Comparative Plots |
|
|
applies annotation requested in ANNOTATE= data set to key cell only |
|
|
specifies color for filling row label frames |
|
|
specifies color for filling column label frames |
|
|
specifies color for proportion of frequency bar |
|
|
specifies color for row labels |
|
|
specifies color for column labels |
|
|
specifies distance between tiles in comparative plot |
|
|
specifies number of columns in comparative plot |
|
|
specifies number of rows in comparative plot |
|
|
Miscellaneous Options |
|
|
specifies table of contents entry for P-P plot grouping |
|
The following entries provide detailed descriptions of options for the PPPLOT statement. See the section Dictionary of Common Options for detailed descriptions of options common to all plot statements.
- ALPHA=value
-
specifies the shape parameter

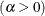 for P-P plots requested with the BETA, GAMMA, PARETO and POWER options.
for P-P plots requested with the BETA, GAMMA, PARETO and POWER options.
- BETA<(beta-options)>
-
creates a beta P-P plot. To create the plot, the
 nonmissing observations are ordered from smallest to largest:
nonmissing observations are ordered from smallest to largest:
![\[ x_{(1)} \leq x_{(2)} \leq \cdots \leq x_{(n)} \]](images/procstat_univariate0099.png)
The
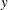 -coordinate of the
-coordinate of the 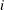 th point is the empirical cdf value
th point is the empirical cdf value 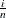 . The
. The  -coordinate is the theoretical beta cdf value
-coordinate is the theoretical beta cdf value ![\[ B_{\alpha \beta }\left(\frac{x_{(i)}-\theta }{\sigma }\right) = \int _{\theta }^{x_{(i)}} \frac{(t-\theta )^{\alpha -1}(\theta +\sigma -t)^{\beta -1} }{B(\alpha ,\beta ) \sigma ^{(\alpha +\beta -1)} } dt \]](images/procstat_univariate0102.png)
where
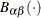 is the normalized incomplete beta function,
is the normalized incomplete beta function, 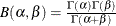 , and
, and
-
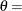 lower threshold parameter
lower threshold parameter
-
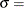 scale parameter
scale parameter 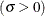
-
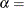 first shape parameter
first shape parameter
-
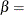 second shape parameter
second shape parameter 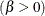
You can specify
, 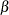 ,
,  , and
, and 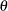 with the ALPHA=, BETA=, SIGMA=, and THETA= beta-options, as illustrated in the following example:
with the ALPHA=, BETA=, SIGMA=, and THETA= beta-options, as illustrated in the following example:
proc univariate data=measures; ppplot width / beta(theta=1 sigma=2 alpha=3 beta=4); run;
If you do not specify values for these parameters, then by default,
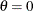 ,
, 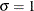 , and maximum likelihood estimates are calculated for and .
, and maximum likelihood estimates are calculated for and .
IMPORTANT: If the default unit interval (0,1) does not adequately describe the range of your data, then you should specify THETA=
and SIGMA= so that your data fall in the interval 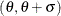 .
.
If the data are beta distributed with parameters
, , , and , then the points on the plot for ALPHA=, BETA=, SIGMA=, and THETA= tend to fall on or near the diagonal line 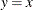 , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
beta distribution is a good fit. You can specify the SCALE= option as an alias for the SIGMA= option and the THRESHOLD= option
as an alias for the THETA= option.
, which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
beta distribution is a good fit. You can specify the SCALE= option as an alias for the SIGMA= option and the THRESHOLD= option
as an alias for the THETA= option.
-
- BETA=value
-
specifies the shape parameter
for P-P plots requested with the BETA distribution option. See the preceding entry for the BETA distribution option for an
example.
- C=value
-
specifies the shape parameter

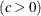 for P-P plots requested with the WEIBULL option. See the entry for the WEIBULL option for examples.
for P-P plots requested with the WEIBULL option. See the entry for the WEIBULL option for examples.
-
EXPONENTIAL<(exponential-options)>
EXP<(exponential-options)> -
creates an exponential P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical exponential cdf value
![\[ F(x_{(i)}) = 1-\exp \left(-\frac{x_{(i)}-\theta }{\sigma }\right) \]](images/procstat_univariate0114.png)
where
-
threshold parameter
-
scale parameter
You can specify
and with the SIGMA= and THETA= exponential-options, as illustrated in the following example:
proc univariate data=measures; ppplot width / exponential(theta=1 sigma=2); run;
If you do not specify values for these parameters, then by default,
and a maximum likelihood estimate is calculated for .
IMPORTANT: Your data must be greater than or equal to the lower threshold
. If the default is not an adequate lower bound for your data, specify with the THETA= option.
If the data are exponentially distributed with parameters
and , the points on the plot for SIGMA= and THETA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified exponential distribution is a good
fit. You can specify the SCALE= option as an alias for the SIGMA= option and the THRESHOLD= option as an alias for the THETA=
option.
-
- GAMMA<(gamma-options)>
-
creates a gamma P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical gamma cdf value ![\[ G_{\alpha }\left(\frac{x_{(i)}-\theta }{\sigma }\right) = \int _{\theta }^{x_{(i)}} \frac{1}{\sigma \Gamma (\alpha )} \left(\frac{t-\theta }{\sigma }\right)^{\alpha -1} \exp \left(-\frac{t-\theta }{\sigma }\right) dt \]](images/procstat_univariate0115.png)
where
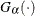 is the normalized incomplete gamma function and
is the normalized incomplete gamma function and
-
threshold parameter
-
scale parameter
-
shape parameter
You can specify
, , and with the ALPHA=, SIGMA=, and THETA= gamma-options, as illustrated in the following example:
proc univariate data=measures; ppplot width / gamma(alpha=1 sigma=2 theta=3); run;
If you do not specify values for these parameters, then by default,
and maximum likelihood estimates are calculated for and .
IMPORTANT: Your data must be greater than or equal to the lower threshold
. If the default is not an adequate lower bound for your data, specify with the THETA= option.
If the data are gamma distributed with parameters
, , and , the points on the plot for ALPHA=, SIGMA=, and THETA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
gamma distribution is a good fit. You can specify the SHAPE= option as an alias for the ALPHA= option, the SCALE= option as
an alias for the SIGMA= option, and the THRESHOLD= option as an alias for the THETA= option.
-
- GUMBEL<(Gumbel-options)>
-
creates a Gumbel P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical Gumbel cdf value ![\[ F\left(x_{(i)}\right) = \exp (-e^{-(x_{(i)}-\mu )/\sigma }) \]](images/procstat_univariate0117.png)
where
-
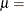 location parameter
location parameter
-
scale parameter
You can specify
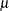 and with the MU= and SIGMA= Gumbel-options, as illustrated in the following example:
and with the MU= and SIGMA= Gumbel-options, as illustrated in the following example:
proc univariate data=measures; ppplot width / gumbel(mu=1 sigma=2); run;
If you do not specify values for these parameters, then by default, the maximum likelihood estimates are calculated for
and .
If the data are Gumbel distributed with parameters
and , the points on the plot for MU= and SIGMA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
Gumbel distribution is a good fit.
-
- IGAUSS<(iGauss-options)>
-
creates an inverse Gaussian P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical inverse Gaussian cdf value ![\[ F(x_{(i)}) = \Phi \left\{ \sqrt {\frac{\lambda }{x_{(i)}}} \left( \frac{x_{(i)}}{\mu }-1\right) \right\} + e^{2\lambda /\mu } \Phi \left\{ -\sqrt {\frac{\lambda }{x_{(i)}}} \left( \frac{x_{(i)}}{\mu }+1\right) \right\} \]](images/procstat_univariate0119.png)
where
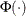 is the standard normal distribution function and
is the standard normal distribution function and
-
mean parameter
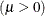
-
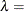 shape parameter
shape parameter 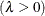
You can specify
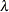 and with the LAMBDA= and MU= IGauss-options, as illustrated in the following example:
and with the LAMBDA= and MU= IGauss-options, as illustrated in the following example:
proc univariate data=measures; ppplot width / igauss(lambda=1 mu=2); run;
If you do not specify values for these parameters, then by default, the maximum likelihood estimates are calculated for
and .
If the data are inverse Gaussian distributed with parameters
and , the points on the plot for LAMBDA= and MU= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
inverse Gaussian distribution is a good fit.
-
- LAMBDA=value
-
specifies the shape parameter
for fitted curves requested with the IGAUSS option. Enclose the LAMBDA= option in parentheses after the IGAUSS distribution
keyword. If you do not specify a value for , the procedure calculates a maximum likelihood estimate.
-
LOGNORMAL<(lognormal-options)>
LNORM<(lognormal-options)> -
creates a lognormal P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical lognormal cdf value
![\[ \Phi \left(\frac{\log (x_{(i)}-\theta )-\zeta }{\sigma }\right) \]](images/procstat_univariate0122.png)
where
is the cumulative standard normal distribution function and
-
threshold parameter
-
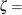 scale parameter
scale parameter
-
shape parameter
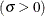
You can specify
, 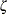 , and with the THETA=, ZETA=, and SIGMA= lognormal-options, as illustrated in the following example:
, and with the THETA=, ZETA=, and SIGMA= lognormal-options, as illustrated in the following example:
proc univariate data=measures; ppplot width / lognormal(theta=1 zeta=2); run;
If you do not specify values for these parameters, then by default,
and maximum likelihood estimates are calculated for and .
IMPORTANT: Your data must be greater than the lower threshold
. If the default is not an adequate lower bound for your data, specify with the THETA= option.
If the data are lognormally distributed with parameters
, , and , the points on the plot for SIGMA=, THETA=, and ZETA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
lognormal distribution is a good fit. You can specify the SHAPE= option as an alias for the SIGMA=option, the SCALE= option
as an alias for the ZETA= option, and the THRESHOLD= option as an alias for the THETA= option.
-
- MU=value
-
specifies the parameter
for P-P plots requested with the GUMBEL, IGAUSS, and NORMAL options. By default, the sample mean is used for with inverse Gaussian and normal distributions. A maximum likelihood estimate is computed by default with the Gumbel distribution.
See Example 4.36.
- NOLINE
-
NORMAL<(normal-options )>
NORM<(normal-options )> -
creates a normal P-P plot. By default, if you do not specify a distribution option, the procedure displays a normal P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical normal cdf value ![\[ \Phi \left(\frac{x_{(i)}-\mu }{\sigma }\right) = \int _{-\infty }^{x_{(i)}} \frac{1}{\sigma \sqrt {2 \pi } } \exp \left( -\frac{(t - \mu )^2}{2 \sigma ^{2}} \right) dt \]](images/procstat_univariate0124.png)
where
is the cumulative standard normal distribution function and
-
location parameter or mean
-
scale parameter or standard deviation
You can specify
and with the MU= and SIGMA= normal-options, as illustrated in the following example:
proc univariate data=measures; ppplot width / normal(mu=1 sigma=2); run;
By default, the sample mean and sample standard deviation are used for
and .
If the data are normally distributed with parameters
and , the points on the plot for MU= and SIGMA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
normal distribution is a good fit. See Example 4.36.
-
- PARETO<(Pareto-options)>
-
creates a generalized Pareto P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical generalized Pareto cdf value
![\[ F(x_{(i)}) = 1 - { \left( 1 - \frac{\alpha (x_{(i)} - \theta )}{\sigma } \right) }^\frac {1}{\alpha } \]](images/procstat_univariate0125.png)
where
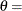 threshold parameter
threshold parameter 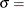 scale parameter
scale parameter 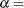 shape parameter
shape parameter
The parameter
for the generalized Pareto distribution must be less than the minimum data value. You can specify with the THETA= Pareto-option. The default value for is 0. In addition, the generalized Pareto distribution has a shape parameter and a scale parameter . You can specify these parameters with the ALPHA= and SIGMA= Pareto-options. By default, maximum likelihood estimates are computed for and .
If the data are generalized Pareto distributed with parameters
, , and , the points on the plot for THETA=, SIGMA=, and ALPHA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
generalized Pareto distribution is a good fit.
- POWER<(Power-options)>
-
creates a power function P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical power function cdf value
![\[ F(x_{(i)}) = {\left( \frac{x_{(i)} - \theta }{\sigma } \right)}^{\alpha } \]](images/procstat_univariate0126.png)
where
lower threshold parameter (lower endpoint) scale parameter shape parameter 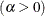
The power function distribution is bounded below by the parameter
and above by the value 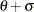 . You can specify and by using the THETA= and SIGMA= power-options. The default values for and are 0 and 1, respectively.
. You can specify and by using the THETA= and SIGMA= power-options. The default values for and are 0 and 1, respectively.
You can specify a value for the shape parameter,
, with the ALPHA= power-option. If you do not specify a value for , the procedure calculates a maximum likelihood estimate.
The power function distribution is a special case of the beta distribution with its second shape parameter,
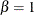 .
.
If the data are power function distributed with parameters
, , and , the points on the plot for THETA=, SIGMA=, and ALPHA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
power function distribution is a good fit.
- RAYLEIGH<(Rayleigh-options)>
-
creates a Rayleigh P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical Rayleigh cdf value
![\[ F(x_{(i)}) = 1 - e^{-(x_{(i)} - \theta )^2/(2\sigma ^2)} \]](images/procstat_univariate0127.png)
where
threshold parameter scale parameter
The parameter
for the Rayleigh distribution must be less than the minimum data value. You can specify with the THETA= Rayleigh-option. The default value for is 0. You can specify with the SIGMA= Rayleigh-option. By default, a maximum likelihood estimate is computed for .
If the data are Rayleigh distributed with parameters
and , the points on the plot for THETA= and SIGMA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
Rayleigh distribution is a good fit.
- SIGMA=value
-
specifies the parameter
, where 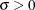 . When used with the BETA, EXPONENTIAL, GAMMA, GUMBEL, NORMAL, PARETO, POWER, RAYLEIGH, and WEIBULL options, the SIGMA= option
specifies the scale parameter. When used with the LOGNORMAL option, the SIGMA= option specifies the shape parameter. See Example 4.36.
. When used with the BETA, EXPONENTIAL, GAMMA, GUMBEL, NORMAL, PARETO, POWER, RAYLEIGH, and WEIBULL options, the SIGMA= option
specifies the scale parameter. When used with the LOGNORMAL option, the SIGMA= option specifies the shape parameter. See Example 4.36.
- SQUARE
-
displays the P-P plot in a square frame. The default is a rectangular frame. See Example 4.36.
-
THETA=value
THRESHOLD=value -
specifies the lower threshold parameter
for plots requested with the BETA, EXPONENTIAL, GAMMA, LOGNORMAL, PARETO, POWER, RAYLEIGH, and WEIBULL options.
-
WEIBULL<(Weibull-options)>
WEIB<(Weibull-options)> -
creates a Weibull P-P plot. To create the plot, the
nonmissing observations are ordered from smallest to largest:
The
-coordinate of the th point is the empirical cdf value . The -coordinate is the theoretical Weibull cdf value
![\[ F(x_{(i)}) = 1-\exp \left( -\left( \frac{x_{(i)}-\theta }{\sigma } \right)^{c} \right) \]](images/procstat_univariate0129.png)
where
-
threshold parameter
-
scale parameter
-
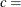 shape parameter
shape parameter 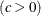
You can specify
, , and with the C=, SIGMA=, and THETA= Weibull-options, as illustrated in the following example:
proc univariate data=measures; ppplot width / weibull(theta=1 sigma=2); run;
If you do not specify values for these parameters, then by default
and maximum likelihood estimates are calculated for and .
IMPORTANT: Your data must be greater than or equal to the lower threshold
. If the default is not an adequate lower bound for your data, you should specify with the THETA= option.
If the data are Weibull distributed with parameters
, , and , the points on the plot for C=, SIGMA=, and THETA= tend to fall on or near the diagonal line , which is displayed by default. Agreement between the diagonal line and the point pattern is evidence that the specified
Weibull distribution is a good fit. You can specify the SHAPE= option as an alias for the C= option, the SCALE= option as
an alias for the SIGMA= option, and the THRESHOLD= option as an alias for the THETA= option.
-
- ZETA=value
-
specifies a value for the scale parameter
for lognormal P-P plots requested with the LOGNORMAL option.