The QLIM Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsOrdinal Discrete Choice ModelingLimited Dependent Variable ModelsStochastic Frontier Production and Cost ModelsHeteroscedasticity and Box-Cox TransformationBivariate Limited Dependent Variable ModelingSelection ModelsMultivariate Limited Dependent ModelsVariable SelectionTests on ParametersEndogeneity and Instrumental VariablesPanel Data AnalysisBayesian AnalysisPrior DistributionsAutomated MCMCMarginal LikelihoodStandard DistributionsOutput to SAS Data SetOUTEST= Data SetNamingODS Table NamesODS Graphics
-
Examples
- References
RANDOM Statement
-
RANDOM INTERCEPT < / options> ;
The RANDOM statement defines the random effects in the mixed model. Currently, you can specify only random intercepts as random effects; random coefficients are not allowed. If you have a panel data set, you can use the RANDOM statement to estimate random-effects models that include binomial probit, binomial logit, ordinal probit, ordinal logit, linear regression, Tobit, truncated regression, and stochastic frontier models.
You can specify only a single RANDOM statement, and if you specify a RANDOM statement, you can specify only one MODEL statement. The RANDOM statement is not supported if a BAYES statement is also specified.
You can abbreviate INTERCEPT as INT. You can specify the following options after a slash (/).
-
SUBJECT=variable
S=variable -
determines the unique realizations of the random effects. In panel data, the variable identifies the cross-sectional units. For example, in panel data, variable might be household or country.
If you do not specify the SUBJECT= option, then variable is assumed to have a single realization; that is, there is no variation in the random effects. You should specify this option in order to have a true random-effects model.
The following statement illustrates the SUBJECT= option:
random int / subject=id; -
METHOD=method-options
M=method-options -
specifies the method of approximation to the integral that appears in the likelihood function. For more information about the integral and the integration methods, see the section Random-Effects Models for Panel Data and its subsections.
You can specify the following method-options:
-
HALTON < (halton-options)>
HALT < (halton-options)>
QMC < (halton-options)> -
requests a quasi–Monte Carlo integration method that uses the Halton sequence that is defined by the prime number 2. For information about how this series is generated, see the section QMC Method Using the Halton Sequence.
You can specify the following halton-options:
The following statement requests a Halton sequence that has 100 elements and does not discard any elements:
random int / subject=country method=halton(hdraw=100 haltonstart=1); -
HERMITE < ( QPOINTS=value ) >
HERM < ( QPOINTS=value ) >
GAUSS < ( QPOINTS=value ) > -
requests the Gauss-Hermite quadrature integration method. For more information, see the section Approximation by Hermite Quadrature.
QPOINTS=value specifies the number of quadrature points to be used during evaluation of integral. By default QPOINTS=20.
The following statement illustrates this option:
random int / subject=states method=hermite(qpoints=4); -
SIMULATION < (simulation-options) >
SIM < (simulation-options) > -
requests simulation as the method of integration. For more information, see the section Simulated Maximum Likelihood.
You can specify the following simulation-options:
- NDRAW=value
-
specifies the number of draws for the simulation. You can also specify the number of draws in the NDRAW= option in the PROC QLIM statement. If you specify both, PROC QLIM uses the value in the RANDOM statement. If you do not specify any NDRAW= option, the default value is set to
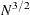 , where N is the number of unique values of the subject variable. For example, for a panel data set, N is the number of cross-sections.
, where N is the number of unique values of the subject variable. For example, for a panel data set, N is the number of cross-sections.
- SEED=value
-
specifies the seed of the random draws, where value must be less than
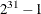 . You can also specify the seed in the SEED= option in the PROC QLIM statement. If you specify both, PROC QLIM uses the value in the RANDOM statement. If you do not specify a seed, or if you specify a value less than equal to zero, the seed is generated
randomly.
. You can also specify the seed in the SEED= option in the PROC QLIM statement. If you specify both, PROC QLIM uses the value in the RANDOM statement. If you do not specify a seed, or if you specify a value less than equal to zero, the seed is generated
randomly.
The following statement illustrates this option:
random int / subject=id method=simulation(ndraw=1000 seed=12345);
By default, METHOD=HERMITE(QPOINTS=20).
-
HALTON < (halton-options)>