The QLIM Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsOrdinal Discrete Choice ModelingLimited Dependent Variable ModelsStochastic Frontier Production and Cost ModelsHeteroscedasticity and Box-Cox TransformationBivariate Limited Dependent Variable ModelingSelection ModelsMultivariate Limited Dependent ModelsVariable SelectionTests on ParametersEndogeneity and Instrumental VariablesPanel Data AnalysisBayesian AnalysisPrior DistributionsAutomated MCMCMarginal LikelihoodStandard DistributionsOutput to SAS Data SetOUTEST= Data SetNamingODS Table NamesODS Graphics
-
Examples
- References
Ordinal Discrete Choice Modeling
Binary Probit and Logit Model
The binary choice model is
![\[ y^{*}_{i} = \mathbf{x}_{i}’\bbeta + \epsilon _{i} \]](images/etsug_qlim0051.png)
where value of the latent dependent variable, 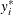 , is observed only as follows:
, is observed only as follows:
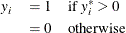
The disturbance, 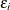 , of the probit model has standard normal distribution with the distribution function (CDF)
, of the probit model has standard normal distribution with the distribution function (CDF)
![\[ \Phi (x)=\int _{-\infty }^{x}\frac{1}{\sqrt {2\pi }}\exp (-t^2/2)dt \]](images/etsug_qlim0055.png)
The disturbance of the logit model has standard logistic distribution with the CDF
![\[ \Lambda (x)=\frac{\exp (x)}{1+\exp (x)} = \frac{1}{1+\exp (-x)} \]](images/etsug_qlim0056.png)
The binary discrete choice model has the following probability that the event 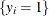 occurs:
occurs:
![\[ P(y_{i}=1) = F(\mathbf{x}_{i}’\bbeta ) = \left\{ \begin{array}{ll} \Phi (\mathbf{x}_{i}’\bbeta ) & \mr{(probit)} \\ \Lambda (\mathbf{x}_{i}’\bbeta ) & \mr{(logit)} \end{array} \right. \]](images/etsug_qlim0058.png)
The log-likelihood function is
![\[ \ell = \sum _{i=1}^{N}\left\{ y_{i}\log [F(\mathbf{x}_{i}’\bbeta )] + (1-y_{i})\log [1-F(\mathbf{x}_{i}’\bbeta )]\right\} \]](images/etsug_qlim0059.png)
where the CDF 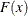 is defined as
is defined as 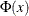 for the probit model while
for the probit model while 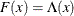 for logit. The first order derivatives of the logit model are
for logit. The first order derivatives of the logit model are
![\[ \frac{\partial \ell }{\partial \bbeta } = \sum _{i=1}^{N}(y_{i}- \Lambda (\mathbf{x}_{i}’\bbeta ))\mathbf{x}_{i} \]](images/etsug_qlim0063.png)
The probit model has more complicated derivatives
![\[ \frac{\partial \ell }{\partial \bbeta } = \sum _{i=1}^{N} \left\{ \frac{(2y_{i} - 1)\phi \left[(2y_{i} - 1)\mathbf{x}_{i}'\bbeta \right]}{\Phi \left[(2y_{i} - 1)\mathbf{x}_{i}'\bbeta \right]}\right\} \mathbf{x}_{i} = \sum _{i=1}^{N}r_{i} \mathbf{x}_{i} \]](images/etsug_qlim0064.png)
where
![\[ r_{i} = \frac{(2y_{i} - 1)\phi \left[(2y_{i} - 1)\mathbf{x}_{i}'\bbeta \right]}{\Phi \left[(2y_{i} - 1)\mathbf{x}_{i}'\bbeta \right]} \]](images/etsug_qlim0065.png)
Note that the logit maximum likelihood estimates are 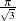 times greater than probit maximum likelihood estimates, since the probit parameter estimates,
times greater than probit maximum likelihood estimates, since the probit parameter estimates, 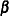 , are standardized, and the error term with logistic distribution has a variance of
, are standardized, and the error term with logistic distribution has a variance of 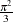 .
.
Ordinal Probit/Logit
When the dependent variable is observed in sequence with M categories, binary discrete choice modeling is not appropriate for data analysis. McKelvey and Zavoina (1975) proposed the ordinal (or ordered) probit model.
Consider the following regression equation:
![\[ y_{i}^{*} = \mathbf{x}_{i}’\bbeta + \epsilon _{i} \]](images/etsug_qlim0069.png)
where error disturbances, , have the distribution function F. The unobserved continuous random variable, 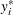 , is identified as M categories. Suppose there are
, is identified as M categories. Suppose there are 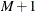 real numbers,
real numbers, 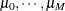 , where
, where 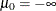 ,
, 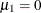 ,
, 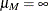 , and
, and 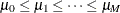 . Define
. Define
![\[ R_{i,j} = \mu _{j} - \mathbf{x}_{i}’\bbeta \]](images/etsug_qlim0077.png)
The probability that the unobserved dependent variable is contained in the jth category can be written as
![\[ P[\mu _{j-1}< y_{i}^{*} \leq \mu _{j}] = F(R_{i,j}) - F(R_{i,j-1}) \]](images/etsug_qlim0078.png)
The log-likelihood function is
![\[ \ell = \sum _{i=1}^{N}\sum _{j=1}^{M}d_{ij}\log \left[F(R_{i,j}) - F(R_{i,j-1})\right] \]](images/etsug_qlim0079.png)
where
![\[ d_{ij} = \left\{ \begin{array}{cl} 1& \mr{if} \mu _{j-1}< y_{i} \leq \mu _{j} \\ 0& \mr{otherwise} \end{array} \right. \]](images/etsug_qlim0080.png)
The first derivatives are written as
![\[ \frac{\partial \ell }{\partial \bbeta } = \sum _{i=1}^{N}\sum _{j=1}^{M} d_{ij}\left[\frac{f(R_{i,j-1}) - f(R_{i,j})}{F(R_{i,j})-F(R_{i,j-1})} \mathbf{x}_{i}\right] \]](images/etsug_qlim0081.png)
![\[ \frac{\partial \ell }{\partial \mu _{k}} = \sum _{i=1}^{N}\sum _{j=1}^{M} d_{ij}\left[\frac{\delta _{j,k}f(R_{i,j}) - \delta _{j-1,k}f(R_{i,j-1})}{F(R_{i,j})-F(R_{i,j-1})}\right] \]](images/etsug_qlim0082.png)
where 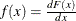 and
and 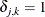 if
if 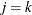 , and
, and 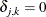 otherwise. When the ordinal probit is estimated, it is assumed that
otherwise. When the ordinal probit is estimated, it is assumed that 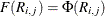 . The ordinal logit model is estimated if
. The ordinal logit model is estimated if 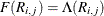 . The first threshold parameter,
. The first threshold parameter, 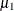 , is estimated when the LIMIT1=VARYING option is specified. By default (LIMIT1=ZERO), so that
, is estimated when the LIMIT1=VARYING option is specified. By default (LIMIT1=ZERO), so that 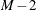 threshold parameters (
threshold parameters (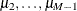 ) are estimated.
) are estimated.
The ordered probit models are analyzed by Aitchison and Silvey (1957), and Cox (1970) discussed ordered response data by using the logit model. They defined the probability that belongs to jth category as
![\[ P[\mu _{j-1}< y_{i} \leq \mu _{j}] = F(\mu _{j}+\mathbf{x}_{i}’\btheta ) - F(\mu _{j-1}+\mathbf{x}_{i}’\btheta ) \]](images/etsug_qlim0092.png)
where and . Therefore, the ordered response model analyzed by Aitchison and Silvey can be estimated if the LIMIT1=VARYING option is
specified. Note that 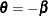 .
.
Goodness-of-Fit Measures
The goodness-of-fit measures discussed in this section apply only to discrete dependent variable models.
McFadden (1974) suggested a likelihood ratio index that is analogous to the 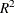 in the linear regression model:
in the linear regression model:
![\[ R^{2}_{M} = 1 - \frac{\ln L}{\ln L_{0}} \]](images/etsug_qlim0095.png)
where L is the value of the maximum likelihood function and 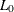 is the value of a likelihood function when regression coefficients except an intercept term are zero. It can be shown that
can be written as
is the value of a likelihood function when regression coefficients except an intercept term are zero. It can be shown that
can be written as
![\[ L_{0} = \sum _{j=1}^{M} N_{j} \ln (\frac{N_{j}}{N} ) \]](images/etsug_qlim0097.png)
where 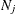 is the number of responses in category j.
is the number of responses in category j.
Estrella (1998) proposes the following requirements for a goodness-of-fit measure to be desirable in discrete choice modeling:
-
The measure must take values in
![$[0,1]$](images/etsug_qlim0099.png) , where 0 represents no fit and 1 corresponds to perfect fit.
, where 0 represents no fit and 1 corresponds to perfect fit.
-
The measure should be directly related to the valid test statistic for significance of all slope coefficients.
-
The derivative of the measure with respect to the test statistic should comply with corresponding derivatives in a linear regression.
Estrella’s (1998) measure is written
![\[ R_{E1}^{2} = 1 - \left(\frac{\ln L}{\ln L_{0}}\right) ^{-\frac{2}{N}\ln L_{0}} \]](images/etsug_qlim0100.png)
An alternative measure suggested by Estrella (1998) is
![\[ R_{E2}^{2} = 1 - [ (\ln L - K) / \ln L_{0} ]^{-\frac{2}{N}\ln L_{0}} \]](images/etsug_qlim0101.png)
where 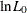 is computed with null slope parameter values, N is the number observations used, and K represents the number of estimated parameters.
is computed with null slope parameter values, N is the number observations used, and K represents the number of estimated parameters.
Other goodness-of-fit measures are summarized as follows:
![\[ R_{CU1}^{2} = 1 - \left(\frac{L_{0}}{L}\right)^{\frac{2}{N}} \; \; (\mr{Cragg-Uhler 1}) \]](images/etsug_qlim0103.png)
![\[ R_{CU2}^{2} = \frac{1 - (L_{0}/L)^{\frac{2}{N}}}{1 - L_{0}^{\frac{2}{N}}} \; \; (\mr{Cragg-Uhler 2}) \]](images/etsug_qlim0104.png)
![\[ R_{A}^{2} = \frac{2(\ln L - \ln L_{0})}{2(\ln L - \ln L_{0})+N} \; \; (\mr{Aldrich-Nelson}) \]](images/etsug_qlim0105.png)
![\[ R_{VZ}^{2} = R_{A}^{2}\frac{2\ln L_{0} - N}{2\ln L_{0}} \; \; (\mr{Veall-Zimmermann}) \]](images/etsug_qlim0106.png)
![\[ R_{MZ}^{2} = \frac{\sum _{i=1}^{N}(\hat{y}_{i} - \bar{\hat{y_{i}}})^{2}}{N +\sum _{i=1}^{N}(\hat{y}_{i} - \bar{\hat{y_{i}}})^{2}} \; \; (\mr{McKelvey-Zavoina}) \]](images/etsug_qlim0107.png)
where 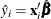 and
and 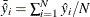 .
.