The HPSEVERITY Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsPredefined DistributionsCensoring and TruncationParameter Estimation MethodDetails of Optimization AlgorithmsParameter InitializationEstimating Regression EffectsEmpirical Distribution Function Estimation MethodsStatistics of FitDistributed and Multithreaded ComputationDefining a Severity Distribution Model with the FCMP ProcedurePredefined Utility FunctionsScoring FunctionsCustom Objective FunctionsInput Data SetsOutput Data SetsDisplayed Output
-
ExamplesDefining a Model for Gaussian DistributionDefining a Model for the Gaussian Distribution with a Scale ParameterDefining a Model for Mixed-Tail DistributionsFitting a Scaled Tweedie Model with RegressorsFitting Distributions to Interval-Censored DataBenefits of Distributed and Multithreaded ComputingEstimating Parameters Using Cramér-von Mises EstimatorDefining a Finite Mixture Model That Has a Scale ParameterPredicting Mean and Value-at-Risk by Using Scoring Functions
- References
NLOPTIONS options ;
The HPSEVERITY procedure uses the nonlinear optimization (NLO) subsystem to perform nonlinear optimization of the likelihood function to obtain the estimates of distribution and regression parameters. You can use the NLOPTIONS statement to control different aspects of this optimization process. If you specify more than one NLOPTIONS statement, then the first statement is used.
For most problems, the default settings of the optimization process are adequate. However, in some cases it might be useful to change the optimization technique or to change the maximum number of iterations. The following statement uses the MAXITER= option to set the maximum number of iterations to 200 and uses the TECH= option to change the optimization technique to the double-dogleg optimization (DBLDOG) rather than the default technique, the trust region optimization (TRUREG), used in the HPSEVERITY procedure:
nloptions tech=dbldog maxiter=200;
The following options values can be used in the NLOPTIONS statement:
-
ABSCONV=r
ABSTOL=r -
specifies an absolute function value convergence criterion. For minimization, termination requires
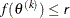 . The default value of r is the negative square root of the largest double-precision value, which serves only as a protection against overflows.
. The default value of r is the negative square root of the largest double-precision value, which serves only as a protection against overflows.
-
ABSFCONV=r
ABSFTOL=r -
specifies an absolute function difference convergence criterion. For all techniques except NMSIMP, termination requires a small change of the function value in successive iterations:
![\[ |f(\theta ^{(k-1)}) - f(\theta ^{(k)})| \leq \Argument{r} \]](images/etshpug_hpseverity0045.png)
The same formula is used for the NMSIMP technique, but
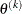 is defined as the vertex with the lowest function value, and
is defined as the vertex with the lowest function value, and 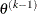 is defined as the vertex with the highest function value in the simplex. The default value is
is defined as the vertex with the highest function value in the simplex. The default value is 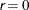 .
.
-
ABSGCONV=r
ABSGTOL=r -
specifies an absolute gradient convergence criterion. Termination requires the maximum absolute gradient element to be small:
![\[ \max _ j |g_ j(\theta ^{(k)})| \leq \Argument{r} \]](images/etshpug_hpseverity0049.png)
This criterion is not used by the NMSIMP technique. The default value is r=1E–5.
-
ABSXCONV=r
ABSXTOL=r -
specifies an absolute parameter convergence criterion. For all techniques except NMSIMP, termination requires a small Euclidean distance between successive parameter vectors,
![\[ \parallel \theta ^{(k)} - \theta ^{(k-1)} \parallel _2 \leq \Argument{r} \]](images/etshpug_hpseverity0050.png)
For the NMSIMP technique, termination requires either a small length
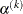 of the vertices of a restart simplex,
of the vertices of a restart simplex,
![\[ \alpha ^{(k)} \leq \Argument{r} \]](images/etshpug_hpseverity0052.png)
or a small simplex size,
![\[ \delta ^{(k)} \leq \Argument{r} \]](images/etshpug_hpseverity0053.png)
where the simplex size
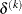 is defined as the L1 distance from the simplex vertex
is defined as the L1 distance from the simplex vertex 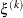 with the smallest function value to the other simplex points
with the smallest function value to the other simplex points 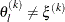 :
:
![\[ \delta ^{(k)} = \sum \parallel \theta _ l^{(k)} - \xi ^{(k)}\parallel _1 \]](images/etshpug_hpseverity0057.png)
The default is r=1E–8 for the NMSIMP technique and
otherwise.
-
FCONV=r
FTOL=r -
specifies a relative function convergence criterion. For all techniques except NMSIMP, termination requires a small relative change of the function value in successive iterations,
![\[ { \frac{ |f(\theta ^{(k)}) - f(\theta ^{(k-1)})|}{\max (|f(\theta ^{(k-1)})|,\mbox{FSIZE})} } \leq \Argument{r} \]](images/etshpug_hpseverity0058.png)
where FSIZE is defined by the FSIZE= option. The same formula is used for the NMSIMP technique, but
is defined as the vertex with the lowest function value, and is defined as the vertex with the highest function value in the simplex.
The default value is
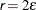 , where
, where  denotes the machine precision constant, which is the smallest double-precision floating-point number such that
denotes the machine precision constant, which is the smallest double-precision floating-point number such that 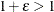 .
.
-
FCONV2=r
FTOL2=r -
specifies another function convergence criterion.
For all techniques except NMSIMP, termination requires a small predicted reduction of the objective function:
![\[ df^{(k)} \approx f(\theta ^{(k)}) - f(\theta ^{(k)} + s^{(k)}) \]](images/etshpug_hpseverity0062.png)
The predicted reduction
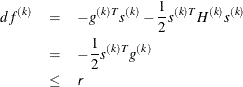
is computed by approximating the objective function
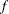 by the first two terms of the Taylor series and substituting the Newton step
by the first two terms of the Taylor series and substituting the Newton step
![\[ s^{(k)} = - [H^{(k)}]^{-1} g^{(k)} \]](images/etshpug_hpseverity0064.png)
For the NMSIMP technique, termination requires a small standard deviation of the function values of the
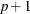 simplex vertices
simplex vertices 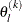 ,
, 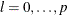 ,
, ![$ \sqrt { \frac{1}{p+1} \sum _ l \left[ f(\theta _ l^{(k)}) - \overline{f}(\theta ^{(k)}) \right]^2 } \leq \Argument{r} $](images/etshpug_hpseverity0068.png) where
where 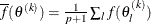 . If there are
. If there are 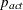 boundary constraints active at , the mean and standard deviation are computed only for the
boundary constraints active at , the mean and standard deviation are computed only for the 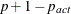 unconstrained vertices.
unconstrained vertices.
The default value is r=1E–6 for the NMSIMP technique and
otherwise.
- FSIZE=r
-
specifies the FSIZE parameter of the relative function and relative gradient termination criteria. The default value is r
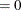 . For more information, see the FCONV= and GCONV= options.
. For more information, see the FCONV= and GCONV= options.
-
GCONV=r
GTOL=r -
specifies a relative gradient convergence criterion. For all techniques except CONGRA and NMSIMP, termination requires that the normalized predicted function reduction is small,
![\[ \frac{ g(\theta ^{(k)})^ T [H^{(k)}]^{-1} g(\theta ^{(k)})}{\max (|f(\theta ^{(k)})|,\mbox{FSIZE}) } \leq \Argument{r} \]](images/etshpug_hpseverity0073.png)
where FSIZE is defined by the FSIZE= option. For the CONGRA technique (where a reliable Hessian estimate
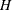 is not available), the following criterion is used:
is not available), the following criterion is used:
![\[ \frac{ \parallel g(\theta ^{(k)}) \parallel _2^2 \quad \parallel s(\theta ^{(k)}) \parallel _2}{\parallel g(\theta ^{(k)}) - g(\theta ^{(k-1)}) \parallel _2 \max (|f(\theta ^{(k)})|,\mbox{FSIZE}) } \leq \Argument{r} \]](images/etshpug_hpseverity0075.png)
This criterion is not used by the NMSIMP technique. The default value is
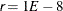 .
.
-
MAXFUNC=i
MAXFU=i -
specifies the maximum number i of function calls in the optimization process. The default values are
-
TRUREG, NRRIDG, NEWRAP: 125
-
QUANEW, DBLDOG: 500
-
CONGRA: 1000
-
NMSIMP: 3000
Note that the optimization can terminate only after completing a full iteration. Therefore, the number of function calls that is actually performed can exceed the number that you specify by the MAXFUNC= option.
-
-
MAXITER=i
MAXIT=i -
specifies the maximum number i of iterations in the optimization process. The default values are
-
TRUREG, NRRIDG, NEWRAP: 50
-
QUANEW, DBLDOG: 200
-
CONGRA: 400
-
NMSIMP: 1000
These default values are also valid when you specify a missing value for i.
-
- MAXTIME=r
-
specifies an upper limit of r seconds of CPU time for the optimization process. The default value is the largest floating-point double representation of your computer. The time that you specify in the MAXTIME= option is checked only once at the end of each iteration. Therefore, the actual running time can be much longer than that you specify by the MAXTIME= option. The actual running time includes the rest of the time needed to finish the iteration and the time needed to generate the output of the results.
-
MINITER=i
MINIT=i -
specifies the minimum number of iterations. The default value is 0. If you request more iterations than are actually needed for convergence to a stationary point, the optimization algorithms can behave strangely. For example, the effect of rounding errors can prevent the algorithm from continuing for the required number of iterations.
-
TECHNIQUE=name
TECH=name -
specifies the optimization technique. Valid values for name are as follows:
- CONGRA
-
performs a conjugate-gradient optimization.
- DBLDOG
-
performs a version of double-dogleg optimization.
- NMSIMP
-
performs a Nelder-Mead simplex optimization.
- NONE
-
does not perform any optimization. This option can be used as follows:
-
to perform a grid search without optimization
-
to compute estimates and predictions that cannot be obtained efficiently with any of the optimization techniques
-
- NEWRAP
-
performs a Newton-Raphson optimization that combines a line-search algorithm with ridging.
- NRRIDG
-
performs a Newton-Raphson optimization with ridging.
- QUANEW
-
performs a quasi-Newton optimization.
- TRUREG
-
performs a trust region optimization. This is the default estimation method.
For more information about optimization algorithms, see the section Details of Optimization Algorithms.
-
XCONV=r
XTOL=r -
specifies the relative parameter convergence criterion. For all techniques except NMSIMP, termination requires a small relative parameter change in subsequent iterations:
![\[ \frac{\max _ j |\theta _ j^{(k)} - \theta _ j^{(k-1)}|}{\max (|\theta _ j^{(k)}|,|\theta _ j^{(k-1)}|,\mbox{XSIZE})} \leq \Argument{r} \]](images/etshpug_hpseverity0077.png)
For the NMSIMP technique, the same formula is used, but
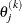 is defined as the vertex that has the lowest function value and
is defined as the vertex that has the lowest function value and 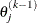 is defined as the vertex that has the highest function value in the simplex. The default value is r=1E–8 for the NMSIMP technique and otherwise.
is defined as the vertex that has the highest function value in the simplex. The default value is r=1E–8 for the NMSIMP technique and otherwise.
- XSIZE=r
-
specifies the XSIZE parameter of the relative parameter termination criterion. The value of r must be greater than or equal to 0; the default is
. For more information, see the XCONV= option.