The HPSEVERITY Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsPredefined DistributionsCensoring and TruncationParameter Estimation MethodDetails of Optimization AlgorithmsParameter InitializationEstimating Regression EffectsEmpirical Distribution Function Estimation MethodsStatistics of FitDistributed and Multithreaded ComputationDefining a Severity Distribution Model with the FCMP ProcedurePredefined Utility FunctionsScoring FunctionsCustom Objective FunctionsInput Data SetsOutput Data SetsDisplayed Output
-
ExamplesDefining a Model for Gaussian DistributionDefining a Model for the Gaussian Distribution with a Scale ParameterDefining a Model for Mixed-Tail DistributionsFitting a Scaled Tweedie Model with RegressorsFitting Distributions to Interval-Censored DataBenefits of Distributed and Multithreaded ComputingEstimating Parameters Using Cramér-von Mises EstimatorDefining a Finite Mixture Model That Has a Scale ParameterPredicting Mean and Value-at-Risk by Using Scoring Functions
- References
The HPSEVERITY procedure enables you to estimate the effects of regressor (exogenous) variables while fitting a distribution if the distribution has a scale parameter or a log-transformed scale parameter.
Let ![]() ,
, ![]() , denote the
, denote the ![]() regressor variables. Let
regressor variables. Let ![]() denote the regression parameter that corresponds to the regressor
denote the regression parameter that corresponds to the regressor ![]() . If you do not specify regression effects, then the model for the response variable
. If you do not specify regression effects, then the model for the response variable ![]() is of the form
is of the form
where ![]() is the distribution of
is the distribution of ![]() with parameters
with parameters ![]() . This model is usually referred to as the error model. The regression effects are modeled by extending the error model to
the following form:
. This model is usually referred to as the error model. The regression effects are modeled by extending the error model to
the following form:
Under this model, the distribution of ![]() is valid and belongs to the same parametric family as
is valid and belongs to the same parametric family as ![]() if and only if
if and only if ![]() has a scale parameter. Let
has a scale parameter. Let ![]() denote the scale parameter and
denote the scale parameter and ![]() denote the set of nonscale distribution parameters of
denote the set of nonscale distribution parameters of ![]() . Then the model can be rewritten as
. Then the model can be rewritten as
such that ![]() is modeled by the regressors as
is modeled by the regressors as
where ![]() is the base value of the scale parameter. Thus, the scale regression model consists of the following parameters:
is the base value of the scale parameter. Thus, the scale regression model consists of the following parameters: ![]() ,
, ![]() , and
, and ![]() .
.
Given this form of the model, distributions without a scale parameter cannot be considered when regression effects are to
be modeled. If a distribution does not have a direct scale parameter, then PROC HPSEVERITY accepts it only if it has a log-transformed
scale parameter — that is, if it has a parameter ![]() .
.
You can specify that an offset variable be included in the scale regression model by specifying it in the OFFSET= option of the SCALEMODEL statement. The offset variable is a regressor whose regression coefficient is known to be 1. If
![]() denotes the offset variable, then the scale regression model becomes
denotes the offset variable, then the scale regression model becomes
The regression coefficient of the offset variable is fixed at 1 and not estimated, so it is not reported in the ParameterEstimates ODS table. However, if you specify the OUTEST= data set, then the regression coefficient is added as a variable to that data set. The value of the offset variable in OUTEST= data set is equal to 1 for the estimates row (_TYPE_='EST') and is equal to a special missing value (.F) for the standard error (_TYPE_='STDERR') and covariance (_TYPE_='COV') rows.
An offset variable is useful to model the scale parameter per unit of some measure of exposure. For example, in the automobile
insurance context, measure of exposure can be the number of car-years insured or the total number of miles driven by a fleet
of cars at a rental car company. For worker’s compensation insurance, if you want to model the expected loss per enterprise,
then you can use the number of employees or total employee salary as the measure of exposure. For epidemiological data, measure
of exposure can be the number of people who are exposed to a certain pathogen when you are modeling the loss associated with
an epidemic. In general, if ![]() denotes the value of the exposure measure and if you specify
denotes the value of the exposure measure and if you specify ![]() as the offset variable, then you are modeling the effect of other regressors (
as the offset variable, then you are modeling the effect of other regressors (![]() ) on the size of the scale of the distribution per unit of exposure.
) on the size of the scale of the distribution per unit of exposure.
Another use for an offset variable is when you have a priori knowledge of the effect of some exogenous variables that cannot be included in the SCALEMODEL statement. You can model the combined effect of such variables as an offset variable in order to correct for the omitted variable bias.
The regression parameters are initialized either by using the values that you specify or by the default method.
-
If you provide initial values for the regression parameters, then you must provide valid, nonmissing initial values for
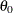 and
and 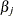 parameters for all
parameters for all 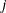 .
.
You can specify the initial value for
by using either the INEST= data set or the INIT= option in the DIST statement. If the distribution has a direct scale parameter
(no transformation), then the initial value for the first parameter of the distribution is used as an initial value for . If the distribution has a log-transformed scale parameter, then the initial value for the first parameter of the distribution
is used as an initial value for 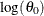 .
.
You can use only the INEST= data set to specify the initial values for
. The INEST= data set must contain nonmissing initial values for all the regressors that you specify in the SCALEMODEL statement.
The only missing value allowed is the special missing value .R, which indicates that the regressor is linearly dependent on
other regressors. If you specify .R for a regressor for one distribution in a BY group, you must specify it so for all the
distributions in that BY group.
-
If you do not specify valid initial values for
or parameters for all , then PROC HPSEVERITY initializes those parameters by using the following method:
Let a random variable
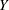 be distributed as
be distributed as 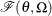 , where
, where 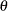 is the scale parameter. By the definition of the scale parameter, a random variable
is the scale parameter. By the definition of the scale parameter, a random variable 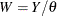 is distributed as
is distributed as 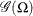 such that
such that 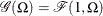 . Given a random error term
. Given a random error term  that is generated from a distribution , a value
that is generated from a distribution , a value 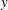 from the distribution of can be generated as
from the distribution of can be generated as
![\[ y = \theta \cdot e \]](images/etshpug_hpseverity0351.png)
Taking the logarithm of both sides and using the relationship of
with the regressors yields:
![\[ \log (y) = \log (\theta _0) + \sum _{j=1}^{k} \beta _ j x_ j + \log (e) \]](images/etshpug_hpseverity0352.png)
PROC HPSEVERITY makes use of the preceding relationship to initialize parameters of a regression model with distribution dist as follows:
-
The following linear regression problem is solved to obtain initial estimates of
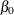 and :
and :
![\[ \log (y) = \beta _0 + \sum _{j=1}^{k} \beta _ j x_ j \]](images/etshpug_hpseverity0354.png)
The estimates of
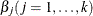 in the solution of this regression problem are used to initialize the respective regression parameters of the model. The
estimate of is later used to initialize the value of .
in the solution of this regression problem are used to initialize the respective regression parameters of the model. The
estimate of is later used to initialize the value of .
The results of this regression are also used to detect whether any regressors are linearly dependent on the other regressors. If any such regressors are found, then a warning is written to the SAS log and the corresponding regressor is eliminated from further analysis. The estimates for linearly dependent regressors are denoted by a special missing value of .R in the OUTEST= data set and in any displayed output.
-
Let
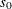 denote the initial value of the scale parameter.
denote the initial value of the scale parameter.
If the distribution model of dist does not contain the dist_PARMINIT subroutine, then
and all the nonscale distribution parameters are initialized to the default value of 0.001.
However, it is strongly recommended that each distribution’s model contain the dist_PARMINIT subroutine. For more information, see the section Defining a Severity Distribution Model with the FCMP Procedure. If that subroutine is defined, then
is initialized as follows:
Each input value
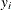 of the response variable is transformed to its scale-normalized version
of the response variable is transformed to its scale-normalized version 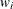 as
as
![\[ w_ i = \frac{y_ i}{\exp (\beta _0 + \sum _{j=1}^{k} \beta _ j x_{ij})} \]](images/etshpug_hpseverity0357.png)
where
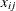 denotes the value of th regressor in the
denotes the value of th regressor in the 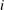 th input observation. These values are used to compute the input arguments for the dist_PARMINIT subroutine. The values that are computed by the subroutine for nonscale parameters are used as their respective
initial values. If the distribution has an untransformed scale parameter, then is set to the value of the scale parameter that is computed by the subroutine. If the distribution has a log-transformed
scale parameter
th input observation. These values are used to compute the input arguments for the dist_PARMINIT subroutine. The values that are computed by the subroutine for nonscale parameters are used as their respective
initial values. If the distribution has an untransformed scale parameter, then is set to the value of the scale parameter that is computed by the subroutine. If the distribution has a log-transformed
scale parameter 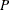 , then is computed as
, then is computed as 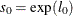 , where
, where 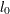 is the value of computed by the subroutine.
is the value of computed by the subroutine.
-
The value of
is initialized as
![\[ \theta _0 = s_0 \cdot \exp (\beta _0) \]](images/etshpug_hpseverity0362.png)
-
When you request estimates to be written to the output (either ODS displayed output or in the OUTEST= data set), the estimate
of the base value of the first distribution parameter is reported. If the first parameter is the log-transformed scale parameter,
then the estimate of ![]() is reported; otherwise, the estimate of
is reported; otherwise, the estimate of ![]() is reported. The transform of the first parameter of a distribution dist is controlled by the dist_SCALETRANSFORM function that is defined for it.
is reported. The transform of the first parameter of a distribution dist is controlled by the dist_SCALETRANSFORM function that is defined for it.
When regression effects are estimated, the estimate of the scale parameter depends on the values of the regressors and the estimates of the regression parameters. This dependency results in a potentially different distribution for each observation. PROC HPSEVERITY needs to compute the estimates of the cumulative distribution function (CDF) to compute the EDF-based statistics of fit that compare the nonparametric and parametric estimates of the distribution function. To make the CDF estimates comparable across distributions and comparable to the empirical distribution function (EDF), PROC HPSEVERITY computes the CDF estimates from a representative distribution. The representative distribution is a mixture of a certain number of distributions, where each distribution differs only in the value of the scale parameter. You can specify the number of distributions in the mixture and how their scale values are chosen by using the DFMIXTURE= option in the SCALEMODEL statement.
Let ![]() denote the number of observations used for EDF estimation,
denote the number of observations used for EDF estimation, ![]() denote the number of components in the mixture distribution,
denote the number of components in the mixture distribution, ![]() denote the scale parameter of the
denote the scale parameter of the ![]() th mixture component, and
th mixture component, and ![]() denote the weight associated with
denote the weight associated with ![]() th mixture component.
th mixture component.
Let ![]() denote the CDF of the
denote the CDF of the ![]() th component distribution, where
th component distribution, where ![]() denotes the set of estimates of all parameters of the distribution other than the scale parameter. Then, the CDF estimates,
denotes the set of estimates of all parameters of the distribution other than the scale parameter. Then, the CDF estimates,
![]() , of the mixture distribution at
, of the mixture distribution at ![]() are computed as
are computed as
where ![]() is the normalization factor (
is the normalization factor (![]() ). The
). The ![]() values are used for computing the EDF-based statistics of fit.
values are used for computing the EDF-based statistics of fit.
The scale values ![]() for the
for the ![]() mixture components are derived from the set
mixture components are derived from the set ![]() (
(![]() ) of
) of ![]() scale values, where
scale values, where ![]() denotes the estimate of the scale parameter due to observation
denotes the estimate of the scale parameter due to observation ![]() . It is computed as
. It is computed as
where ![]() is an estimate of the base value of the scale parameter,
is an estimate of the base value of the scale parameter, ![]() are the estimates of regression coefficients, and
are the estimates of regression coefficients, and ![]() is the value of regressor
is the value of regressor ![]() in observation
in observation ![]() .
.
Let ![]() denote the weight of observation
denote the weight of observation ![]() . If you specify the WEIGHT statement, then the weight is equal to the value of the specified weight variable for the corresponding
observation in the DATA= data set; otherwise, the weight is set to 1.
. If you specify the WEIGHT statement, then the weight is equal to the value of the specified weight variable for the corresponding
observation in the DATA= data set; otherwise, the weight is set to 1.
You can specify one of the following method-names in the DFMIXTURE= option in the SCALEMODEL statement to specify the method of choosing ![]() and the corresponding
and the corresponding ![]() and
and ![]() values:
values:
- FULL
-
In this method, there are as many mixture components as the number of observations that are used for estimation. In other words,
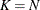 ,
, 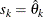 , and
, and 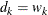 (
(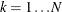 ). This is the slowest method, because it requires
). This is the slowest method, because it requires 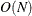 computations to compute the mixture CDF
computations to compute the mixture CDF 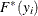 of one observation. For
of one observation. For 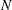 observations, the computational complexity in terms of number of CDF evaluations is
observations, the computational complexity in terms of number of CDF evaluations is 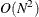 . Even for moderately large values of , the time taken to compute the mixture CDF can significantly exceed the time taken to estimate the model parameters. So,
it is recommended that you use the FULL method only for small data sets.
. Even for moderately large values of , the time taken to compute the mixture CDF can significantly exceed the time taken to estimate the model parameters. So,
it is recommended that you use the FULL method only for small data sets.
- MEAN
-
In this method, the mixture contains only one distribution, whose scale value is the mean of the scale values that are implied by all the observations. In other words,
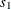 is computed as
is computed as
![\[ s_1 = \frac{1}{W} \sum _{i=1}^{N} w_ i \hat{\theta }_ i \]](images/etshpug_hpseverity0386.png)
where
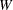 is the total weight (
is the total weight (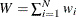 ).
).
This method is the fastest because it requires only one CDF evaluation per observation. The computational complexity is
for observations.
If you do not specify the DFMIXTURE= option in the SCALEMODEL statement, then this is the default method.
- QUANTILE
-
In this method, a certain number of quantiles are chosen from the set of all scale values. If you specify a value of
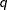 for the K= option when specifying this method, then
for the K= option when specifying this method, then 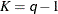 and
and 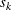 are set to be the
are set to be the 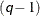 -quantiles from the set
-quantiles from the set 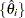 (
(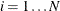 ). The weight of each of the components (
). The weight of each of the components (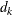 ) is assumed to be 1 for this method.
) is assumed to be 1 for this method.
The default value of
is 2, which implies a one-point mixture that has a distribution whose scale value is equal to the median scale value.
For this method, PROC HPSEVERITY needs to sort the
scale values in the set ; the sorting requires 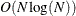 computations. Then, computing the mixture estimate of one observation requires CDF evaluations. Hence, the computational complexity of this method is
computations. Then, computing the mixture estimate of one observation requires CDF evaluations. Hence, the computational complexity of this method is 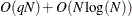 for computing a mixture CDF of observations. For
for computing a mixture CDF of observations. For 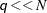 , the QUANTILE method is significantly faster than the FULL method.
, the QUANTILE method is significantly faster than the FULL method.
- RANDOM
-
In this method, a uniform random sample of observations is chosen, and the mixture contains the distributions that are implied by those observations. If you specify a value of
 for the K= option when specifying this method, then the size of the sample is . Hence,
for the K= option when specifying this method, then the size of the sample is . Hence, 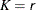 . If
. If 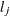 denotes the index of th observation in the sample (
denotes the index of th observation in the sample (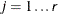 ), such that
), such that 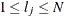 , then the scale of
, then the scale of 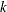 th component distribution in the mixture is
th component distribution in the mixture is 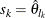 and the weight associated with it is
and the weight associated with it is 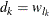 .
.
You can also specify the seed to be used for generating the random sample by using the SEED= option for this method. The same sample of observations is used for all models.
Computing a mixture estimate of one observation requires
CDF evaluations. Hence, the computational complexity of this method is 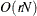 for computing a mixture CDF of observations. For
for computing a mixture CDF of observations. For 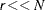 , the RANDOM method is significantly faster than the FULL method.
, the RANDOM method is significantly faster than the FULL method.