The HPSEVERITY Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsPredefined DistributionsCensoring and TruncationParameter Estimation MethodDetails of Optimization AlgorithmsParameter InitializationEstimating Regression EffectsEmpirical Distribution Function Estimation MethodsStatistics of FitDistributed and Multithreaded ComputationDefining a Severity Distribution Model with the FCMP ProcedurePredefined Utility FunctionsScoring FunctionsCustom Objective FunctionsInput Data SetsOutput Data SetsDisplayed Output
-
ExamplesDefining a Model for Gaussian DistributionDefining a Model for the Gaussian Distribution with a Scale ParameterDefining a Model for Mixed-Tail DistributionsFitting a Scaled Tweedie Model with RegressorsFitting Distributions to Interval-Censored DataBenefits of Distributed and Multithreaded ComputingEstimating Parameters Using Cramér-von Mises EstimatorDefining a Finite Mixture Model That Has a Scale ParameterPredicting Mean and Value-at-Risk by Using Scoring Functions
- References
You can use a series of programming statements that use variables in the DATA= data set to assign a value to an objective function symbol. You must specify the objective function symbol by using the OBJECTIVE= option in the PROC HPSEVERITY statement.
The objective function can be programmed such that it is applicable to any distribution that is used in the model. For that purpose, PROC HPSEVERITY recognizes the following keyword functions in the programming statements:
- _PDF_(x)
-
returns the probability density function (PDF) of a distribution evaluated at the current value of a data set variable
x. - _CDF_(x)
-
returns the cumulative distribution function (CDF) of a distribution evaluated at the current value of a data set variable
x. - _SDF_(x)
-
returns the survival distribution function (SDF) of a distribution evaluated at the current value of a data set variable
x. - _LOGPDF_(x)
-
returns the natural logarithm of the PDF of a distribution evaluated at the current value of a data set variable
x. - _LOGCDF_(x)
-
returns the natural logarithm of the CDF of a distribution evaluated at the current value of a data set variable
x. - _LOGSDF_(x)
-
returns the natural logarithm of the SDF of a distribution evaluated at the current value of a data set variable
x. - _EDF_(x)
-
returns the empirical distribution function (EDF) estimate evaluated at the current value of a data set variable
x. Internally, PROC HPSEVERITY computes the estimate using the SVRTUTIL_EDF function as described in the section Predefined Utility Functions. The EDF estimate that is required by the SVRTUTIL_EDF function is computed by using the response variable values in the current BY group or in the entire input data set if you do not specify the BY statement. - _EMPLIMMOMENT_(k, u)
-
returns the empirical limited moment of order
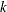 evaluated at the current value of a data set variable
evaluated at the current value of a data set variable uthat represents the upper limit of the limited moment. The order can also be a data set variable. Internally, PROC HPSEVERITY computes the moment using the SVRTUTIL_EMPLIMMOMENT function
as described in the section Predefined Utility Functions. The EDF estimate that is required by the SVRTUTIL_EMPLIMMOMENT function is computed by using the response variable values
in the current BY group or in the entire input data set if you do not specify the BY statement.
- _LIMMOMENT_(k, u)
-
returns the limited moment of order
evaluated at the current value of a data set variable uthat represents the upper limit of the limited moment. The order can be a data set variable or a constant. Internally, for each candidate distribution, PROC HPSEVERITY computes the moment
using the LIMMOMENT function as described in the section Predefined Utility Functions.
All the preceding functions are right-hand side functions. They act as placeholders for distribution-specific functions, with
the exception of _EDF_ and _EMPLIMMOMENT_ functions. As an example, let the data set Work.Test contain a response variable Y and a left-truncation threshold variable T. The following statements use the values in this data set to fit a model with distribution D such that the parameters of the model minimize the value of the objective function symbol MYOBJ:
options cmplib=(work.mydist);
proc hpseverity data=work.test objective=myobj;
loss y / lt=t;
myobj = -_LOGPDF_(y);
if (not(missing(t))) then
myobj = myobj + log(1-_CDF_(t));
dist d;
run;
The symbol MYOBJ is designated as an objective function symbol by using the OBJECTIVE= option in the PROC HPSEVERITY statement. The response variable Y and left-truncation variable T are specified in the LOSS statement. The distribution D is specified in the DIST statement. The remaining statements constitute a program that computes the value of the MYOBJ symbol.
Let the distribution D have parameters P1 and P2. In order to estimate the model for this distribution, PROC HPSEVERITY internally converts the generic program to the following
program specific to distribution D:
myobj = -D_LOGPDF(y, p1, p2);
if (not(missing(t))) then
myobj = myobj + log(1-D_CDF(t, p1, p2));
Note that the generic keyword functions _LOGPDF_ and _CDF_ have been replaced with distribution-specific functions D_LOGPDF
and D_CDF, respectively, with appropriate distribution parameters. The D_LOGPDF and D_CDF functions must have been defined
previously and are assumed to be available in the Work.Mydist library that you specify in the CMPLIB= option.
The program is executed for each observation in Work.Test to compute the value of MYOBJ by using the values of variables Y and T in that observation and internally computed values of the model parameters P1 and P2. The values of MYOBJ are then added over all the observations of the data set or over all the observations of the current BY group if you specify
the BY statement. The resulting aggregate value is the value of the objective function, and it is supplied to the optimizer.
If the optimizer requires derivatives of the objective function, then PROC HPSEVERITY automatically differentiates MYOBJ with respect to the parameters P1 and P2. The optimizer iterates over various combinations of the values of parameters P1 and P2, each time computing a new value of the objective function and the needed derivatives of it, until it finds a combination
that minimizes the objective function.
Note the following points when you define your own program to compute the custom objective function:
-
The value of the objective function is always minimized by PROC HPSEVERITY. If you want to maximize the value of a certain objective, then add a statement that assigns the negated value of the maximization objective to the objective function symbol that you specify in the OBJECTIVE= option. Minimization of the negated objective is equivalent to the maximization of the original objective.
-
The contributions of individual observations are always added to compute the overall objective function in a given iteration of the optimizer. If you specify the WEIGHT statement, then the contribution of each observation is weighted by multiplying it with the normalized value of the weight variable for that observation.
-
If you are fitting multiple distributions in one PROC HPSEVERITY step and use any of the keyword functions in your program, then it is recommended that you do not explicitly use the parameters of any of the specified distributions in your programming statements.
-
If you use a specific keyword function in your programming statements, then the corresponding distribution functions must be defined in a library that you specify in the CMPLIB= system option or in
Sashelp.Svrtdist, the predefined functions library. In the preceding example, it is assumed that the functions D_LOGPDF and D_CDF are defined in theWork.Mydistlibrary that is specified in the CMPLIB= option. -
You can use most DATA step statements and functions in your program. The DATA step file and the data set I/O statements (for example, INPUT, FILE, SET, and MERGE) are not available. However, some functionality of the PUT statement is supported. See the section “PROC FCMP and DATA Step Differences” in Base SAS Procedures Guide for more information. In addition to the differences listed in that section, the following differences exist:
-
Only numeric-valued variables can be used in PROC HPSEVERITY programming statements. This restriction also implies that you cannot use SAS functions or call routines that require character-valued arguments, unless you pass those arguments as constant (literal) strings or characters.
-
You cannot use functions that create lagged versions of a variable in PROC HPSEVERITY programming statements. If you need lagged versions, then you can use a DATA step prior to the PROC HPSEVERITY step to add those versions to the input data set.
-
-
When coding your programming statements, avoid defining variables that begin with an underscore (_), because they might conflict with internal variables created by PROC HPSEVERITY.
If you specify regressors by using the SCALEMODEL statement, then PROC HPSEVERITY automatically adds a statement prior to
your programming statements to compute the value of the scale parameter or the log-transformed scale parameter of the distribution
using the values of the regression variables and internally created regression parameters. For example, if you specify three
regressors x1, x2, and x3 in the SCALEMODEL statement, then for a model that contains the distribution D with scale parameter S, PROC HPSEVERITY prepends your program with a statement that is equivalent to the following statement:
S = _SEVTHETA0 * exp(_SEVBETA1 * x1 + _SEVBETA2 * x2 + _SEVBETA3 * x3);
If a model contains a distribution D1 with a log-transformed scale parameter M, PROC HPSEVERITY prepends your program with a statement that is equivalent to the following statement:
M = _SEVTHETA0 + _SEVBETA1 * x1 + _SEVBETA2 * x2 + _SEVBETA3 * x3;
The _SEVTHETA0, _SEVBETA1, _SEVBETA2, and _SEVBETA3 are the internal regression parameters associated with the intercept
and the regressors x1, x2, and x3, respectively.
Since the names of the internal regression parameters start with a prefix _SEV, if you use a variable in your program with a name that begins with _SEV, then PROC HPSEVERITY writes an error message to the SAS log and stops processing.