The HPSEVERITY Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsPredefined DistributionsCensoring and TruncationParameter Estimation MethodDetails of Optimization AlgorithmsParameter InitializationEstimating Regression EffectsEmpirical Distribution Function Estimation MethodsStatistics of FitDistributed and Multithreaded ComputationDefining a Severity Distribution Model with the FCMP ProcedurePredefined Utility FunctionsScoring FunctionsCustom Objective FunctionsInput Data SetsOutput Data SetsDisplayed Output
-
ExamplesDefining a Model for Gaussian DistributionDefining a Model for the Gaussian Distribution with a Scale ParameterDefining a Model for Mixed-Tail DistributionsFitting a Scaled Tweedie Model with RegressorsFitting Distributions to Interval-Censored DataBenefits of Distributed and Multithreaded ComputingEstimating Parameters Using Cramér-von Mises EstimatorDefining a Finite Mixture Model That Has a Scale ParameterPredicting Mean and Value-at-Risk by Using Scoring Functions
- References
PROC HPSEVERITY accepts DATA= and INEST= data sets as input data sets. This section details the information they are expected to contain.
The DATA= data set is expected to contain the values of the analysis variables that you specify in the LOSS statement and the SCALEMODEL statement.
If you specify the BY statement, then the DATA= data set must contain all the BY variables that you specify in the BY statement and the data set must be sorted by the BY variables unless you specify the NOTSORTED option in the BY statement.
The INEST= data set is expected to contain the initial values of the parameters for the parameter estimation process.
If you specify the BY statement, then the INEST= data set must contain all the BY variables that you specify in the BY statement. If you do not specify the NOTSORTED option in the BY statement, then the INEST= data set must be sorted by the BY variables. However, it is not required to contain all the BY groups present in the DATA= data set. For the BY groups that are not present in the INEST= data set, the default parameter initialization method is used. If you specify the NOTSORTED option in the BY statement, then the INEST= data set must contain all the BY groups that are present in the DATA= data set and they must appear in the same order as they appear in the DATA= data set.
In addition to any variables that you specify in the BY statement, the data set must contain the following variables:
- _MODEL_
-
identifying name of the distribution for which the estimates are provided.
- _TYPE_
-
type of the estimate. The value of this variable must be EST for an observation to be valid.
- <Parameter 1> …<Parameter M>
-
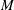 variables, named after the parameters of all candidate distributions, that contain initial values of the respective parameters.
is the cardinality of the union of parameter name sets from all candidate distributions. In an observation, estimates are
read only from variables for parameters that correspond to the distribution that is indicated by the _MODEL_ variable.
variables, named after the parameters of all candidate distributions, that contain initial values of the respective parameters.
is the cardinality of the union of parameter name sets from all candidate distributions. In an observation, estimates are
read only from variables for parameters that correspond to the distribution that is indicated by the _MODEL_ variable.
If you specify a missing value for some parameters, then default initial values are used unless the parameter is initialized by using the INIT= option in the DIST statement. If you want to use the dist_PARMINIT subroutine for initializing the parameters of a model, then you should either not specify the model in the INEST= data set or specify missing values for all the distribution parameters in the INEST= data set and not use the INIT= option in the DIST statement.
If you specify regressors, then the initial value that you provide for the first parameter of each distribution must be the base value of the scale or log-transformed scale parameter. For more information, see the section Estimating Regression Effects.
- <Regressor 1> …<Regressor K>
-
If you specify
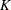 regressors in the SCALEMODEL statement, then the INEST= data set must contain variables that are named for each regressor. The variables contain initial values of the respective regression coefficients.
If a regressor is linearly dependent on other regressors for a given BY group, then you can indicate this by providing a special
missing value of .R for the respective variable. In a given BY group, if you mark a variable as linearly dependent for one
model, then you must mark that variable as linearly dependent for all the models. Similarly, in a given BY group, if you do
not mark a variable as linearly dependent for one model, then you must not mark that variable as linearly dependent for all
the models.
regressors in the SCALEMODEL statement, then the INEST= data set must contain variables that are named for each regressor. The variables contain initial values of the respective regression coefficients.
If a regressor is linearly dependent on other regressors for a given BY group, then you can indicate this by providing a special
missing value of .R for the respective variable. In a given BY group, if you mark a variable as linearly dependent for one
model, then you must mark that variable as linearly dependent for all the models. Similarly, in a given BY group, if you do
not mark a variable as linearly dependent for one model, then you must not mark that variable as linearly dependent for all
the models.